 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Hallucination for Few-shot Fine-grained Recognition
Paper and Code
Jun 14, 2018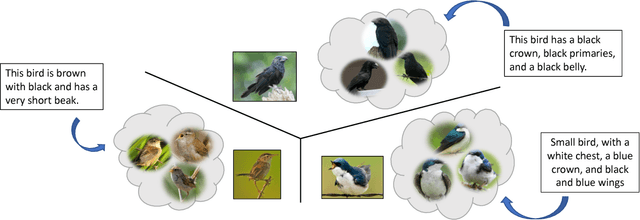

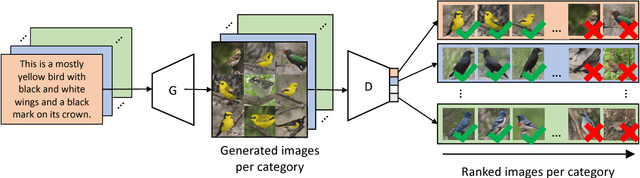
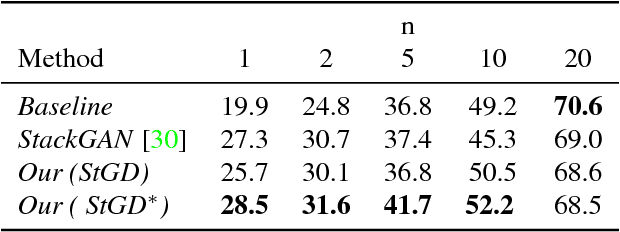
State-of-the-art deep learning algorithms generally require large amounts of data for model training. Lack thereof can severely deteriorate the performance, particularly in scenarios with fine-grained boundaries between categories. To this end, we propose a multimodal approach that facilitates bridging the information gap by means of meaningful joint embeddings. Specifically, we present a benchmark that is multimodal during training (i.e. images and texts) and single-modal in testing time (i.e. images), with the associated task to utilize multimodal data in base classes (with many samples), to learn explicit visual classifiers for novel classes (with few samples). Next, we propose a framework built upon the idea of cross-modal data hallucination. In this regard, we introduce a discriminative text-conditional GAN for sample generation with a simple self-paced strategy for sample selection. We show the results of our proposed discriminative hallucinated method for 1-, 2-, and 5- shot learning on the CUB dataset, where the accuracy is improved by employing multimodal data.