 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Variational Policies for Reward-Guided Diffusion
May 20, 2026Adapting pretrained diffusion models to downstream objectives such as inverse problems often requires expensive test-time guidance or optimization. We propose a principled framework for generating high-quality reward-aligned samples at substantially reduced inference cost. Our approach formulates test-time adaptation as a hierarchical variational model, where control is amortized into a lightweight yet expressive stochastic policy. This formulation naturally supports few-step diffusion sampling: large step sizes enable fast inference, while the learned policy maintains sample quality by providing structured per-step control. The resulting fully amortized sampler achieves a strong quality--speed tradeoff, matching or exceeding recent test-time scaling baselines while requiring significantly less compute. For example, on 4x super-resolution, our method achieves better perceptual quality with more than 5x faster inference compared to the best-performing baseline. We further extend our approach to a semi-amortized regime that combines cheap amortized proposals with limited test-time optimization, achieving state-of-the-art perceptual quality across several challenging inverse problems.
Skipping the Zeros in Diffusion Models for Sparse Data Generation
May 03, 2026Diffusion models (DMs) excel on dense continuous data, but are not designed for sparse continuous data. They do not model exact zeros that represent the deliberate absence of a signal. As a result, they erase sparsity patterns and perform unnecessary computation on mostly zero entries. With Sparsity-Exploiting Diffusion (SED), we model only non-zero values, preserving sparsity. SED delivers computational savings while maintaining or improving generation quality by skipping zeros during training and inference. Across physics and biology benchmarks, SED matches or surpasses conventional DMs and domain-specific baselines, while vision experiments provide intuitive insights into the limitations of dense DMs and the benefits of SED.
A Scale-Adaptive Framework for Joint Spatiotemporal Super-Resolution with Diffusion Models
Apr 23, 2026Deep-learning video super-resolution has progressed rapidly, but climate applications typically super-resolve (increase resolution) either space or time, and joint spatiotemporal models are often designed for a single pair of super-resolution (SR) factors (upscaling spatial and temporal ratio between the low-resolution sequence and the high-resolution sequence), limiting transfer across spatial resolutions and temporal cadences (frame rates). We present a scale-adaptive framework that reuses the same architecture across factors by decomposing spatiotemporal SR into a deterministic prediction of the conditional mean, with attention, and a residual conditional diffusion model, with an optional mass-conservation (same precipitation amount in inputs and outputs) transform to preserve aggregated totals. Assuming that larger SR factors primarily increase underdetermination (hence required context and residual uncertainty) rather than changing the conditional-mean structure, scale adaptivity is achieved by retuning three factor-dependent hyperparameters before retraining: the diffusion noise schedule amplitude beta (larger for larger factors to increase diversity), the temporal context length L (set to maintain comparable attention horizons across cadences) and optionally a third, the mass-conservation function f (tapered to limit the amplification of extremes for large factors). Demonstrated on reanalysis precipitation over France (Comephore), the same architecture spans super-resolution factors from 1 to 25 in space and 1 to 6 in time, yielding a reusable architecture and tuning recipe for joint spatiotemporal super-resolution across scales.
A Tale of Two Temperatures: Simple, Efficient, and Diverse Sampling from Diffusion Language Models
Apr 10, 2026Much work has been done on designing fast and accurate sampling for diffusion language models (dLLMs). However, these efforts have largely focused on the tradeoff between speed and quality of individual samples; how to additionally ensure diversity across samples remains less well understood. In this work, we show that diversity can be increased by using softened, tempered versions of familiar confidence-based remasking heuristics, retaining their computational benefits and offering simple implementations. We motivate this approach by introducing an idealized formal model of fork tokens and studying the impact of remasking on the expected entropy at the forks. Empirically, the proposed tempered heuristics close the exploration gap (pass@k) between existing confidence-based and autoregressive sampling, hence outperforming both when controlling for cost (pass@NFE). We further study how the increase in diversity translates to downstream post-training and test-time compute scaling. Overall, our findings demonstrate that simple, efficient, and diverse sampling from dLLMs is possible.
Region-Adaptive Generative Compression with Spatially Varying Diffusion Models
Apr 01, 2026Generative image codecs aim to optimize perceptual quality, producing realistic and detailed reconstructions. However, they often overlook a key property of human vision: our tendency to focus on particular aspects of a visual scene (e.g., salient objects) while giving less importance to other regions. An ideal perceptual codec should be able to exploit this property by allocating more representational capacity to perceptually important areas. To this end, we propose a region-adaptive diffusion-based image codec that supports non-uniform bit allocation within an image. We design a novel spatially varying diffusion model capable of denoising varying amounts of noise per pixel according to arbitrary importance maps. We further identify that these maps can serve as effective priors on the latent representation, and integrate them into our entropy model, improving rate-distortion performance. Built on these contributions, our spatially-adaptive diffusion-based codec outperforms state-of-the-art ROI-controllable baselines in both full-image and ROI-masked perceptual quality.
Calibrated Test-Time Guidance for Bayesian Inference
Feb 25, 2026Test-time guidance is a widely used mechanism for steering pretrained diffusion models toward outcomes specified by a reward function. Existing approaches, however, focus on maximizing reward rather than sampling from the true Bayesian posterior, leading to miscalibrated inference. In this work, we show that common test-time guidance methods do not recover the correct posterior distribution and identify the structural approximations responsible for this failure. We then propose consistent alternative estimators that enable calibrated sampling from the Bayesian posterior. We significantly outperform previous methods on a set of Bayesian inference tasks, and match state-of-the-art in black hole image reconstruction.
Advances in Diffusion-Based Generative Compression
Jan 26, 2026Popularized by their strong image generation performance, diffusion and related methods for generative modeling have found widespread success in visual media applications. In particular, diffusion methods have enabled new approaches to data compression, where realistic reconstructions can be generated at extremely low bit-rates. This article provides a unifying review of recent diffusion-based methods for generative lossy compression, with a focus on image compression. These methods generally encode the source into an embedding and employ a diffusion model to iteratively refine it in the decoding procedure, such that the final reconstruction approximately follows the ground truth data distribution. The embedding can take various forms and is typically transmitted via an auxiliary entropy model, and recent methods also explore the use of diffusion models themselves for information transmission via channel simulation. We review representative approaches through the lens of rate-distortion-perception theory, highlighting the role of common randomness and connections to inverse problems, and identify open challenges.
Parallel Token Prediction for Language Models
Dec 24, 2025We propose Parallel Token Prediction (PTP), a universal framework for parallel sequence generation in language models. PTP jointly predicts multiple dependent tokens in a single transformer call by incorporating the sampling procedure into the model. This reduces the latency bottleneck of autoregressive decoding, and avoids the restrictive independence assumptions common in existing multi-token prediction methods. We prove that PTP can represent arbitrary autoregressive sequence distributions. PTP is trained either by distilling an existing model or through inverse autoregressive training without a teacher. Experimentally, we achieve state-of-the-art speculative decoding performance on Vicuna-7B by accepting over four tokens per step on Spec-Bench. The universality of our framework indicates that parallel generation of long sequences is feasible without loss of modeling power.
UMAMI: Unifying Masked Autoregressive Models and Deterministic Rendering for View Synthesis
Dec 23, 2025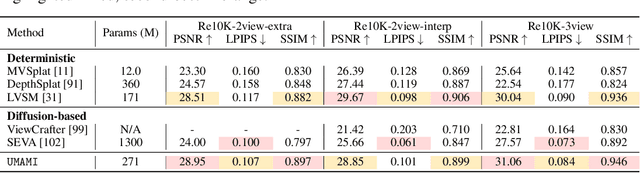
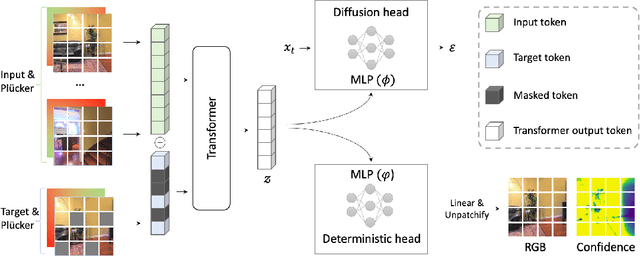
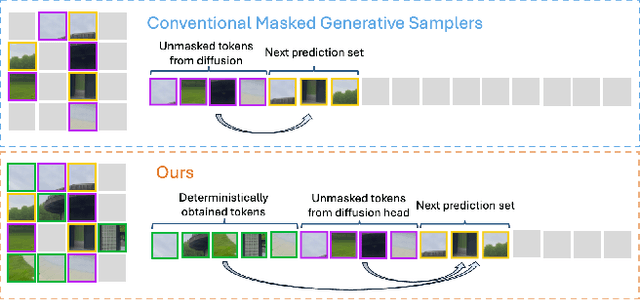

Novel view synthesis (NVS) seeks to render photorealistic, 3D-consistent images of a scene from unseen camera poses given only a sparse set of posed views. Existing deterministic networks render observed regions quickly but blur unobserved areas, whereas stochastic diffusion-based methods hallucinate plausible content yet incur heavy training- and inference-time costs. In this paper, we propose a hybrid framework that unifies the strengths of both paradigms. A bidirectional transformer encodes multi-view image tokens and Plucker-ray embeddings, producing a shared latent representation. Two lightweight heads then act on this representation: (i) a feed-forward regression head that renders pixels where geometry is well constrained, and (ii) a masked autoregressive diffusion head that completes occluded or unseen regions. The entire model is trained end-to-end with joint photometric and diffusion losses, without handcrafted 3D inductive biases, enabling scalability across diverse scenes. Experiments demonstrate that our method attains state-of-the-art image quality while reducing rendering time by an order of magnitude compared with fully generative baselines.
AstroCompress: A benchmark dataset for multi-purpose compression of astronomical data
Jun 10, 2025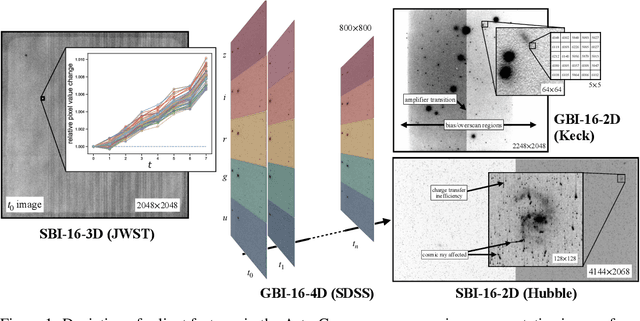
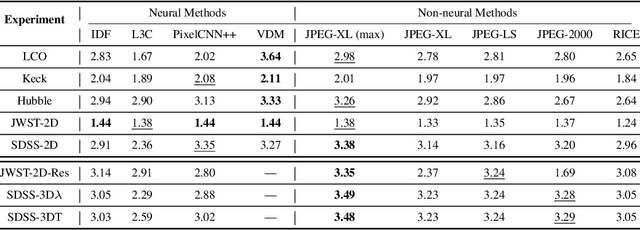
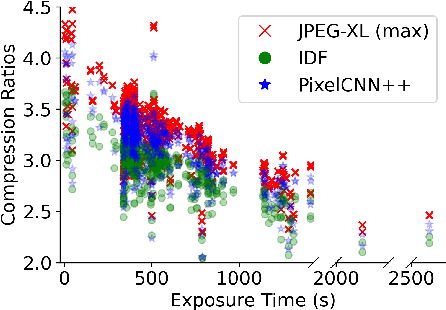
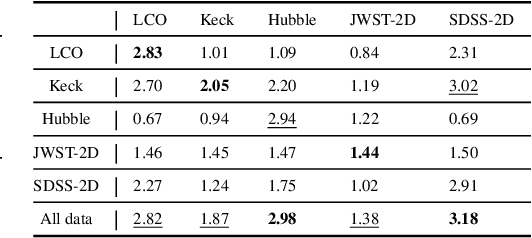
The site conditions that make astronomical observatories in space and on the ground so desirable -- cold and dark -- demand a physical remoteness that leads to limited data transmission capabilities. Such transmission limitations directly bottleneck the amount of data acquired and in an era of costly modern observatories, any improvements in lossless data compression has the potential scale to billions of dollars worth of additional science that can be accomplished on the same instrument. Traditional lossless methods for compressing astrophysical data are manually designed. Neural data compression, on the other hand, holds the promise of learning compression algorithms end-to-end from data and outperforming classical techniques by leveraging the unique spatial, temporal, and wavelength structures of astronomical images. This paper introduces AstroCompress: a neural compression challenge for astrophysics data, featuring four new datasets (and one legacy dataset) with 16-bit unsigned integer imaging data in various modes: space-based, ground-based, multi-wavelength, and time-series imaging. We provide code to easily access the data and benchmark seven lossless compression methods (three neural and four non-neural, including all practical state-of-the-art algorithms). Our results on lossless compression indicate that lossless neural compression techniques can enhance data collection at observatories, and provide guidance on the adoption of neural compression in scientific applications. Though the scope of this paper is restricted to lossless compression, we also comment on the potential exploration of lossy compression methods in future studies.