 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Semantic Chasm: Synergistic Conceptual Anchoring for Generalized Few-Shot and Zero-Shot OOD Perception
Jan 30, 2026This manuscript presents a pioneering Synergistic Neural Agents Network (SynerNet) framework designed to mitigate the phenomenon of cross-modal alignment degeneration in Vision-Language Models (VLMs) when encountering Out-of-Distribution (OOD) concepts. Specifically, four specialized computational units - visual perception, linguistic context, nominal embedding, and global coordination - collaboratively rectify modality disparities via a structured message-propagation protocol. The principal contributions encompass a multi-agent latent space nomenclature acquisition framework, a semantic context-interchange algorithm for enhanced few-shot adaptation, and an adaptive dynamic equilibrium mechanism. Empirical evaluations conducted on the VISTA-Beyond benchmark demonstrate that SynerNet yields substantial performance augmentations in both few-shot and zero-shot scenarios, exhibiting precision improvements ranging from 1.2% to 5.4% across a diverse array of domains.
UMAMI: Unifying Masked Autoregressive Models and Deterministic Rendering for View Synthesis
Dec 23, 2025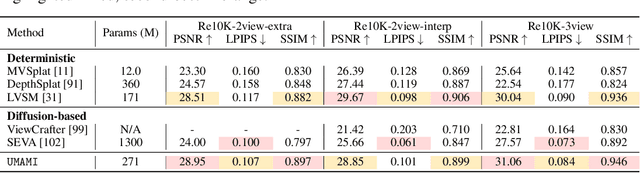
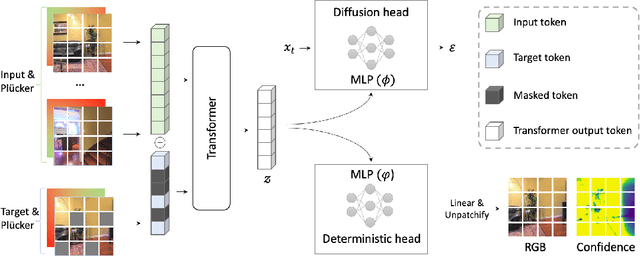
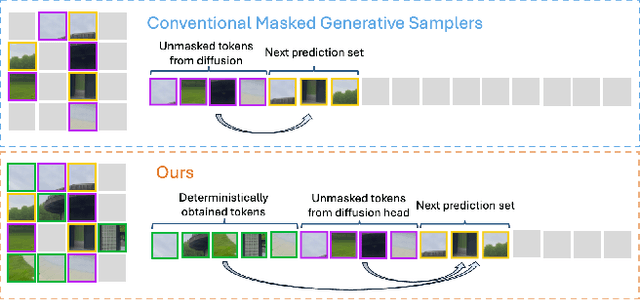

Novel view synthesis (NVS) seeks to render photorealistic, 3D-consistent images of a scene from unseen camera poses given only a sparse set of posed views. Existing deterministic networks render observed regions quickly but blur unobserved areas, whereas stochastic diffusion-based methods hallucinate plausible content yet incur heavy training- and inference-time costs. In this paper, we propose a hybrid framework that unifies the strengths of both paradigms. A bidirectional transformer encodes multi-view image tokens and Plucker-ray embeddings, producing a shared latent representation. Two lightweight heads then act on this representation: (i) a feed-forward regression head that renders pixels where geometry is well constrained, and (ii) a masked autoregressive diffusion head that completes occluded or unseen regions. The entire model is trained end-to-end with joint photometric and diffusion losses, without handcrafted 3D inductive biases, enabling scalability across diverse scenes. Experiments demonstrate that our method attains state-of-the-art image quality while reducing rendering time by an order of magnitude compared with fully generative baselines.
Convergence and Stability Analysis of Self-Consuming Generative Models with Heterogeneous Human Curation
Nov 13, 2025

Self-consuming generative models have received significant attention over the last few years. In this paper, we study a self-consuming generative model with heterogeneous preferences that is a generalization of the model in Ferbach et al. (2024). The model is retrained round by round using real data and its previous-round synthetic outputs. The asymptotic behavior of the retraining dynamics is investigated across four regimes using different techniques including the nonlinear Perron--Frobenius theory. Our analyses improve upon that of Ferbach et al. (2024) and provide convergence results in settings where the well-known Banach contraction mapping arguments do not apply. Stability and non-stability results regarding the retraining dynamics are also given.
Diffusion-Guided Gaussian Splatting for Large-Scale Unconstrained 3D Reconstruction and Novel View Synthesis
Apr 02, 2025Recent advancements in 3D Gaussian Splatting (3DGS) and Neural Radiance Fields (NeRF) have achieved impressive results in real-time 3D reconstruction and novel view synthesis. However, these methods struggle in large-scale, unconstrained environments where sparse and uneven input coverage, transient occlusions, appearance variability, and inconsistent camera settings lead to degraded quality. We propose GS-Diff, a novel 3DGS framework guided by a multi-view diffusion model to address these limitations. By generating pseudo-observations conditioned on multi-view inputs, our method transforms under-constrained 3D reconstruction problems into well-posed ones, enabling robust optimization even with sparse data. GS-Diff further integrates several enhancements, including appearance embedding, monocular depth priors, dynamic object modeling, anisotropy regularization, and advanced rasterization techniques, to tackle geometric and photometric challenges in real-world settings. Experiments on four benchmarks demonstrate that GS-Diff consistently outperforms state-of-the-art baselines by significant margins.
Lightspeed Geometric Dataset Distance via Sliced Optimal Transport
Jan 31, 2025



We introduce sliced optimal transport dataset distance (s-OTDD), a model-agnostic, embedding-agnostic approach for dataset comparison that requires no training, is robust to variations in the number of classes, and can handle disjoint label sets. The core innovation is Moment Transform Projection (MTP), which maps a label, represented as a distribution over features, to a real number. Using MTP, we derive a data point projection that transforms datasets into one-dimensional distributions. The s-OTDD is defined as the expected Wasserstein distance between the projected distributions, with respect to random projection parameters. Leveraging the closed form solution of one-dimensional optimal transport, s-OTDD achieves (near-)linear computational complexity in the number of data points and feature dimensions and is independent of the number of classes. With its geometrically meaningful projection, s-OTDD strongly correlates with the optimal transport dataset distance while being more efficient than existing dataset discrepancy measures. Moreover, it correlates well with the performance gap in transfer learning and classification accuracy in data augmentation.
One Diffusion to Generate Them All
Nov 25, 2024



We introduce OneDiffusion, a versatile, large-scale diffusion model that seamlessly supports bidirectional image synthesis and understanding across diverse tasks. It enables conditional generation from inputs such as text, depth, pose, layout, and semantic maps, while also handling tasks like image deblurring, upscaling, and reverse processes such as depth estimation and segmentation. Additionally, OneDiffusion allows for multi-view generation, camera pose estimation, and instant personalization using sequential image inputs. Our model takes a straightforward yet effective approach by treating all tasks as frame sequences with varying noise scales during training, allowing any frame to act as a conditioning image at inference time. Our unified training framework removes the need for specialized architectures, supports scalable multi-task training, and adapts smoothly to any resolution, enhancing both generalization and scalability. Experimental results demonstrate competitive performance across tasks in both generation and prediction such as text-to-image, multiview generation, ID preservation, depth estimation and camera pose estimation despite relatively small training dataset. Our code and checkpoint are freely available at https://github.com/lehduong/OneDiffusion
Preserving Identity with Variational Score for General-purpose 3D Editing
Jun 13, 2024

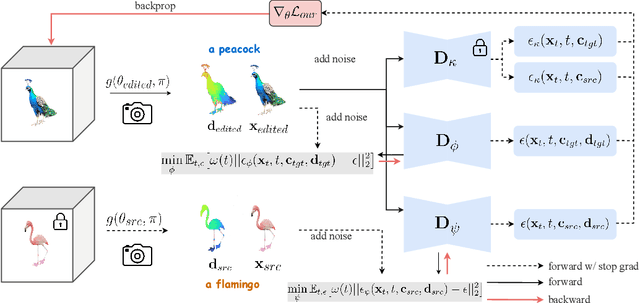

We present Piva (Preserving Identity with Variational Score Distillation), a novel optimization-based method for editing images and 3D models based on diffusion models. Specifically, our approach is inspired by the recently proposed method for 2D image editing - Delta Denoising Score (DDS). We pinpoint the limitations in DDS for 2D and 3D editing, which causes detail loss and over-saturation. To address this, we propose an additional score distillation term that enforces identity preservation. This results in a more stable editing process, gradually optimizing NeRF models to match target prompts while retaining crucial input characteristics. We demonstrate the effectiveness of our approach in zero-shot image and neural field editing. Our method successfully alters visual attributes, adds both subtle and substantial structural elements, translates shapes, and achieves competitive results on standard 2D and 3D editing benchmarks. Additionally, our method imposes no constraints like masking or pre-training, making it compatible with a wide range of pre-trained diffusion models. This allows for versatile editing without needing neural field-to-mesh conversion, offering a more user-friendly experience.
Neural NeRF Compression
Jun 13, 2024



Neural Radiance Fields (NeRFs) have emerged as powerful tools for capturing detailed 3D scenes through continuous volumetric representations. Recent NeRFs utilize feature grids to improve rendering quality and speed; however, these representations introduce significant storage overhead. This paper presents a novel method for efficiently compressing a grid-based NeRF model, addressing the storage overhead concern. Our approach is based on the non-linear transform coding paradigm, employing neural compression for compressing the model's feature grids. Due to the lack of training data involving many i.i.d scenes, we design an encoder-free, end-to-end optimized approach for individual scenes, using lightweight decoders. To leverage the spatial inhomogeneity of the latent feature grids, we introduce an importance-weighted rate-distortion objective and a sparse entropy model employing a masking mechanism. Our experimental results validate that our proposed method surpasses existing works in terms of grid-based NeRF compression efficacy and reconstruction quality.
Temporal Predictive Coding For Model-Based Planning In Latent Space
Jun 14, 2021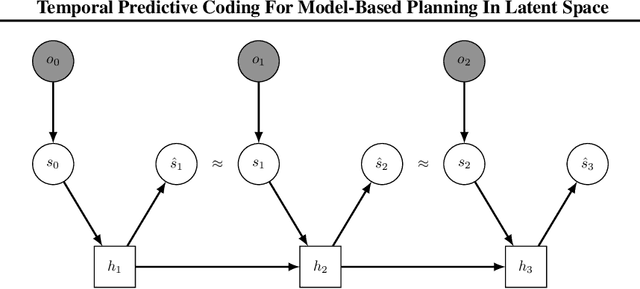
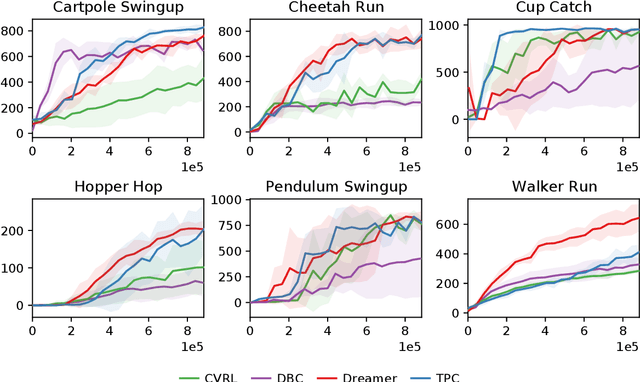
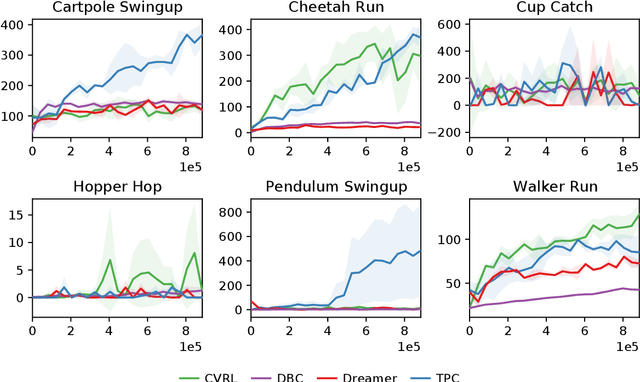
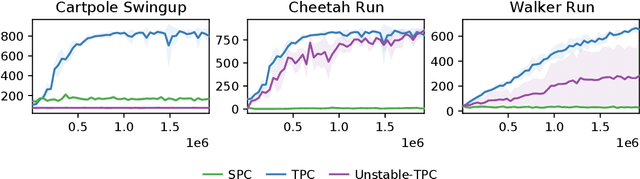
High-dimensional observations are a major challenge in the application of model-based reinforcement learning (MBRL) to real-world environments. To handle high-dimensional sensory inputs, existing approaches use representation learning to map high-dimensional observations into a lower-dimensional latent space that is more amenable to dynamics estimation and planning. In this work, we present an information-theoretic approach that employs temporal predictive coding to encode elements in the environment that can be predicted across time. Since this approach focuses on encoding temporally-predictable information, we implicitly prioritize the encoding of task-relevant components over nuisance information within the environment that are provably task-irrelevant. By learning this representation in conjunction with a recurrent state space model, we can then perform planning in latent space. We evaluate our model on a challenging modification of standard DMControl tasks where the background is replaced with natural videos that contain complex but irrelevant information to the planning task. Our experiments show that our model is superior to existing methods in the challenging complex-background setting while remaining competitive with current state-of-the-art models in the standard setting.
Predictive Coding for Locally-Linear Control
Mar 02, 2020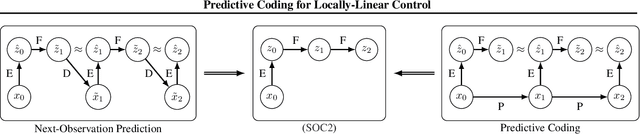
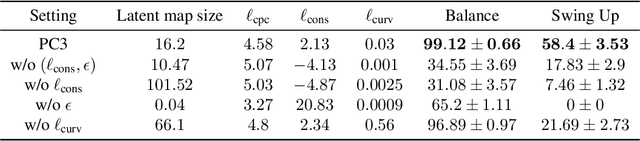


High-dimensional observations and unknown dynamics are major challenges when applying optimal control to many real-world decision making tasks. The Learning Controllable Embedding (LCE) framework addresses these challenges by embedding the observations into a lower dimensional latent space, estimating the latent dynamics, and then performing control directly in the latent space. To ensure the learned latent dynamics are predictive of next-observations, all existing LCE approaches decode back into the observation space and explicitly perform next-observation prediction---a challenging high-dimensional task that furthermore introduces a large number of nuisance parameters (i.e., the decoder) which are discarded during control. In this paper, we propose a novel information-theoretic LCE approach and show theoretically that explicit next-observation prediction can be replaced with predictive coding. We then use predictive coding to develop a decoder-free LCE model whose latent dynamics are amenable to locally-linear control. Extensive experiments on benchmark tasks show that our model reliably learns a controllable latent space that leads to superior performance when compared with state-of-the-art LCE baselines.