 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Diffusion Coefficients in Mixtures with Tensor Completion
Feb 26, 2026Predicting diffusion coefficients in mixtures is crucial for many applications, as experimental data remain scarce, and machine learning (ML) offers promising alternatives to established semi-empirical models. Among ML models, matrix completion methods (MCMs) have proven effective in predicting thermophysical properties, including diffusion coefficients in binary mixtures. However, MCMs are restricted to single-temperature predictions, and their accuracy depends strongly on the availability of high-quality experimental data for each temperature of interest. In this work, we address this challenge by presenting a hybrid tensor completion method (TCM) for predicting temperature-dependent diffusion coefficients at infinite dilution in binary mixtures. The TCM employs a Tucker decomposition and is jointly trained on experimental data for diffusion coefficients at infinite dilution in binary systems at 298 K, 313 K, and 333 K. Predictions from the semi-empirical SEGWE model serve as prior knowledge within a Bayesian training framework. The TCM then extrapolates linearly to any temperature between 268 K and 378 K, achieving markedly improved prediction accuracy compared to established models across all studied temperatures. To further enhance predictive performance, the experimental database was expanded using active learning (AL) strategies for targeted acquisition of new diffusion data by pulsed-field gradient (PFG) NMR measurements. Diffusion coefficients at infinite dilution in 19 solute + solvent systems were measured at 298 K, 313 K, and 333 K. Incorporating these results yields a substantial improvement in the TCM's predictive accuracy. These findings highlight the potential of combining data-efficient ML methods with adaptive experimentation to advance predictive modeling of transport properties.
Superstudent intelligence in thermodynamics
Jun 11, 2025In this short note, we report and analyze a striking event: OpenAI's large language model o3 has outwitted all students in a university exam on thermodynamics. The thermodynamics exam is a difficult hurdle for most students, where they must show that they have mastered the fundamentals of this important topic. Consequently, the failure rates are very high, A-grades are rare - and they are considered proof of the students' exceptional intellectual abilities. This is because pattern learning does not help in the exam. The problems can only be solved by knowledgeably and creatively combining principles of thermodynamics. We have given our latest thermodynamics exam not only to the students but also to OpenAI's most powerful reasoning model, o3, and have assessed the answers of o3 exactly the same way as those of the students. In zero-shot mode, the model o3 solved all problems correctly, better than all students who took the exam; its overall score was in the range of the best scores we have seen in more than 10,000 similar exams since 1985. This is a turning point: machines now excel in complex tasks, usually taken as proof of human intellectual capabilities. We discuss the consequences this has for the work of engineers and the education of future engineers.
MLPROP -- an open interactive web interface for thermophysical property prediction with machine learning
Apr 08, 2025Machine learning (ML) enables the development of powerful methods for predicting thermophysical properties with unprecedented scope and accuracy. However, technical barriers like cumbersome implementation in established workflows hinder their application in practice. With MLPROP, we provide an interactive web interface for directly applying advanced ML methods to predict thermophysical properties without requiring ML expertise, thereby substantially increasing the accessibility of novel models. MLPROP currently includes models for predicting the vapor pressure of pure components (GRAPPA), activity coefficients and vapor-liquid equilibria in binary mixtures (UNIFAC 2.0, mod. UNIFAC 2.0, and HANNA), and a routine to fit NRTL parameters to the model predictions. MLPROP will be continuously updated and extended and is accessible free of charge via https://ml-prop.mv.rptu.de/. MLPROP removes the barrier to learning and experimenting with new ML-based methods for predicting thermophysical properties. The source code of all models is available as open source, which allows integration into existing workflows.
GRAPPA -- A Hybrid Graph Neural Network for Predicting Pure Component Vapor Pressures
Jan 15, 2025Although the pure component vapor pressure is one of the most important properties for designing chemical processes, no broadly applicable, sufficiently accurate, and open-source prediction method has been available. To overcome this, we have developed GRAPPA - a hybrid graph neural network for predicting vapor pressures of pure components. GRAPPA enables the prediction of the vapor pressure curve of basically any organic molecule, requiring only the molecular structure as input. The new model consists of three parts: A graph attention network for the message passing step, a pooling function that captures long-range interactions, and a prediction head that yields the component-specific parameters of the Antoine equation, from which the vapor pressure can readily and consistently be calculated for any temperature. We have trained and evaluated GRAPPA on experimental vapor pressure data of almost 25,000 pure components. We found excellent prediction accuracy for unseen components, outperforming state-of-the-art group contribution methods and other machine learning approaches in applicability and accuracy. The trained model and its code are fully disclosed, and GRAPPA is directly applicable via the interactive website ml-prop.mv.rptu.de.
Hierarchical Matrix Completion for the Prediction of Properties of Binary Mixtures
Oct 08, 2024Predicting the thermodynamic properties of mixtures is crucial for process design and optimization in chemical engineering. Machine learning (ML) methods are gaining increasing attention in this field, but experimental data for training are often scarce, which hampers their application. In this work, we introduce a novel generic approach for improving data-driven models: inspired by the ancient rule "similia similibus solvuntur", we lump components that behave similarly into chemical classes and model them jointly in the first step of a hierarchical approach. While the information on class affiliations can stem in principle from any source, we demonstrate how classes can reproducibly be defined based on mixture data alone by agglomerative clustering. The information from this clustering step is then used as an informed prior for fitting the individual data. We demonstrate the benefits of this approach by applying it in connection with a matrix completion method (MCM) for predicting isothermal activity coefficients at infinite dilution in binary mixtures. Using clustering leads to significantly improved predictions compared to an MCM without clustering. Furthermore, the chemical classes learned from the clustering give exciting insights into what matters on the molecular level for modeling given mixture properties.
HANNA: Hard-constraint Neural Network for Consistent Activity Coefficient Prediction
Jul 25, 2024We present the first hard-constraint neural network for predicting activity coefficients (HANNA), a thermodynamic mixture property that is the basis for many applications in science and engineering. Unlike traditional neural networks, which ignore physical laws and result in inconsistent predictions, our model is designed to strictly adhere to all thermodynamic consistency criteria. By leveraging deep-set neural networks, HANNA maintains symmetry under the permutation of the components. Furthermore, by hard-coding physical constraints in the network architecture, we ensure consistency with the Gibbs-Duhem equation and in modeling the pure components. The model was trained and evaluated on 317,421 data points for activity coefficients in binary mixtures from the Dortmund Data Bank, achieving significantly higher prediction accuracies than the current state-of-the-art model UNIFAC. Moreover, HANNA only requires the SMILES of the components as input, making it applicable to any binary mixture of interest. HANNA is fully open-source and available for free use.
Deep Anomaly Detection on Tennessee Eastman Process Data
Mar 10, 2023This paper provides the first comprehensive evaluation and analysis of modern (deep-learning) unsupervised anomaly detection methods for chemical process data. We focus on the Tennessee Eastman process dataset, which has been a standard litmus test to benchmark anomaly detection methods for nearly three decades. Our extensive study will facilitate choosing appropriate anomaly detection methods in industrial applications.
Attribute-based Explanations of Non-Linear Embeddings of High-Dimensional Data
Jul 28, 2021
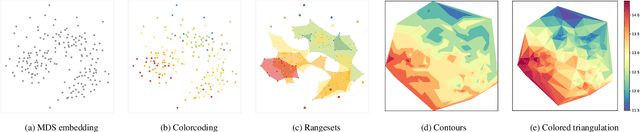

Embeddings of high-dimensional data are widely used to explore data, to verify analysis results, and to communicate information. Their explanation, in particular with respect to the input attributes, is often difficult. With linear projects like PCA the axes can still be annotated meaningfully. With non-linear projections this is no longer possible and alternative strategies such as attribute-based color coding are required. In this paper, we review existing augmentation techniques and discuss their limitations. We present the Non-Linear Embeddings Surveyor (NoLiES) that combines a novel augmentation strategy for projected data (rangesets) with interactive analysis in a small multiples setting. Rangesets use a set-based visualization approach for binned attribute values that enable the user to quickly observe structure and detect outliers. We detail the link between algebraic topology and rangesets and demonstrate the utility of NoLiES in case studies with various challenges (complex attribute value distribution, many attributes, many data points) and a real-world application to understand latent features of matrix completion in thermodynamics.
Machine Learning in Thermodynamics: Prediction of Activity Coefficients by Matrix Completion
Jan 29, 2020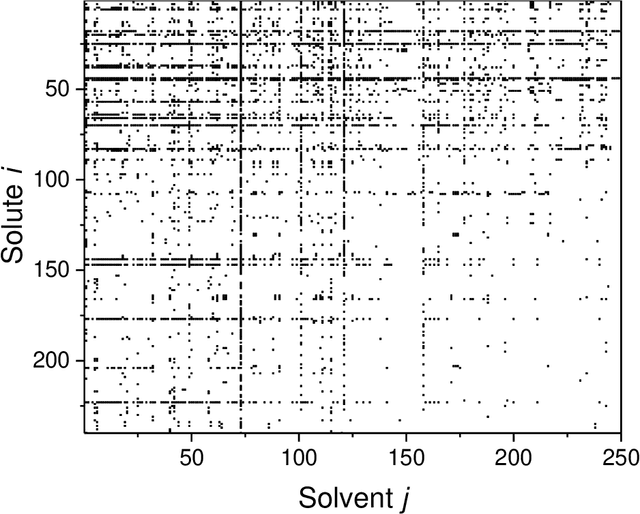
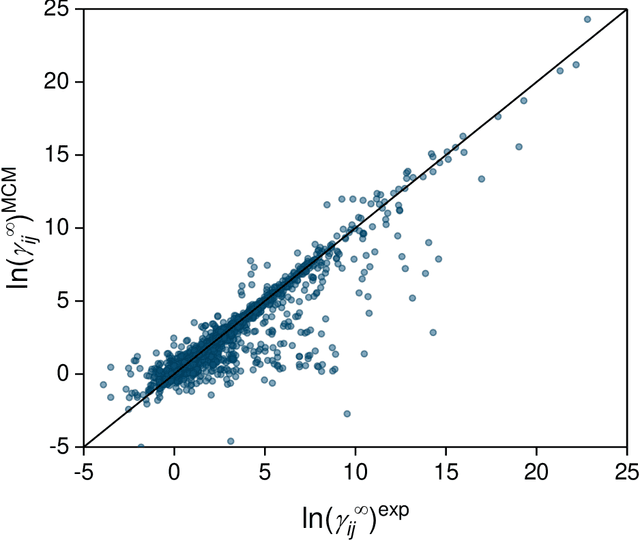
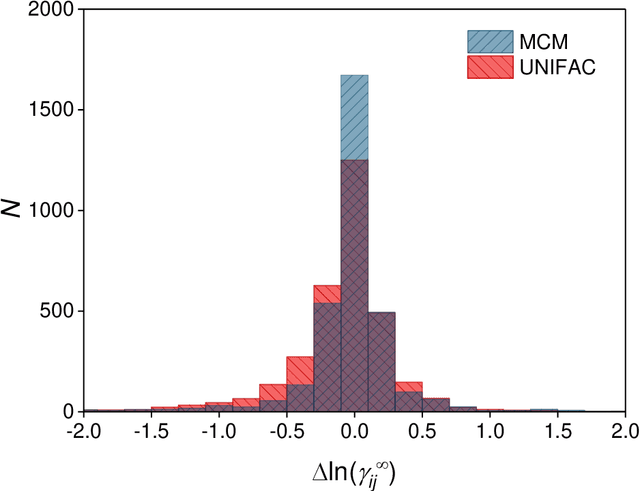
Activity coefficients, which are a measure of the non-ideality of liquid mixtures, are a key property in chemical engineering with relevance to modeling chemical and phase equilibria as well as transport processes. Although experimental data on thousands of binary mixtures are available, prediction methods are needed to calculate the activity coefficients in many relevant mixtures that have not been explored to-date. In this report, we propose a probabilistic matrix factorization model for predicting the activity coefficients in arbitrary binary mixtures. Although no physical descriptors for the considered components were used, our method outperforms the state-of-the-art method that has been refined over three decades while requiring much less training effort. This opens perspectives to novel methods for predicting physico-chemical properties of binary mixtures with the potential to revolutionize modeling and simulation in chemical engineering.
* Published version: J. Phys. Chem. Lett. 11 (2020) 981-985; https://pubs.acs.org/doi/full/10.1021/acs.jpclett.9b03657