 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Graph Foundation Models: A Study on the Generalization of Positional and Structural Encodings
Dec 10, 2024Recent advances in integrating positional and structural encodings (PSEs) into graph neural networks (GNNs) have significantly enhanced their performance across various graph learning tasks. However, the general applicability of these encodings and their potential to serve as foundational representations for graphs remain uncertain. This paper investigates the fine-tuning efficiency, scalability with sample size, and generalization capability of learnable PSEs across diverse graph datasets. Specifically, we evaluate their potential as universal pre-trained models that can be easily adapted to new tasks with minimal fine-tuning and limited data. Furthermore, we assess the expressivity of the learned representations, particularly, when used to augment downstream GNNs. We demonstrate through extensive benchmarking and empirical analysis that PSEs generally enhance downstream models. However, some datasets may require specific PSE-augmentations to achieve optimal performance. Nevertheless, our findings highlight their significant potential to become integral components of future graph foundation models. We provide new insights into the strengths and limitations of PSEs, contributing to the broader discourse on foundation models in graph learning.
Deep Anomaly Detection on Tennessee Eastman Process Data
Mar 10, 2023This paper provides the first comprehensive evaluation and analysis of modern (deep-learning) unsupervised anomaly detection methods for chemical process data. We focus on the Tennessee Eastman process dataset, which has been a standard litmus test to benchmark anomaly detection methods for nearly three decades. Our extensive study will facilitate choosing appropriate anomaly detection methods in industrial applications.
Ordinal Regression for Difficulty Estimation of StepMania Levels
Jan 23, 2023



StepMania is a popular open-source clone of a rhythm-based video game. As is common in popular games, there is a large number of community-designed levels. It is often difficult for players and level authors to determine the difficulty level of such community contributions. In this work, we formalize and analyze the difficulty prediction task on StepMania levels as an ordinal regression (OR) task. We standardize a more extensive and diverse selection of this data resulting in five data sets, two of which are extensions of previous work. We evaluate many competitive OR and non-OR models, demonstrating that neural network-based models significantly outperform the state of the art and that StepMania-level data makes for an excellent test bed for deep OR models. We conclude with a user experiment showing our trained models' superiority over human labeling.
Exposing Outlier Exposure: What Can Be Learned From Few, One, and Zero Outlier Images
May 23, 2022

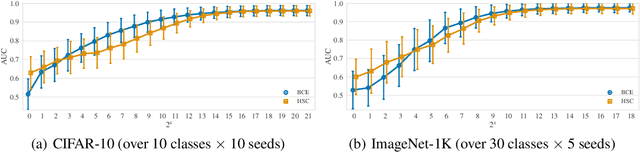
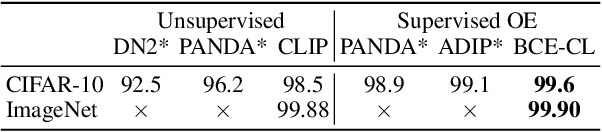
Traditionally anomaly detection (AD) is treated as an unsupervised problem utilizing only normal samples due to the intractability of characterizing everything that looks unlike the normal data. However, it has recently been found that unsupervised image anomaly detection can be drastically improved through the utilization of huge corpora of random images to represent anomalousness; a technique which is known as Outlier Exposure. In this paper we show that specialized AD learning methods seem actually superfluous and huge corpora of data expendable. For a common AD benchmark on ImageNet, standard classifiers and semi-supervised one-class methods trained to discern between normal samples and just a few random natural images are able to outperform the current state of the art in deep AD, and only one useful outlier sample is sufficient to perform competitively. We investigate this phenomenon and reveal that one-class methods are more robust towards the particular choice of training outliers. Furthermore, we find that a simple classifier based on representations from CLIP, a recent foundation model, achieves state-of-the-art results on CIFAR-10 and also outperforms all previous AD methods on ImageNet without any training samples (i.e., in a zero-shot setting).
Trainability for Universal GNNs Through Surgical Randomness
Dec 08, 2021

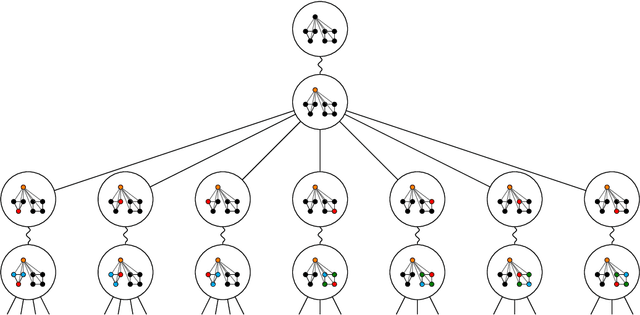
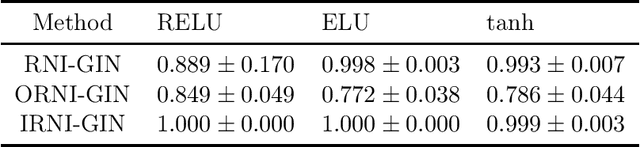
Message passing neural networks (MPNN) have provable limitations, which can be overcome by universal networks. However, universal networks are typically impractical. The only exception is random node initialization (RNI), a data augmentation method that results in provably universal networks. Unfortunately, RNI suffers from severe drawbacks such as slow convergence and high sensitivity to changes in hyperparameters. We transfer powerful techniques from the practical world of graph isomorphism testing to MPNNs, resolving these drawbacks. This culminates in individualization-refinement node initialization (IRNI). We replace the indiscriminate and haphazard randomness used in RNI by a surgical incision of only a few random bits at well-selected nodes. Our novel non-intrusive data-augmentation scheme maintains the networks' universality while resolving the trainability issues. We formally prove the claimed universality and corroborate experimentally -- on synthetic benchmarks sets previously explicitly designed for that purpose -- that IRNI overcomes the limitations of MPNNs. We also verify the practical efficacy of our approach on the standard benchmark data sets PROTEINS and NCI1.
Explainable Deep One-Class Classification
Jul 03, 2020

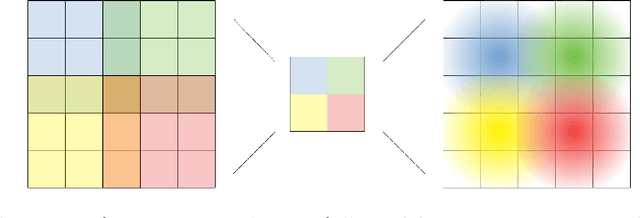
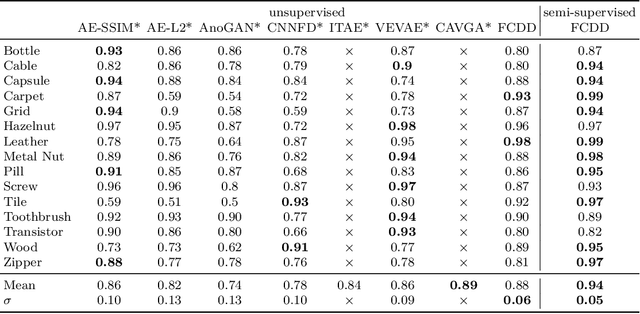
Deep one-class classification variants for anomaly detection learn a mapping that concentrates nominal samples in feature space causing anomalies to be mapped away. Because this transformation is highly non-linear, finding interpretations poses a significant challenge. In this paper we present an explainable deep one-class classification method, Fully Convolutional Data Description (FCDD), where the mapped samples are themselves also an explanation heatmap. FCDD yields competitive detection performance and provides reasonable explanations on common anomaly detection benchmarks with CIFAR-10 and ImageNet. On MVTec-AD, a recent manufacturing dataset offering ground-truth anomaly maps, FCDD meets the state of the art in an unsupervised setting, and outperforms its competitors in a semi-supervised setting. Finally, using FCDD's explanations we demonstrate the vulnerability of deep one-class classification models to spurious image features such as image watermarks.
Rethinking Assumptions in Deep Anomaly Detection
May 30, 2020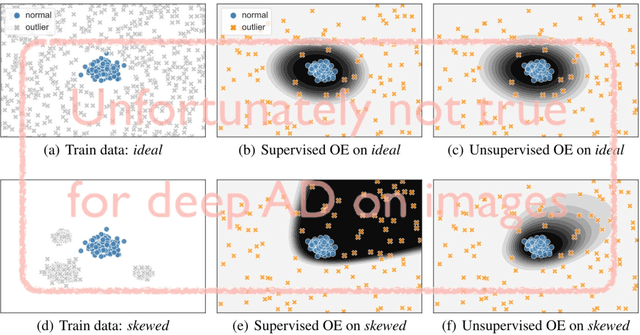
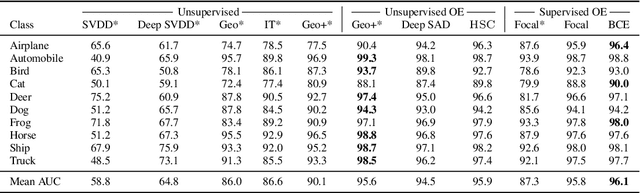

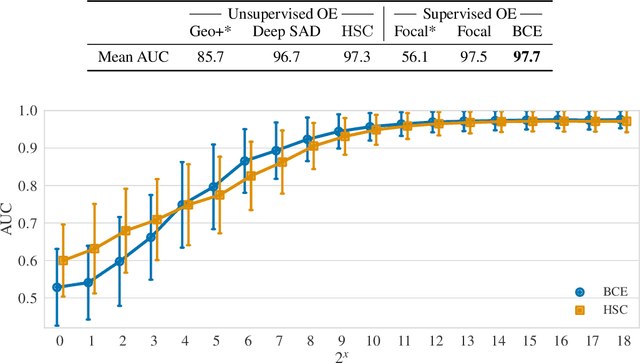
Though anomaly detection (AD) can be viewed as a classification problem (nominal vs. anomalous) it is usually treated in an unsupervised manner since one typically does not have access to, or it is infeasible to utilize, a dataset that sufficiently characterizes what it means to be "anomalous." In this paper we present results demonstrating that this intuition surprisingly does not extend to deep AD on images. For a recent AD benchmark on ImageNet, classifiers trained to discern between normal samples and just a few (64) random natural images are able to outperform the current state of the art in deep AD. We find that this approach is also very effective at other common image AD benchmarks. Experimentally we discover that the multiscale structure of image data makes example anomalies exceptionally informative.