 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Outlier Exposure: What Can Be Learned From Few, One, and Zero Outlier Images
Paper and Code


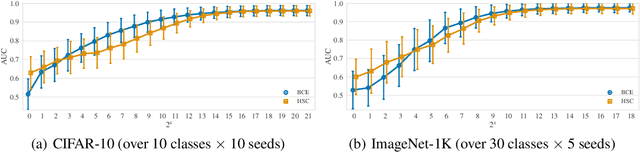
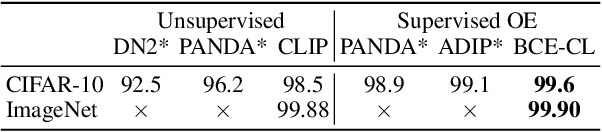
Traditionally anomaly detection (AD) is treated as an unsupervised problem utilizing only normal samples due to the intractability of characterizing everything that looks unlike the normal data. However, it has recently been found that unsupervised image anomaly detection can be drastically improved through the utilization of huge corpora of random images to represent anomalousness; a technique which is known as Outlier Exposure. In this paper we show that specialized AD learning methods seem actually superfluous and huge corpora of data expendable. For a common AD benchmark on ImageNet, standard classifiers and semi-supervised one-class methods trained to discern between normal samples and just a few random natural images are able to outperform the current state of the art in deep AD, and only one useful outlier sample is sufficient to perform competitively. We investigate this phenomenon and reveal that one-class methods are more robust towards the particular choice of training outliers. Furthermore, we find that a simple classifier based on representations from CLIP, a recent foundation model, achieves state-of-the-art results on CIFAR-10 and also outperforms all previous AD methods on ImageNet without any training samples (i.e., in a zero-shot setting).