 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Assumptions in Deep Anomaly Detection
Paper and Code
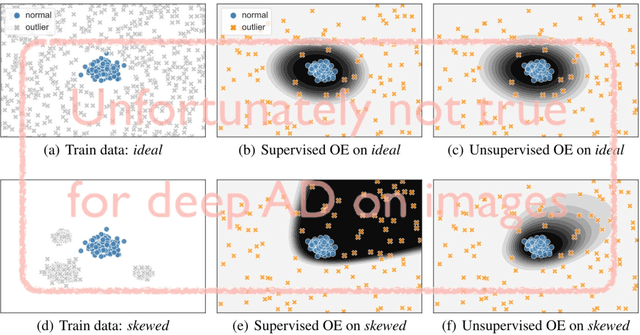
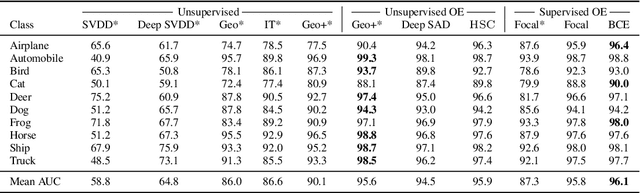

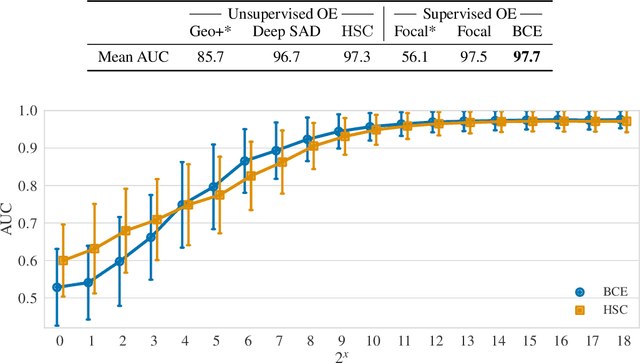
Though anomaly detection (AD) can be viewed as a classification problem (nominal vs. anomalous) it is usually treated in an unsupervised manner since one typically does not have access to, or it is infeasible to utilize, a dataset that sufficiently characterizes what it means to be "anomalous." In this paper we present results demonstrating that this intuition surprisingly does not extend to deep AD on images. For a recent AD benchmark on ImageNet, classifiers trained to discern between normal samples and just a few (64) random natural images are able to outperform the current state of the art in deep AD. We find that this approach is also very effective at other common image AD benchmarks. Experimentally we discover that the multiscale structure of image data makes example anomalies exceptionally informative.