 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating PDE Surrogates via RL-Guided Mesh Optimization
Mar 02, 2026Deep surrogate models for parametric partial differential equations (PDEs) can deliver high-fidelity approximations but remain prohibitively data-hungry: training often requires thousands of fine-grid simulations, each incurring substantial computational cost. To address this challenge, we introduce RLMesh, an end-to-end framework for efficient surrogate training under limited simulation budget. The key idea is to use reinforcement learning (RL) to adaptively allocate mesh grid points non-uniformly within each simulation domain, focusing numerical resolution in regions most critical for accurate PDE solutions. A lightweight proxy model further accelerates RL training by providing efficient reward estimates without full surrogate retraining. Experiments on PDE benchmarks demonstrate that RLMesh achieves competitive accuracy to baselines but with substantially fewer simulation queries. These results show that solver-level spatial adaptivity can dramatically improve the efficiency of surrogate training pipelines, enabling practical deployment of learning-based PDE surrogates across a wide range of problems.
Weakly-Supervised Multimodal Learning on MIMIC-CXR
Nov 15, 2024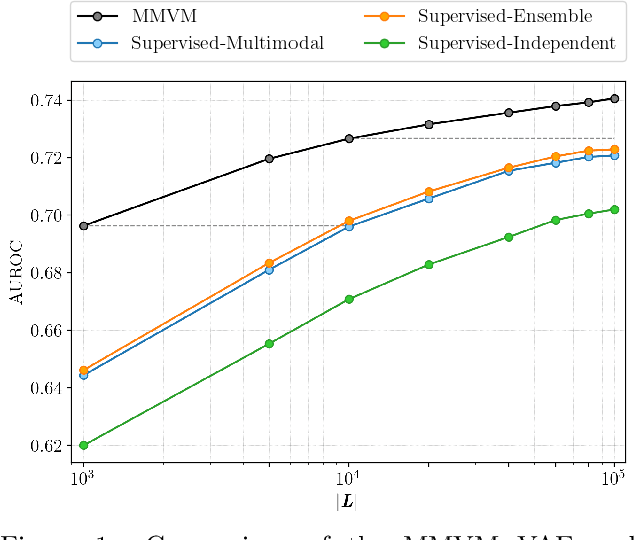
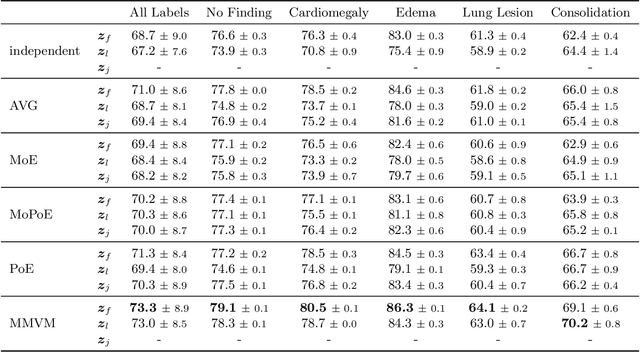
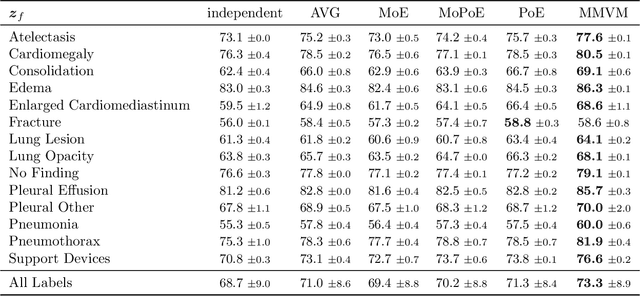
Multimodal data integration and label scarcity pose significant challenges for machine learning in medical settings. To address these issues, we conduct an in-depth evaluation of the newly proposed Multimodal Variational Mixture-of-Experts (MMVM) VAE on the challenging MIMIC-CXR dataset. Our analysis demonstrates that the MMVM VAE consistently outperforms other multimodal VAEs and fully supervised approaches, highlighting its strong potential for real-world medical applications.
Unity by Diversity: Improved Representation Learning in Multimodal VAEs
Mar 08, 2024



Variational Autoencoders for multimodal data hold promise for many tasks in data analysis, such as representation learning, conditional generation, and imputation. Current architectures either share the encoder output, decoder input, or both across modalities to learn a shared representation. Such architectures impose hard constraints on the model. In this work, we show that a better latent representation can be obtained by replacing these hard constraints with a soft constraint. We propose a new mixture-of-experts prior, softly guiding each modality's latent representation towards a shared aggregate posterior. This approach results in a superior latent representation and allows each encoding to preserve information from its uncompressed original features better. In extensive experiments on multiple benchmark datasets and a challenging real-world neuroscience data set, we show improved learned latent representations and imputation of missing data modalities compared to existing methods.