 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing Milabench: Benchmarking Accelerators for AI
Nov 18, 2024



AI workloads, particularly those driven by deep learning, are introducing novel usage patterns to high-performance computing (HPC) systems that are not comprehensively captured by standard HPC benchmarks. As one of the largest academic research centers dedicated to deep learning, Mila identified the need to develop a custom benchmarking suite to address the diverse requirements of its community, which consists of over 1,000 researchers. This report introduces Milabench, the resulting benchmarking suite. Its design was informed by an extensive literature review encompassing 867 papers, as well as surveys conducted with Mila researchers. This rigorous process led to the selection of 26 primary benchmarks tailored for procurement evaluations, alongside 16 optional benchmarks for in-depth analysis. We detail the design methodology, the structure of the benchmarking suite, and provide performance evaluations using GPUs from NVIDIA, AMD, and Intel. The Milabench suite is open source and can be accessed at github.com/mila-iqia/milabench.
Towards Scaling Difference Target Propagation by Learning Backprop Targets
Jan 31, 2022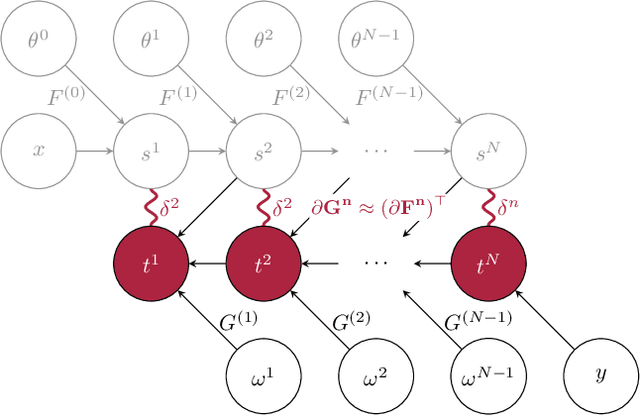

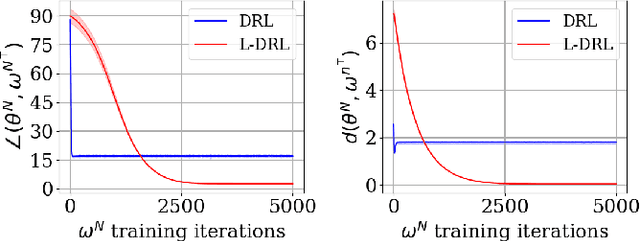

The development of biologically-plausible learning algorithms is important for understanding learning in the brain, but most of them fail to scale-up to real-world tasks, limiting their potential as explanations for learning by real brains. As such, it is important to explore learning algorithms that come with strong theoretical guarantees and can match the performance of backpropagation (BP) on complex tasks. One such algorithm is Difference Target Propagation (DTP), a biologically-plausible learning algorithm whose close relation with Gauss-Newton (GN) optimization has been recently established. However, the conditions under which this connection rigorously holds preclude layer-wise training of the feedback pathway synaptic weights (which is more biologically plausible). Moreover, good alignment between DTP weight updates and loss gradients is only loosely guaranteed and under very specific conditions for the architecture being trained. In this paper, we propose a novel feedback weight training scheme that ensures both that DTP approximates BP and that layer-wise feedback weight training can be restored without sacrificing any theoretical guarantees. Our theory is corroborated by experimental results and we report the best performance ever achieved by DTP on CIFAR-10 and ImageNet 32$\times$32
Sequoia: A Software Framework to Unify Continual Learning Research
Aug 03, 2021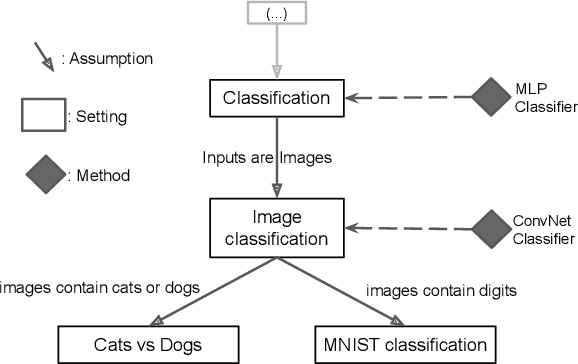
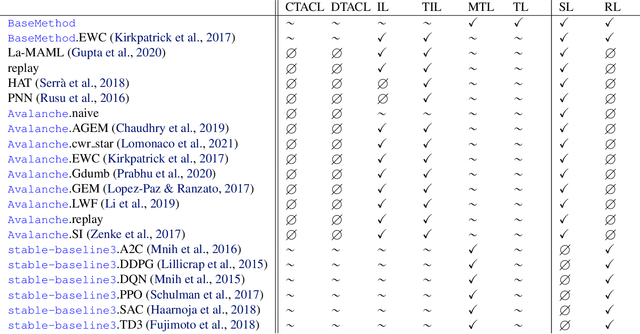
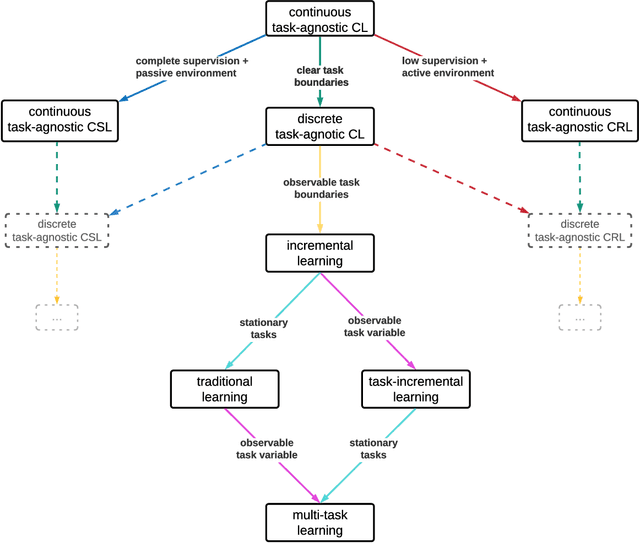
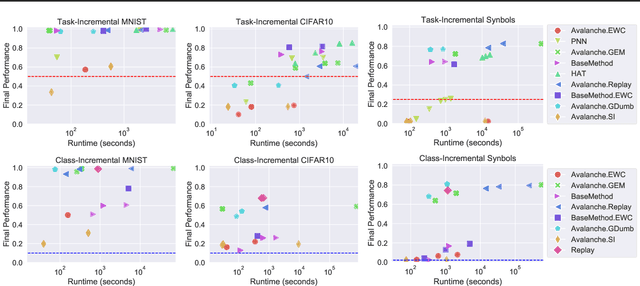
The field of Continual Learning (CL) seeks to develop algorithms that accumulate knowledge and skills over time through interaction with non-stationary environments and data distributions. Measuring progress in CL can be difficult because a plethora of evaluation procedures (ettings) and algorithmic solutions (methods) have emerged, each with their own potentially disjoint set of assumptions about the CL problem. In this work, we view each setting as a set of assumptions. We then create a tree-shaped hierarchy of the research settings in CL, in which more general settings become the parents of those with more restrictive assumptions. This makes it possible to use inheritance to share and reuse research, as developing a method for a given setting also makes it directly applicable onto any of its children. We instantiate this idea as a publicly available software framework called Sequoia, which features a variety of settings from both the Continual Supervised Learning (CSL) and Continual Reinforcement Learning (CRL) domains. Sequoia also includes a growing suite of methods which are easy to extend and customize, in addition to more specialized methods from third-party libraries. We hope that this new paradigm and its first implementation can serve as a foundation for the unification and acceleration of research in CL. You can help us grow the tree by visiting www.github.com/lebrice/Sequoia.
Online Fast Adaptation and Knowledge Accumulation: a New Approach to Continual Learning
Mar 12, 2020
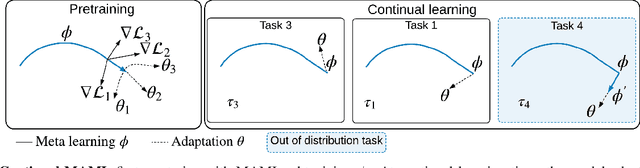
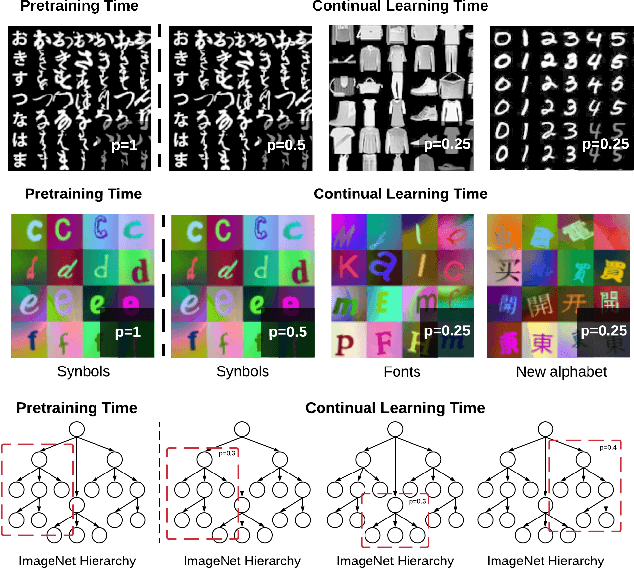
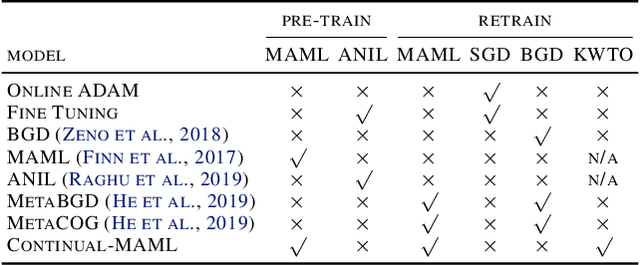
Learning from non-stationary data remains a great challenge for machine learning. Continual learning addresses this problem in scenarios where the learning agent faces a stream of changing tasks. In these scenarios, the agent is expected to retain its highest performance on previous tasks without revisiting them while adapting well to the new tasks. Two new recent continual-learning scenarios have been proposed. In meta-continual learning, the model is pre-trained to minimize catastrophic forgetting when trained on a sequence of tasks. In continual-meta learning, the goal is faster remembering, i.e., focusing on how quickly the agent recovers performance rather than measuring the agent's performance without any adaptation. Both scenarios have the potential to propel the field forward. Yet in their original formulations, they each have limitations. As a remedy, we propose a more general scenario where an agent must quickly solve (new) out-of-distribution tasks, while also requiring fast remembering. We show that current continual learning, meta learning, meta-continual learning, and continual-meta learning techniques fail in this new scenario. Accordingly, we propose a strong baseline: Continual-MAML, an online extension of the popular MAML algorithm. In our empirical experiments, we show that our method is better suited to the new scenario than the methodologies mentioned above, as well as standard continual learning and meta learning approaches.