 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSAI: Unbiased and Interpretable Latent Feature Extraction for Data-Centric AI
Dec 09, 2024



Large language models (LLMs) often struggle to objectively identify latent characteristics in large datasets due to their reliance on pre-trained knowledge rather than actual data patterns. To address this data grounding issue, we propose Data Scientist AI (DSAI), a framework that enables unbiased and interpretable feature extraction through a multi-stage pipeline with quantifiable prominence metrics for evaluating extracted features. On synthetic datasets with known ground-truth features, DSAI demonstrates high recall in identifying expert-defined features while faithfully reflecting the underlying data. Applications on real-world datasets illustrate the framework's practical utility in uncovering meaningful patterns with minimal expert oversight, supporting use cases such as interpretable classification. The title of our paper is chosen from multiple candidates based on DSAI-generated criteria.
Knowledge Entropy Decay during Language Model Pretraining Hinders New Knowledge Acquisition
Oct 02, 2024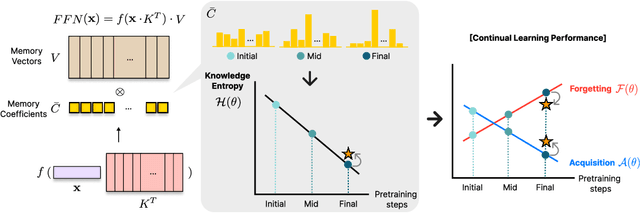
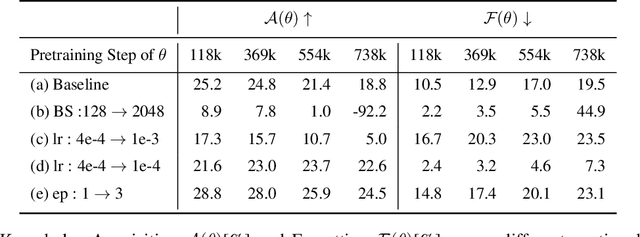
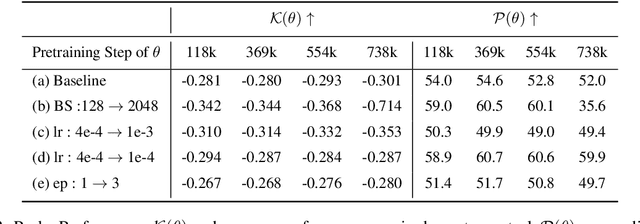
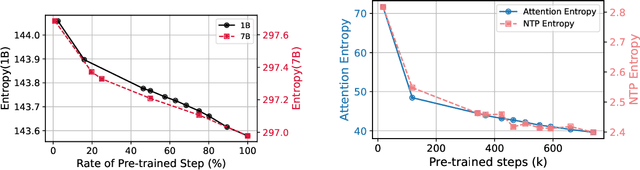
In this work, we investigate how a model's tendency to broadly integrate its parametric knowledge evolves throughout pretraining, and how this behavior affects overall performance, particularly in terms of knowledge acquisition and forgetting. We introduce the concept of knowledge entropy, which quantifies the range of memory sources the model engages with; high knowledge entropy indicates that the model utilizes a wide range of memory sources, while low knowledge entropy suggests reliance on specific sources with greater certainty. Our analysis reveals a consistent decline in knowledge entropy as pretraining advances. We also find that the decline is closely associated with a reduction in the model's ability to acquire and retain knowledge, leading us to conclude that diminishing knowledge entropy (smaller number of active memory sources) impairs the model's knowledge acquisition and retention capabilities. We find further support for this by demonstrating that increasing the activity of inactive memory sources enhances the model's capacity for knowledge acquisition and retention.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
CheckEval: Robust Evaluation Framework using Large Language Model via Checklist
Mar 27, 2024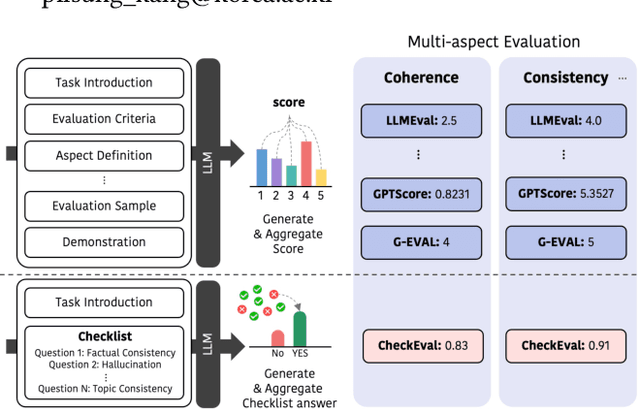
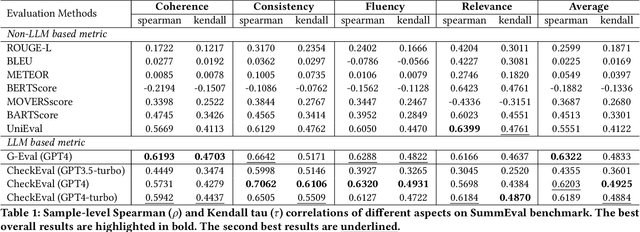
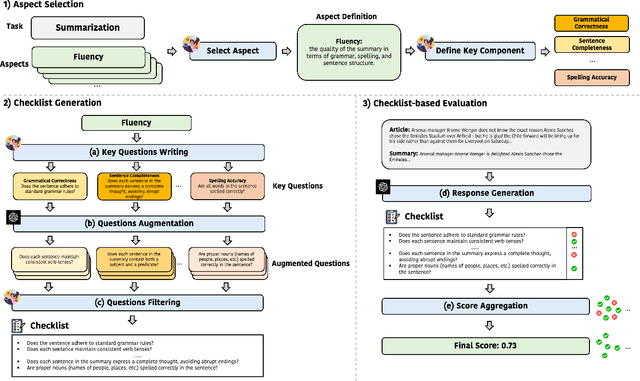
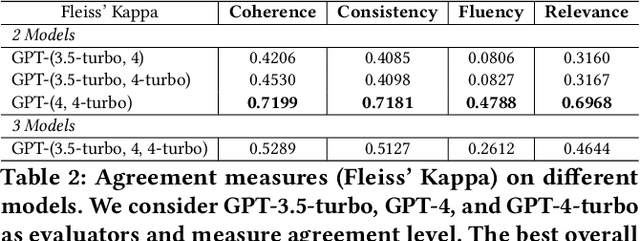
We introduce CheckEval, a novel evaluation framework using Large Language Models, addressing the challenges of ambiguity and inconsistency in current evaluation methods. CheckEval addresses these challenges by dividing evaluation criteria into detailed sub-aspects and constructing a checklist of Boolean questions for each, simplifying the evaluation. This approach not only renders the process more interpretable but also significantly enhances the robustness and reliability of results by focusing on specific evaluation dimensions. Validated through a focused case study using the SummEval benchmark, CheckEval indicates a strong correlation with human judgments. Furthermore, it demonstrates a highly consistent Inter-Annotator Agreement. These findings highlight the effectiveness of CheckEval for objective, flexible, and precise evaluations. By offering a customizable and interactive framework, CheckEval sets a new standard for the use of LLMs in evaluation, responding to the evolving needs of the field and establishing a clear method for future LLM-based evaluation.