 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUN: Shared Use of Next-token Prediction for Efficient Multi-LLM Disaggregated Serving
Mar 03, 2026In multi-model LLM serving, decode execution remains inefficient due to model-specific resource partitioning: since cross-model batching is not possible, memory-bound decoding often suffers from severe GPU underutilization, especially under skewed workloads. We propose Shared Use of Next-token Prediction (SUN), the first approach that enables cross-model sharing of decode execution in disaggregated multi-LLM serving. SUN decomposes a decoder-only Transformer into a prefill module and a decode module, and fine-tunes only the task-specific prefill module, enabling a frozen decode module to be shared across models. This design enables a model-agnostic decode routing policy that balances decode requests across shared workers to maximize utilization. Across diverse tasks and model families, SUN achieves accuracy comparable to full fine-tuning while maintaining system throughput with fewer decode workers. In particular, SUN improves throughput per GPU by up to 2.0x over conventional disaggregation while keeping time-per-output-token (TPOT) within 5%. SUN inherently enables and facilitates low-bit decoding; with Quantized SUN (QSUN), it achieves a 45% speedup with comparable accuracy to SUN while preserving the benefits of shared decoding.
PrefillShare: A Shared Prefill Module for KV Reuse in Multi-LLM Disaggregated Serving
Feb 12, 2026Multi-agent systems increasingly orchestrate multiple specialized language models to solve complex real-world problems, often invoking them over a shared context. This execution pattern repeatedly processes the same prompt prefix across models. Consequently, each model redundantly executes the prefill stage and maintains its own key-value (KV) cache, increasing aggregate prefill load and worsening tail latency by intensifying prefill-decode interference in existing LLM serving stacks. Disaggregated serving reduces such interference by placing prefill and decode on separate GPUs, but disaggregation does not fundamentally eliminate inter-model redundancy in computation and KV storage for the same prompt. To address this issue, we propose PrefillShare, a novel algorithm that enables sharing the prefill stage across multiple models in a disaggregated setting. PrefillShare factorizes the model into prefill and decode modules, freezes the prefill module, and fine-tunes only the decode module. This design allows multiple task-specific models to share a prefill module and the KV cache generated for the same prompt. We further introduce a routing mechanism that enables effective prefill sharing across heterogeneous models in a vLLM-based disaggregated system. PrefillShare not only matches full fine-tuning accuracy on a broad range of tasks and models, but also delivers 4.5x lower p95 latency and 3.9x higher throughput in multi-model agent workloads.
A.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
CheckEval: Robust Evaluation Framework using Large Language Model via Checklist
Mar 27, 2024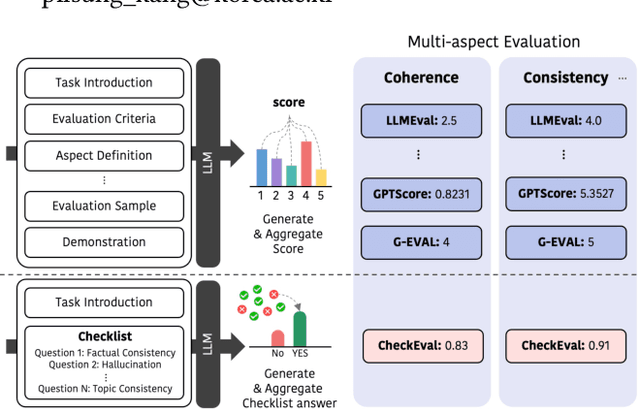
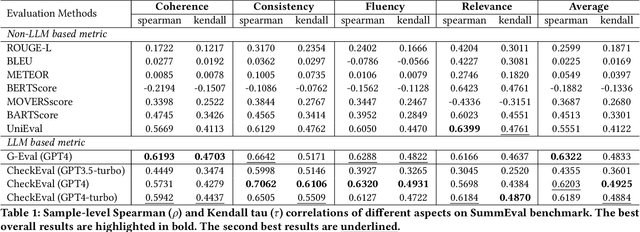
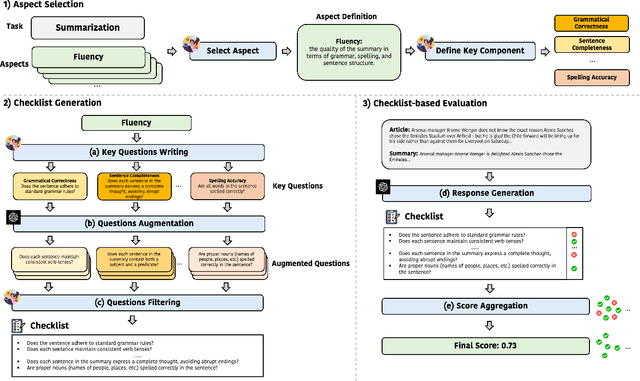
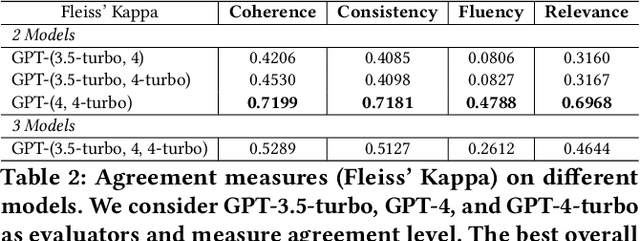
We introduce CheckEval, a novel evaluation framework using Large Language Models, addressing the challenges of ambiguity and inconsistency in current evaluation methods. CheckEval addresses these challenges by dividing evaluation criteria into detailed sub-aspects and constructing a checklist of Boolean questions for each, simplifying the evaluation. This approach not only renders the process more interpretable but also significantly enhances the robustness and reliability of results by focusing on specific evaluation dimensions. Validated through a focused case study using the SummEval benchmark, CheckEval indicates a strong correlation with human judgments. Furthermore, it demonstrates a highly consistent Inter-Annotator Agreement. These findings highlight the effectiveness of CheckEval for objective, flexible, and precise evaluations. By offering a customizable and interactive framework, CheckEval sets a new standard for the use of LLMs in evaluation, responding to the evolving needs of the field and establishing a clear method for future LLM-based evaluation.
Which is better? Exploring Prompting Strategy For LLM-based Metrics
Nov 07, 2023This paper describes the DSBA submissions to the Prompting Large Language Models as Explainable Metrics shared task, where systems were submitted to two tracks: small and large summarization tracks. With advanced Large Language Models (LLMs) such as GPT-4, evaluating the quality of Natural Language Generation (NLG) has become increasingly paramount. Traditional similarity-based metrics such as BLEU and ROUGE have shown to misalign with human evaluation and are ill-suited for open-ended generation tasks. To address this issue, we explore the potential capability of LLM-based metrics, especially leveraging open-source LLMs. In this study, wide range of prompts and prompting techniques are systematically analyzed with three approaches: prompting strategy, score aggregation, and explainability. Our research focuses on formulating effective prompt templates, determining the granularity of NLG quality scores and assessing the impact of in-context examples on LLM-based evaluation. Furthermore, three aggregation strategies are compared to identify the most reliable method for aggregating NLG quality scores. To examine explainability, we devise a strategy that generates rationales for the scores and analyzes the characteristics of the explanation produced by the open-source LLMs. Extensive experiments provide insights regarding evaluation capabilities of open-source LLMs and suggest effective prompting strategies.