 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Free Multimodal Learned Sparse Retrieval for Production-Scale Visual Document Search
May 29, 2026As large-scale visual-document corpora such as arXiv papers and enterprise PDFs continue to grow, visual-document retrieval has gained increasing attention; yet it still lacks a deployable system that lexically indexes visual documents to serve queries without neural encoding at scale. Existing methods either achieve strong retrieval quality with VLM-based dense or multi-vector models but require neural query encoding at serving time, or avoid query encoding with OCR- or caption-based BM25 at the cost of time-consuming text extraction or generation. To fill this missing serving regime, we present V-SPLADE, an inference-free sparse retriever for visual-document retrieval. However, such inference-free multimodal learned sparse retrieval systems remain underexplored and have not yet shown dense-level effectiveness under high sparsity. We attribute this limitation to a lexical grounding problem: visual sparse representations often fail to capture the lexical content embedded in document images. To address this problem, we introduce caption-gated token supervision, a training-only signal that uses VLM-generated captions as lexical cues to activate retrieval-relevant vocabulary dimensions. With this supervision, V-SPLADE improves average NDCG@5 across six visual-document retrieval benchmarks by +13.8pp over the same-scale dense baseline and by up to +6.3pp over OCR- or caption-based BM25 baselines. On an 18.7M-document corpus, it more than doubles R@5 over the same-scale dense baseline and further improves competing retrievers through score fusion by up to +2.4pp R@5. Code will be released soon at https://github.com/naver/v-splade.
Domain Adaptation of Attention Heads for Zero-shot Anomaly Detection
May 28, 2025

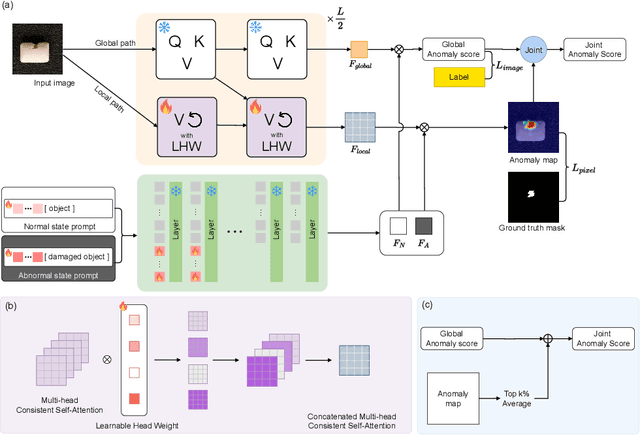

Zero-shot anomaly detection (ZSAD) in images is an approach that can detect anomalies without access to normal samples, which can be beneficial in various realistic scenarios where model training is not possible. However, existing ZSAD research has shown limitations by either not considering domain adaptation of general-purpose backbone models to anomaly detection domains or by implementing only partial adaptation to some model components. In this paper, we propose HeadCLIP to overcome these limitations by effectively adapting both text and image encoders to the domain. HeadCLIP generalizes the concepts of normality and abnormality through learnable prompts in the text encoder, and introduces learnable head weights to the image encoder to dynamically adjust the features held by each attention head according to domain characteristics. Additionally, we maximize the effect of domain adaptation by introducing a joint anomaly score that utilizes domain-adapted pixel-level information for image-level anomaly detection. Experimental results using multiple real datasets in both industrial and medical domains show that HeadCLIP outperforms existing ZSAD techniques at both pixel and image levels. In the industrial domain, improvements of up to 4.9%p in pixel-level mean anomaly detection score (mAD) and up to 3.0%p in image-level mAD were achieved, with similar improvements (3.2%p, 3.1%p) in the medical domain.
Technical Report of NICE Challenge at CVPR 2024: Caption Re-ranking Evaluation Using Ensembled CLIP and Consensus Scores
May 02, 2024
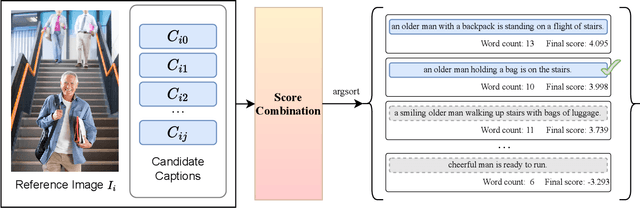

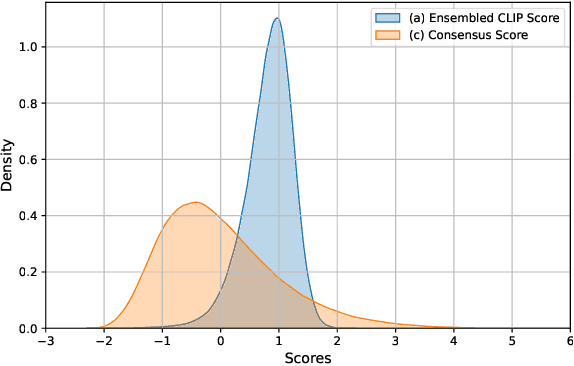
This report presents the ECO (Ensembled Clip score and cOnsensus score) pipeline from team DSBA LAB, which is a new framework used to evaluate and rank captions for a given image. ECO selects the most accurate caption describing image. It is made possible by combining an Ensembled CLIP score, which considers the semantic alignment between the image and captions, with a Consensus score that accounts for the essentialness of the captions. Using this framework, we achieved notable success in the CVPR 2024 Workshop Challenge on Caption Re-ranking Evaluation at the New Frontiers for Zero-Shot Image Captioning Evaluation (NICE). Specifically, we secured third place based on the CIDEr metric, second in both the SPICE and METEOR metrics, and first in the ROUGE-L and all BLEU Score metrics. The code and configuration for the ECO framework are available at https://github.com/ DSBA-Lab/ECO .
Which is better? Exploring Prompting Strategy For LLM-based Metrics
Nov 07, 2023This paper describes the DSBA submissions to the Prompting Large Language Models as Explainable Metrics shared task, where systems were submitted to two tracks: small and large summarization tracks. With advanced Large Language Models (LLMs) such as GPT-4, evaluating the quality of Natural Language Generation (NLG) has become increasingly paramount. Traditional similarity-based metrics such as BLEU and ROUGE have shown to misalign with human evaluation and are ill-suited for open-ended generation tasks. To address this issue, we explore the potential capability of LLM-based metrics, especially leveraging open-source LLMs. In this study, wide range of prompts and prompting techniques are systematically analyzed with three approaches: prompting strategy, score aggregation, and explainability. Our research focuses on formulating effective prompt templates, determining the granularity of NLG quality scores and assessing the impact of in-context examples on LLM-based evaluation. Furthermore, three aggregation strategies are compared to identify the most reliable method for aggregating NLG quality scores. To examine explainability, we devise a strategy that generates rationales for the scores and analyzes the characteristics of the explanation produced by the open-source LLMs. Extensive experiments provide insights regarding evaluation capabilities of open-source LLMs and suggest effective prompting strategies.