 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheckEval: Robust Evaluation Framework using Large Language Model via Checklist
Paper and Code
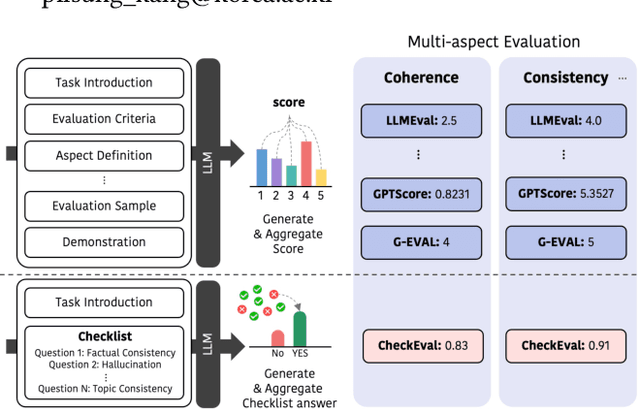
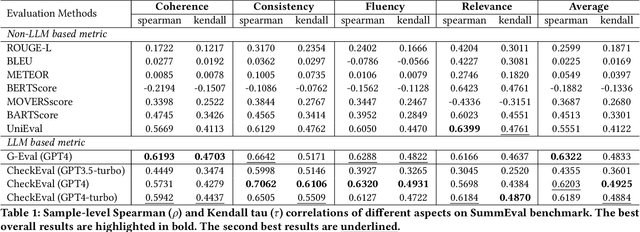
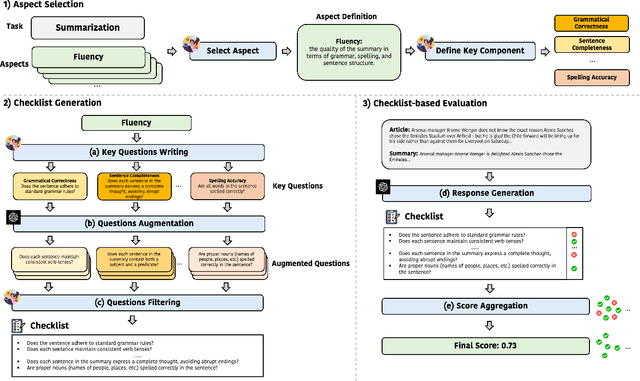
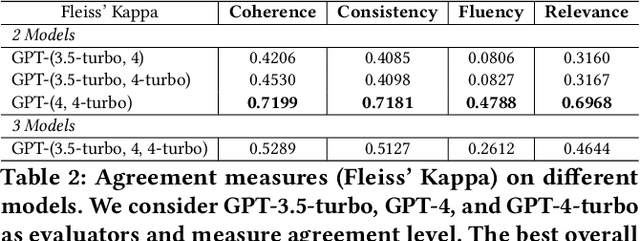
We introduce CheckEval, a novel evaluation framework using Large Language Models, addressing the challenges of ambiguity and inconsistency in current evaluation methods. CheckEval addresses these challenges by dividing evaluation criteria into detailed sub-aspects and constructing a checklist of Boolean questions for each, simplifying the evaluation. This approach not only renders the process more interpretable but also significantly enhances the robustness and reliability of results by focusing on specific evaluation dimensions. Validated through a focused case study using the SummEval benchmark, CheckEval indicates a strong correlation with human judgments. Furthermore, it demonstrates a highly consistent Inter-Annotator Agreement. These findings highlight the effectiveness of CheckEval for objective, flexible, and precise evaluations. By offering a customizable and interactive framework, CheckEval sets a new standard for the use of LLMs in evaluation, responding to the evolving needs of the field and establishing a clear method for future LLM-based evaluation.