 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Adaptation Using Universal Dependencies
Paper and Code
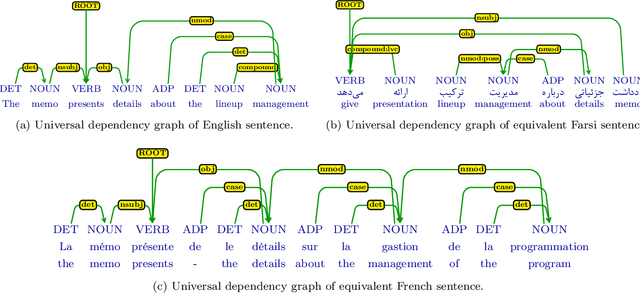

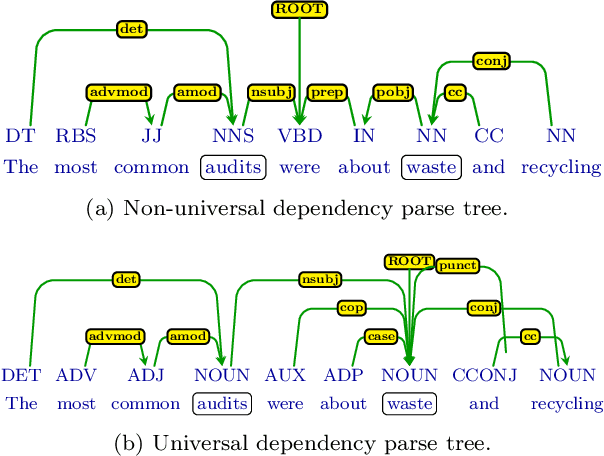
We describe a cross-lingual adaptation method based on syntactic parse trees obtained from the Universal Dependencies (UD), which are consistent across languages, to develop classifiers in low-resource languages. The idea of UD parsing is to capture similarities as well as idiosyncrasies among typologically different languages. In this paper, we show that models trained using UD parse trees for complex NLP tasks can characterize very different languages. We study two tasks of paraphrase identification and semantic relation extraction as case studies. Based on UD parse trees, we develop several models using tree kernels and show that these models trained on the English dataset can correctly classify data of other languages e.g. French, Farsi, and Arabic. The proposed approach opens up avenues for exploiting UD parsing in solving similar cross-lingual tasks, which is very useful for languages that no labeled data is available for them.