 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINA-BERT: A pre-trained Language Model for Analysis of Medical Texts in Persian
Apr 15, 2021
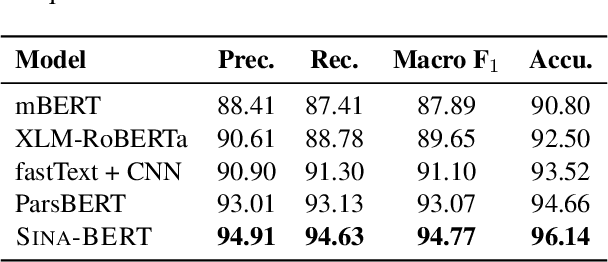
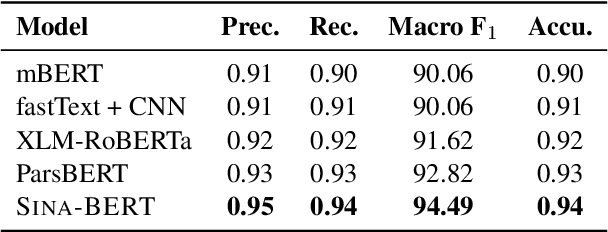
We have released Sina-BERT, a language model pre-trained on BERT (Devlin et al., 2018) to address the lack of a high-quality Persian language model in the medical domain. SINA-BERT utilizes pre-training on a large-scale corpus of medical contents including formal and informal texts collected from a variety of online resources in order to improve the performance on health-care related tasks. We employ SINA-BERT to complete following representative tasks: categorization of medical questions, medical sentiment analysis, and medical question retrieval. For each task, we have developed Persian annotated data sets for training and evaluation and learnt a representation for the data of each task especially complex and long medical questions. With the same architecture being used across tasks, SINA-BERT outperforms BERT-based models that were previously made available in the Persian language.
Cross-Lingual Adaptation Using Universal Dependencies
Mar 28, 2020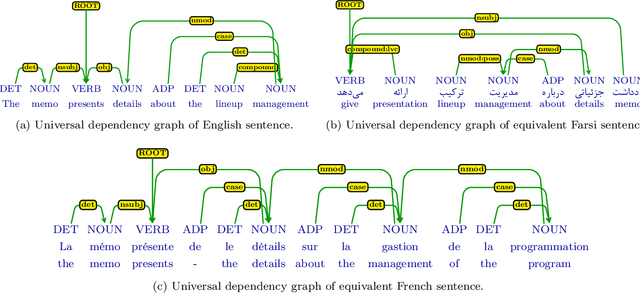

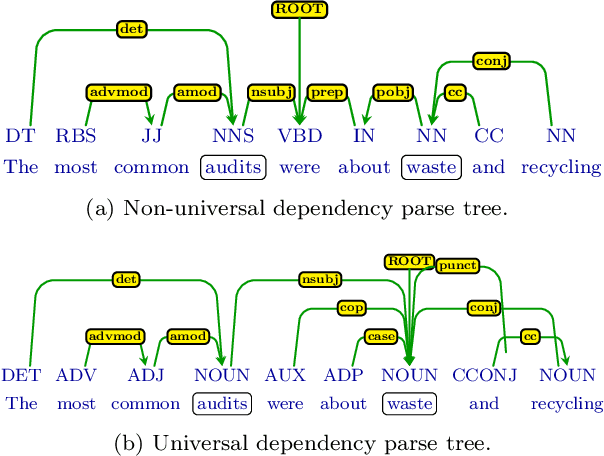
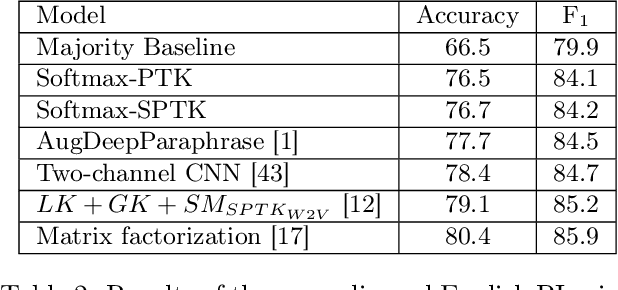
We describe a cross-lingual adaptation method based on syntactic parse trees obtained from the Universal Dependencies (UD), which are consistent across languages, to develop classifiers in low-resource languages. The idea of UD parsing is to capture similarities as well as idiosyncrasies among typologically different languages. In this paper, we show that models trained using UD parse trees for complex NLP tasks can characterize very different languages. We study two tasks of paraphrase identification and semantic relation extraction as case studies. Based on UD parse trees, we develop several models using tree kernels and show that these models trained on the English dataset can correctly classify data of other languages e.g. French, Farsi, and Arabic. The proposed approach opens up avenues for exploiting UD parsing in solving similar cross-lingual tasks, which is very useful for languages that no labeled data is available for them.
NSURL-2019 Task 7: Named Entity Recognition in Farsi
Mar 19, 2020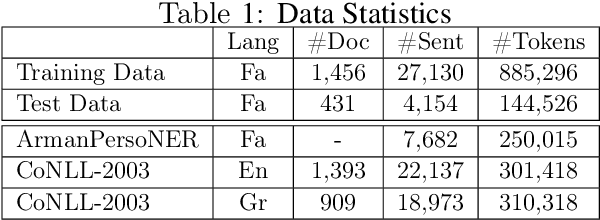
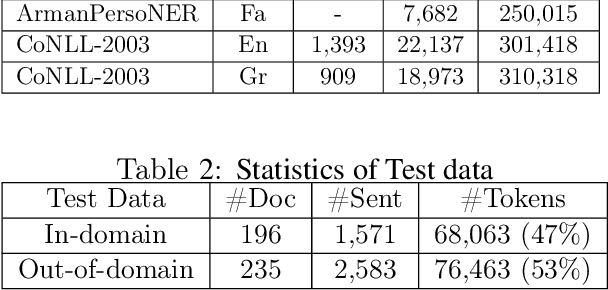
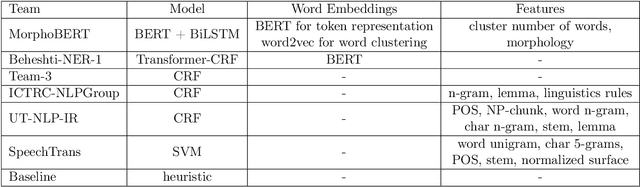

NSURL-2019 Task 7 focuses on Named Entity Recognition (NER) in Farsi. This task was chosen to compare different approaches to find phrases that specify Named Entities in Farsi texts, and to establish a standard testbed for future researches on this task in Farsi. This paper describes the process of making training and test data, a list of participating teams (6 teams), and evaluation results of their systems. The best system obtained 85.4% of F1 score based on phrase-level evaluation on seven classes of NEs including person, organization, location, date, time, money and percent.