 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatina: A Large-Scale 73B Token Persian Text Corpus
Feb 13, 2025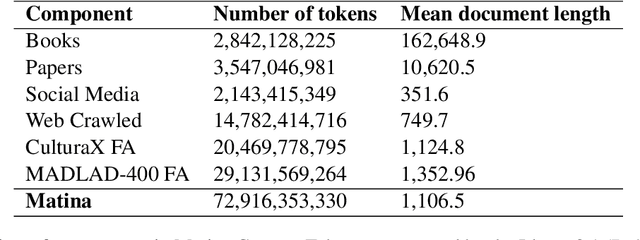
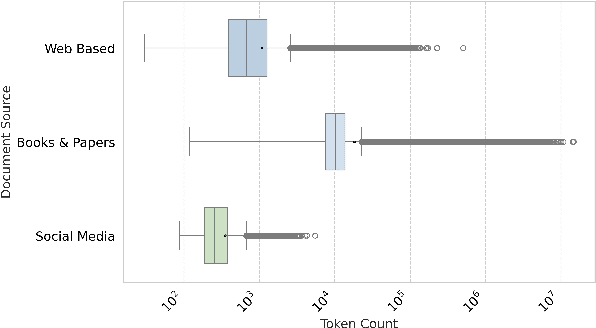

Text corpora are essential for training models used in tasks like summarization, translation, and large language models (LLMs). While various efforts have been made to collect monolingual and multilingual datasets in many languages, Persian has often been underrepresented due to limited resources for data collection and preprocessing. Existing Persian datasets are typically small and lack content diversity, consisting mainly of weblogs and news articles. This shortage of high-quality, varied data has slowed the development of NLP models and open-source LLMs for Persian. Since model performance depends heavily on the quality of training data, we address this gap by introducing the Matina corpus, a new Persian dataset of 72.9B tokens, carefully preprocessed and deduplicated to ensure high data quality. We further assess its effectiveness by training and evaluating transformer-based models on key NLP tasks. Both the dataset and preprocessing codes are publicly available, enabling researchers to build on and improve this resource for future Persian NLP advancements.
Advancing Retrieval-Augmented Generation for Persian: Development of Language Models, Comprehensive Benchmarks, and Best Practices for Optimization
Jan 08, 2025This paper examines the specific obstacles of constructing Retrieval-Augmented Generation(RAG) systems in low-resource languages, with a focus on Persian's complicated morphology and versatile syntax. The research aims to improve retrieval and generation accuracy by introducing Persian-specific models, namely MatinaRoberta(a masked language model) and MatinaSRoberta(a fine-tuned Sentence-BERT), along with a comprehensive benchmarking framework. Three datasets-general knowledge(PQuad), scientifically specialized texts, and organizational reports, were used to assess these models after they were trained on a varied corpus of 73.11 billion Persian tokens. The methodology involved extensive pretraining, fine-tuning with tailored loss functions, and systematic evaluations using both traditional metrics and the Retrieval-Augmented Generation Assessment framework. The results show that MatinaSRoberta outperformed previous embeddings, achieving superior contextual relevance and retrieval accuracy across datasets. Temperature tweaking, chunk size modifications, and document summary indexing were explored to enhance RAG setups. Larger models like Llama-3.1 (70B) consistently demonstrated the highest generation accuracy, while smaller models faced challenges with domain-specific and formal contexts. The findings underscore the potential for developing RAG systems in Persian through customized embeddings and retrieval-generation settings and highlight the enhancement of NLP applications such as search engines and legal document analysis in low-resource languages.