 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatina: A Large-Scale 73B Token Persian Text Corpus
Paper and Code
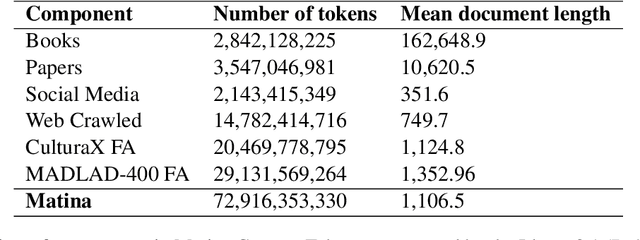
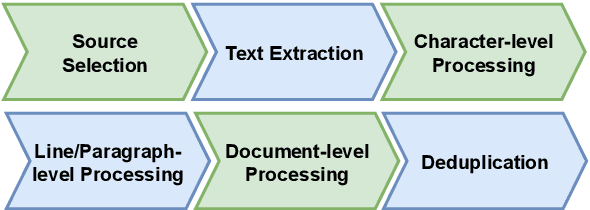
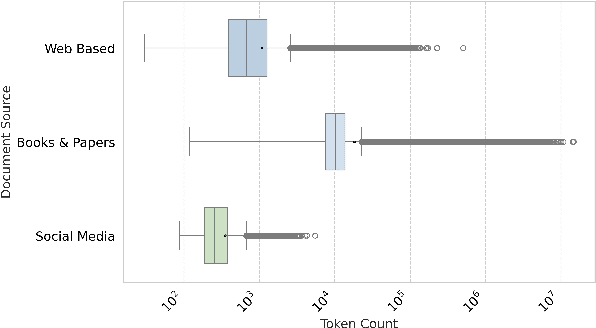

Text corpora are essential for training models used in tasks like summarization, translation, and large language models (LLMs). While various efforts have been made to collect monolingual and multilingual datasets in many languages, Persian has often been underrepresented due to limited resources for data collection and preprocessing. Existing Persian datasets are typically small and lack content diversity, consisting mainly of weblogs and news articles. This shortage of high-quality, varied data has slowed the development of NLP models and open-source LLMs for Persian. Since model performance depends heavily on the quality of training data, we address this gap by introducing the Matina corpus, a new Persian dataset of 72.9B tokens, carefully preprocessed and deduplicated to ensure high data quality. We further assess its effectiveness by training and evaluating transformer-based models on key NLP tasks. Both the dataset and preprocessing codes are publicly available, enabling researchers to build on and improve this resource for future Persian NLP advancements.