 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance Multimodal Consistency and Coherence for Text-Image Plan Generation
Jun 13, 2025People get informed of a daily task plan through diverse media involving both texts and images. However, most prior research only focuses on LLM's capability of textual plan generation. The potential of large-scale models in providing text-image plans remains understudied. Generating high-quality text-image plans faces two main challenges: ensuring consistent alignment between two modalities and keeping coherence among visual steps. To address these challenges, we propose a novel framework that generates and refines text-image plans step-by-step. At each iteration, our framework (1) drafts the next textual step based on the prediction history; (2) edits the last visual step to obtain the next one; (3) extracts PDDL-like visual information; and (4) refines the draft with the extracted visual information. The textual and visual step produced in stage (4) and (2) will then serve as inputs for the next iteration. Our approach offers a plug-and-play improvement to various backbone models, such as Mistral-7B, Gemini-1.5, and GPT-4o. To evaluate the effectiveness of our approach, we collect a new benchmark consisting of 1,100 tasks and their text-image pair solutions covering 11 daily topics. We also design and validate a new set of metrics to evaluate the multimodal consistency and coherence in text-image plans. Extensive experiment results show the effectiveness of our approach on a range of backbone models against competitive baselines. Our code and data are available at https://github.com/psunlpgroup/MPlanner.
HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
Apr 29, 2025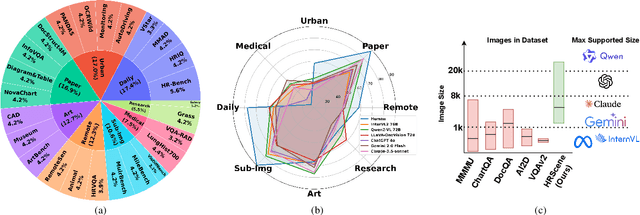
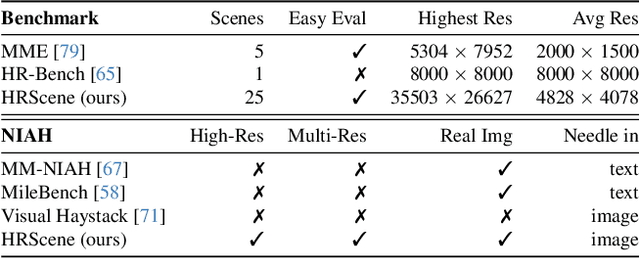
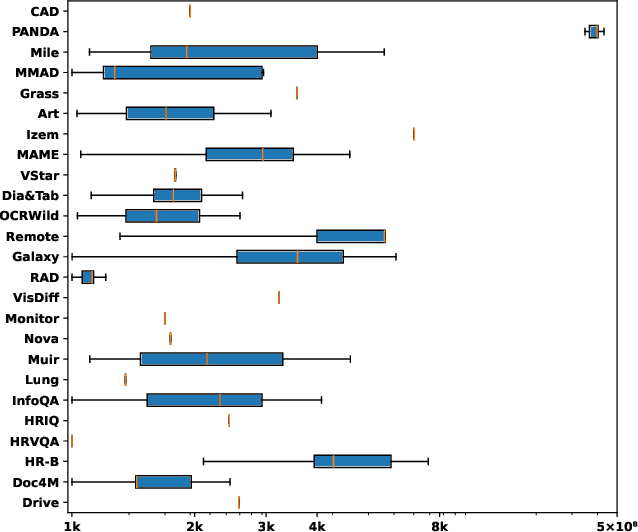
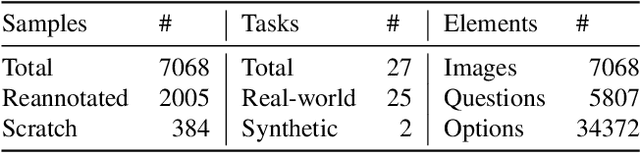
High-resolution image (HRI) understanding aims to process images with a large number of pixels, such as pathological images and agricultural aerial images, both of which can exceed 1 million pixels. Vision Large Language Models (VLMs) can allegedly handle HRIs, however, there is a lack of a comprehensive benchmark for VLMs to evaluate HRI understanding. To address this gap, we introduce HRScene, a novel unified benchmark for HRI understanding with rich scenes. HRScene incorporates 25 real-world datasets and 2 synthetic diagnostic datasets with resolutions ranging from 1,024 $\times$ 1,024 to 35,503 $\times$ 26,627. HRScene is collected and re-annotated by 10 graduate-level annotators, covering 25 scenarios, ranging from microscopic to radiology images, street views, long-range pictures, and telescope images. It includes HRIs of real-world objects, scanned documents, and composite multi-image. The two diagnostic evaluation datasets are synthesized by combining the target image with the gold answer and distracting images in different orders, assessing how well models utilize regions in HRI. We conduct extensive experiments involving 28 VLMs, including Gemini 2.0 Flash and GPT-4o. Experiments on HRScene show that current VLMs achieve an average accuracy of around 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on synthetic datasets reveal that VLMs struggle to effectively utilize HRI regions, showing significant Regional Divergence and lost-in-middle, shedding light on future research.
AAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024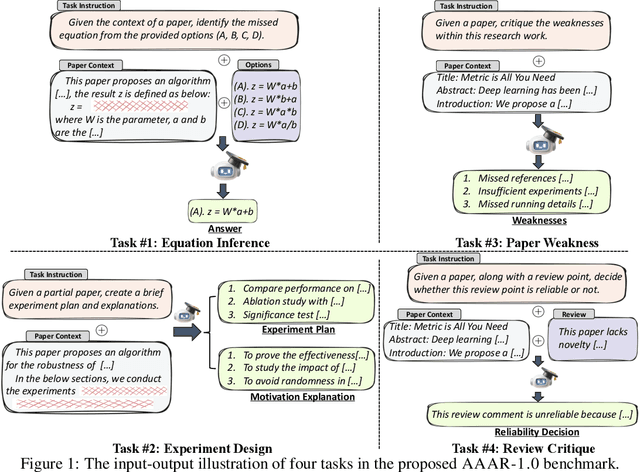
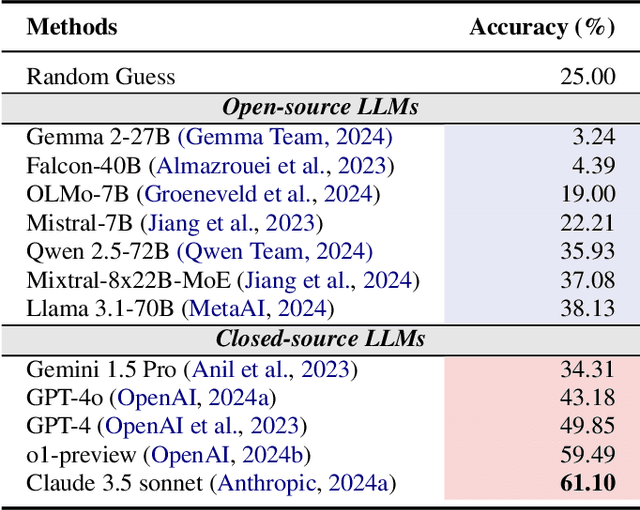
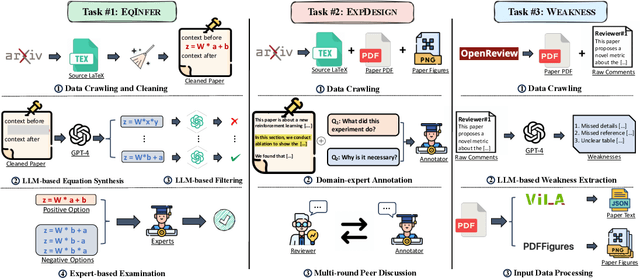
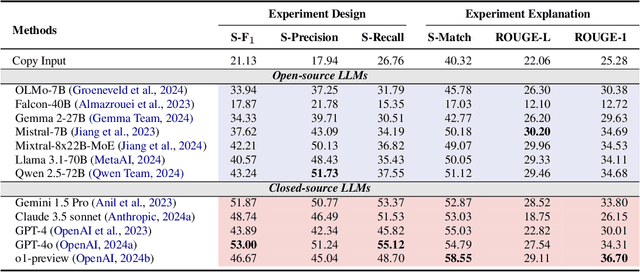
Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
Evaluating LLMs at Detecting Errors in LLM Responses
Apr 04, 2024



With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.
Fair Abstractive Summarization of Diverse Perspectives
Nov 14, 2023



People from different social and demographic groups express diverse perspectives and conflicting opinions on a broad set of topics such as product reviews, healthcare, law, and politics. A fair summary should provide a comprehensive coverage of diverse perspectives without underrepresenting certain groups. However, current work in summarization metrics and Large Language Models (LLMs) evaluation has not explored fair abstractive summarization. In this paper, we systematically investigate fair abstractive summarization for user-generated data. We first formally define fairness in abstractive summarization as not underrepresenting perspectives of any groups of people and propose four reference-free automatic metrics measuring the differences between target and source perspectives. We evaluate five LLMs, including three GPT models, Alpaca, and Claude, on six datasets collected from social media, online reviews, and recorded transcripts. Experiments show that both the model-generated and the human-written reference summaries suffer from low fairness. We conduct a comprehensive analysis of the common factors influencing fairness and propose three simple but effective methods to alleviate unfair summarization. Our dataset and code are available at https://github.com/psunlpgroup/FairSumm.
Doctor Recommendation in Online Health Forums via Expertise Learning
Mar 14, 2022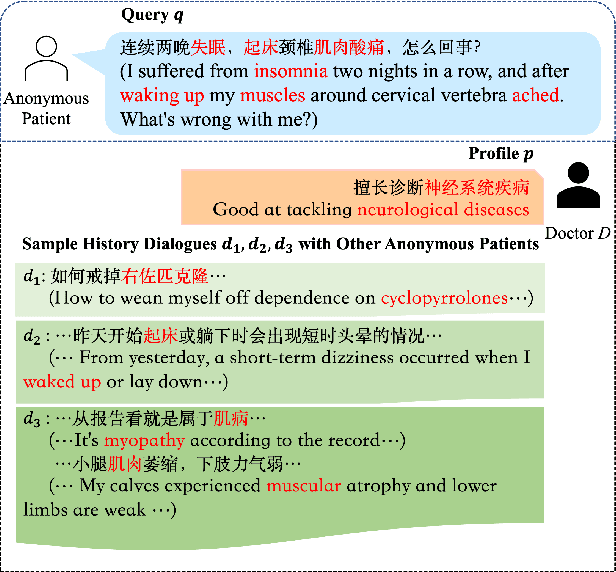
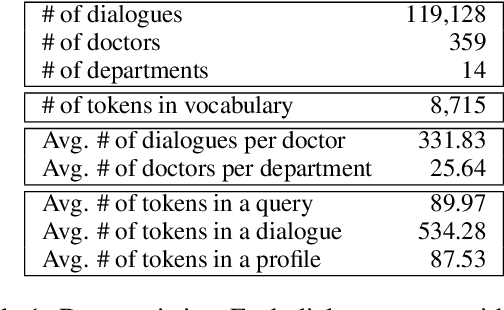
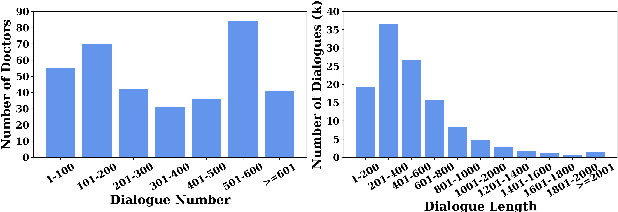
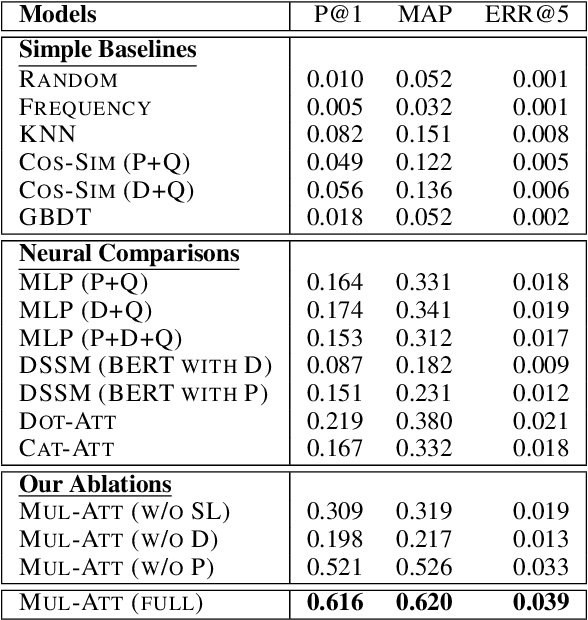
Huge volumes of patient queries are daily generated on online health forums, rendering manual doctor allocation a labor-intensive task. To better help patients, this paper studies a novel task of doctor recommendation to enable automatic pairing of a patient to a doctor with relevant expertise. While most prior work in recommendation focuses on modeling target users from their past behavior, we can only rely on the limited words in a query to infer a patient's needs for privacy reasons. For doctor modeling, we study the joint effects of their profiles and previous dialogues with other patients and explore their interactions via self-learning. The learned doctor embeddings are further employed to estimate their capabilities of handling a patient query with a multi-head attention mechanism. For experiments, a large-scale dataset is collected from Chunyu Yisheng, a Chinese online health forum, where our model exhibits the state-of-the-art results, outperforming baselines only consider profiles and past dialogues to characterize a doctor.