 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024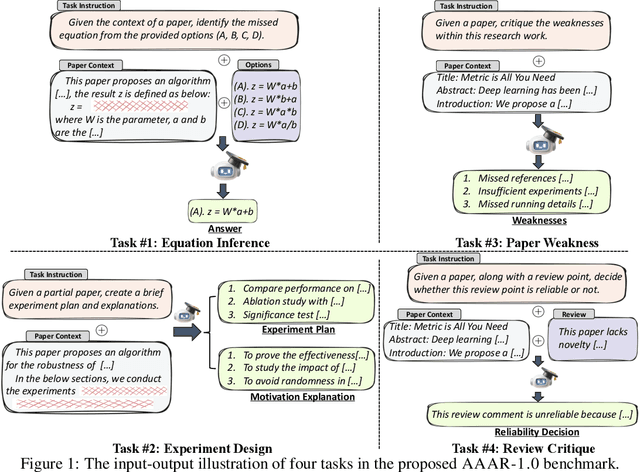
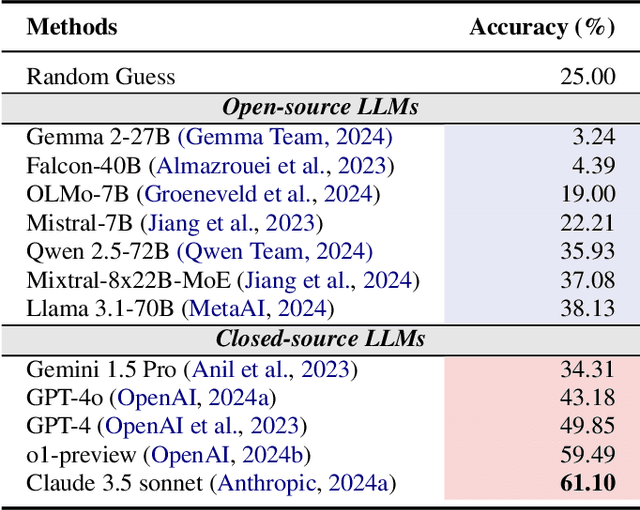
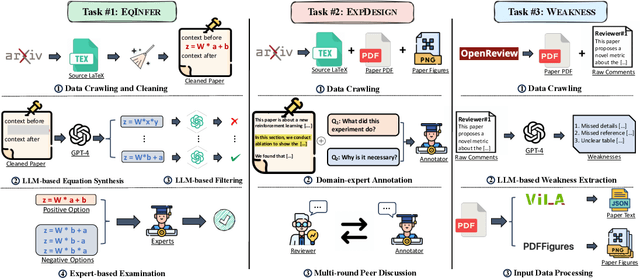
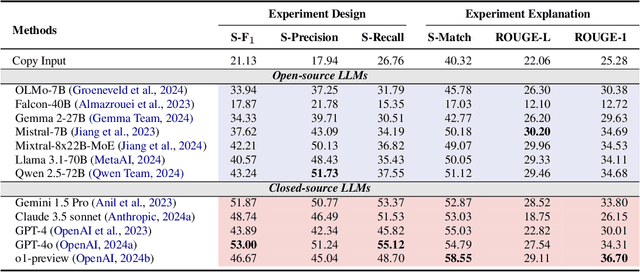
Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
LLMs' Classification Performance is Overclaimed
Jun 23, 2024In many classification tasks designed for AI or human to solve, gold labels are typically included within the label space by default, often posed as "which of the following is correct?" This standard setup has traditionally highlighted the strong performance of advanced AI, particularly top-performing Large Language Models (LLMs), in routine classification tasks. However, when the gold label is intentionally excluded from the label space, it becomes evident that LLMs still attempt to select from the available label candidates, even when none are correct. This raises a pivotal question: Do LLMs truly demonstrate their intelligence in understanding the essence of classification tasks? In this study, we evaluate both closed-source and open-source LLMs across representative classification tasks, arguing that the perceived performance of LLMs is overstated due to their inability to exhibit the expected comprehension of the task. This paper makes a threefold contribution: i) To our knowledge, this is the first work to identify the limitations of LLMs in classification tasks when gold labels are absent. We define this task as Classify-w/o-Gold and propose it as a new testbed for LLMs. ii) We introduce a benchmark, Know-No, comprising two existing classification tasks and one new task, to evaluate Classify-w/o-Gold. iii) This work defines and advocates for a new evaluation metric, OmniAccuracy, which assesses LLMs' performance in classification tasks both when gold labels are present and absent.
X-Shot: A Unified System to Handle Frequent, Few-shot and Zero-shot Learning Simultaneously in Classification
Mar 06, 2024



In recent years, few-shot and zero-shot learning, which learn to predict labels with limited annotated instances, have garnered significant attention. Traditional approaches often treat frequent-shot (freq-shot; labels with abundant instances), few-shot, and zero-shot learning as distinct challenges, optimizing systems for just one of these scenarios. Yet, in real-world settings, label occurrences vary greatly. Some of them might appear thousands of times, while others might only appear sporadically or not at all. For practical deployment, it is crucial that a system can adapt to any label occurrence. We introduce a novel classification challenge: X-shot, reflecting a real-world context where freq-shot, few-shot, and zero-shot labels co-occur without predefined limits. Here, X can span from 0 to positive infinity. The crux of X-shot centers on open-domain generalization and devising a system versatile enough to manage various label scenarios. To solve X-shot, we propose BinBin (Binary INference Based on INstruction following) that leverages the Indirect Supervision from a large collection of NLP tasks via instruction following, bolstered by Weak Supervision provided by large language models. BinBin surpasses previous state-of-the-art techniques on three benchmark datasets across multiple domains. To our knowledge, this is the first work addressing X-shot learning, where X remains variable.
MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction-Following
Dec 05, 2023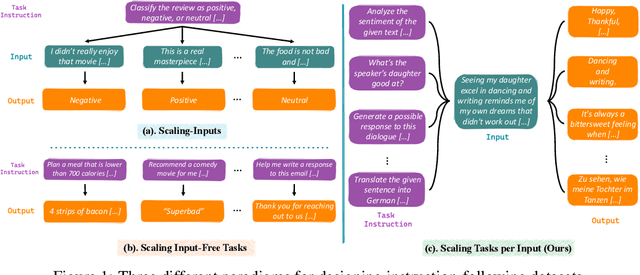

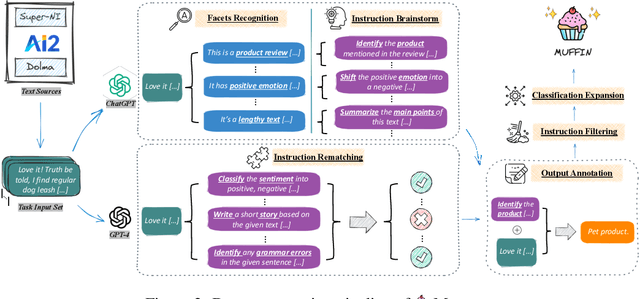
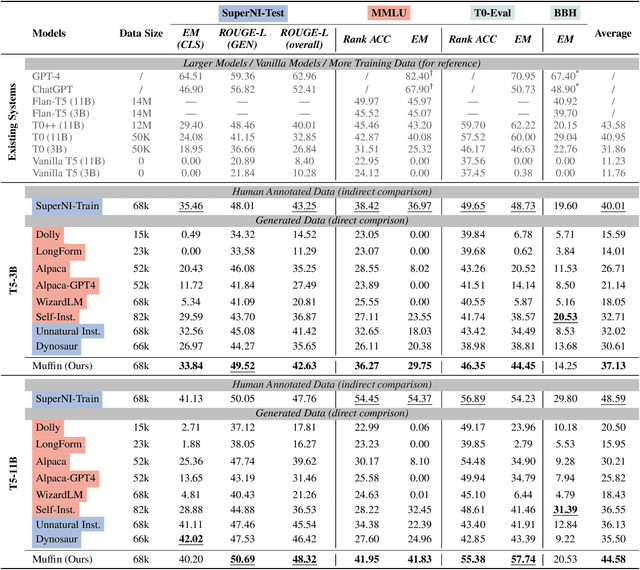
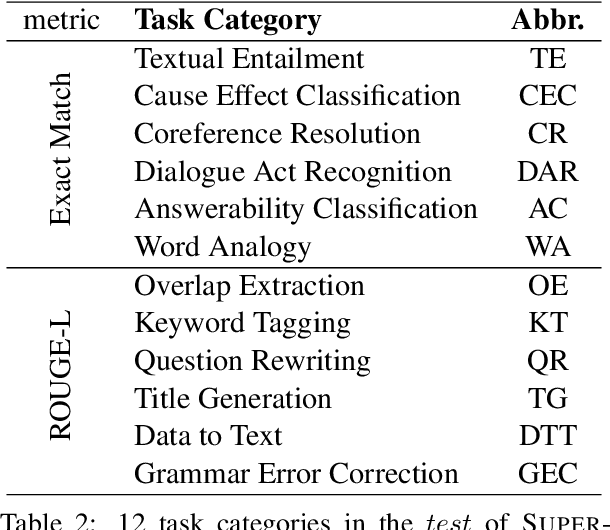
In the realm of large language models (LLMs), enhancing instruction-following capability often involves curating expansive training data. This is achieved through two primary schemes: i) Scaling-Inputs: Amplifying (input, output) pairs per task instruction, aiming for better instruction adherence. ii) Scaling Input-Free Tasks: Enlarging tasks, each composed of an (instruction, output) pair (without requiring a separate input anymore). However, LLMs under Scaling-Inputs tend to be overly sensitive to inputs, leading to misinterpretation or non-compliance with instructions. Conversely, Scaling Input-Free Tasks demands a substantial number of tasks but is less effective in instruction following when dealing with instances in Scaling-Inputs. This work introduces MUFFIN, a new scheme of instruction-following dataset curation. Specifically, we automatically Scale Tasks per Input by diversifying these tasks with various input facets. Experimental results across four zero-shot benchmarks, spanning both Scaling-Inputs and Scaling Input-Free Tasks schemes, reveal that LLMs, at various scales, trained on MUFFIN generally demonstrate superior instruction-following capabilities compared to those trained on the two aforementioned schemes.
Robustness of Learning from Task Instructions
Dec 07, 2022
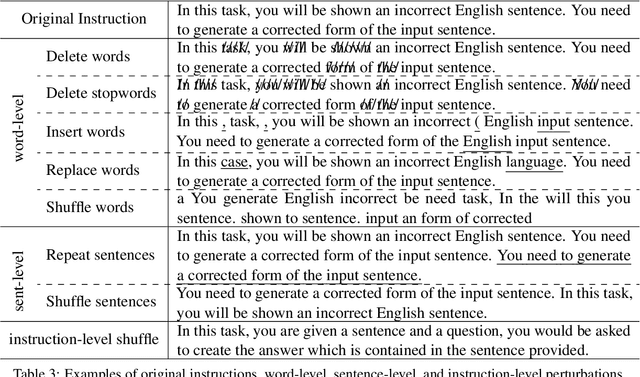
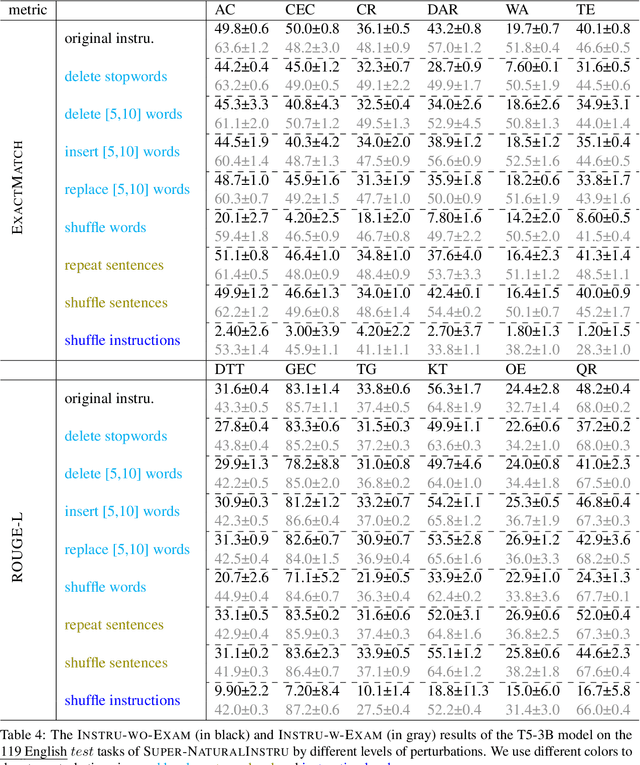
Traditional supervised learning mostly works on individual tasks and requires training on a large set of task-specific examples. This paradigm seriously hinders the development of task generalization since preparing a task-specific example set is costly. To build a system that can quickly and easily generalize to new tasks, task instructions have been adopted as an emerging trend of supervision recently. These instructions give the model the definition of the task and allow the model to output the appropriate answer based on the instructions and inputs. However, task instructions are often expressed in different forms, which can be interpreted from two threads: first, some instructions are short sentences and are pretrained language model (PLM) oriented, such as prompts, while other instructions are paragraphs and are human-oriented, such as those in Amazon MTurk; second, different end-users very likely explain the same task with instructions of different textual expressions. A robust system for task generalization should be able to handle any new tasks regardless of the variability of instructions. However, the system robustness in dealing with instruction-driven task generalization is still unexplored. This work investigates the system robustness when the instructions of new tasks are (i) maliciously manipulated, (ii) paraphrased, or (iii) from different levels of conciseness. To our knowledge, this is the first work that systematically studies how robust a PLM is when it is supervised by instructions with different factors of variability.
OpenStance: Real-world Zero-shot Stance Detection
Oct 25, 2022Prior studies of zero-shot stance detection identify the attitude of texts towards unseen topics occurring in the same document corpus. Such task formulation has three limitations: (i) Single domain/dataset. A system is optimized on a particular dataset from a single domain; therefore, the resulting system cannot work well on other datasets; (ii) the model is evaluated on a limited number of unseen topics; (iii) it is assumed that part of the topics has rich annotations, which might be impossible in real-world applications. These drawbacks will lead to an impractical stance detection system that fails to generalize to open domains and open-form topics. This work defines OpenStance: open-domain zero-shot stance detection, aiming to handle stance detection in an open world with neither domain constraints nor topic-specific annotations. The key challenge of OpenStance lies in the open-domain generalization: learning a system with fully unspecific supervision but capable of generalizing to any dataset. To solve OpenStance, we propose to combine indirect supervision, from textual entailment datasets, and weak supervision, from data generated automatically by pre-trained Language Models. Our single system, without any topic-specific supervision, outperforms the supervised method on three popular datasets. To our knowledge, this is the first work that studies stance detection under the open-domain zero-shot setting. All data and code are publicly released.
Bone marrow sparing for cervical cancer radiotherapy on multimodality medical images
Apr 20, 2022
Cervical cancer threatens the health of women seriously. Radiotherapy is one of the main therapy methods but with high risk of acute hematologic toxicity. Delineating the bone marrow (BM) for sparing using computer tomography (CT) images to plan before radiotherapy can effectively avoid this risk. Comparing with magnetic resonance (MR) images, CT lacks the ability to express the activity of BM. Thus, in current clinical practice, medical practitioners manually delineate the BM on CT images by corresponding to MR images. However, the time?consuming delineating BM by hand cannot guarantee the accuracy due to the inconsistency of the CT-MR multimodal images. In this study, we propose a multimodal image oriented automatic registration method for pelvic BM sparing, which consists of three-dimensional bone point cloud reconstruction, a local spherical system iteration closest point registration for marking BM on CT images. Experiments on patient dataset reveal that our proposed method can enhance the multimodal image registration accuracy and efficiency for medical practitioners in sparing BM of cervical cancer radiotherapy. The method proposed in this contribution might also provide references for similar studies in other clinical application.