 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
Enhancing CTR Prediction in Recommendation Domain with Search Query Representation
Oct 28, 2024
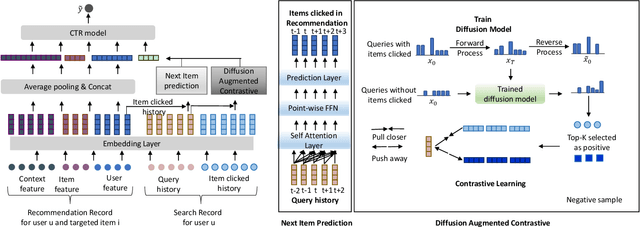
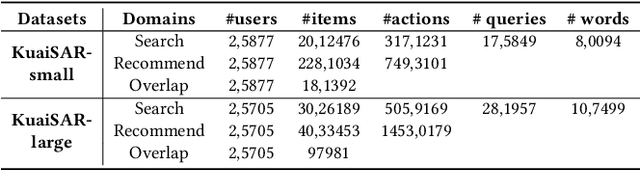
Many platforms, such as e-commerce websites, offer both search and recommendation services simultaneously to better meet users' diverse needs. Recommendation services suggest items based on user preferences, while search services allow users to search for items before providing recommendations. Since users and items are often shared between the search and recommendation domains, there is a valuable opportunity to enhance the recommendation domain by leveraging user preferences extracted from the search domain. Existing approaches either overlook the shift in user intention between these domains or fail to capture the significant impact of learning from users' search queries on understanding their interests. In this paper, we propose a framework that learns from user search query embeddings within the context of user preferences in the recommendation domain. Specifically, user search query sequences from the search domain are used to predict the items users will click at the next time point in the recommendation domain. Additionally, the relationship between queries and items is explored through contrastive learning. To address issues of data sparsity, the diffusion model is incorporated to infer positive items the user will select after searching with certain queries in a denoising manner, which is particularly effective in preventing false positives. Effectively extracting this information, the queries are integrated into click-through rate prediction in the recommendation domain. Experimental analysis demonstrates that our model outperforms state-of-the-art models in the recommendation domain.
* Accepted by CIKM 2024 Full Research Track
Personalized Negative Reservoir for Incremental Learning in Recommender Systems
Mar 06, 2024



Recommender systems have become an integral part of online platforms. Every day the volume of training data is expanding and the number of user interactions is constantly increasing. The exploration of larger and more expressive models has become a necessary pursuit to improve user experience. However, this progression carries with it an increased computational burden. In commercial settings, once a recommendation system model has been trained and deployed it typically needs to be updated frequently as new client data arrive. Cumulatively, the mounting volume of data is guaranteed to eventually make full batch retraining of the model from scratch computationally infeasible. Naively fine-tuning solely on the new data runs into the well-documented problem of catastrophic forgetting. Despite the fact that negative sampling is a crucial part of training with implicit feedback, no specialized technique exists that is tailored to the incremental learning framework. In this work, we take the first step to propose, a personalized negative reservoir strategy which is used to obtain negative samples for the standard triplet loss. This technique balances alleviation of forgetting with plasticity by encouraging the model to remember stable user preferences and selectively forget when user interests change. We derive the mathematical formulation of a negative sampler to populate and update the reservoir. We integrate our design in three SOTA and commonly used incremental recommendation models. We show that these concrete realizations of our negative reservoir framework achieve state-of-the-art results in standard benchmarks, on multiple standard top-k evaluation metrics.
Structure Aware Incremental Learning with Personalized Imitation Weights for Recommender Systems
May 02, 2023



Recommender systems now consume large-scale data and play a significant role in improving user experience. Graph Neural Networks (GNNs) have emerged as one of the most effective recommender system models because they model the rich relational information. The ever-growing volume of data can make training GNNs prohibitively expensive. To address this, previous attempts propose to train the GNN models incrementally as new data blocks arrive. Feature and structure knowledge distillation techniques have been explored to allow the GNN model to train in a fast incremental fashion while alleviating the catastrophic forgetting problem. However, preserving the same amount of the historical information for all users is sub-optimal since it fails to take into account the dynamics of each user's change of preferences. For the users whose interests shift substantially, retaining too much of the old knowledge can overly constrain the model, preventing it from quickly adapting to the users' novel interests. In contrast, for users who have static preferences, model performance can benefit greatly from preserving as much of the user's long-term preferences as possible. In this work, we propose a novel training strategy that adaptively learns personalized imitation weights for each user to balance the contribution from the recent data and the amount of knowledge to be distilled from previous time periods. We demonstrate the effectiveness of learning imitation weights via a comparison on five diverse datasets for three state-of-art structure distillation based recommender systems. The performance shows consistent improvement over competitive incremental learning techninques.
Bone marrow sparing for cervical cancer radiotherapy on multimodality medical images
Apr 20, 2022
Cervical cancer threatens the health of women seriously. Radiotherapy is one of the main therapy methods but with high risk of acute hematologic toxicity. Delineating the bone marrow (BM) for sparing using computer tomography (CT) images to plan before radiotherapy can effectively avoid this risk. Comparing with magnetic resonance (MR) images, CT lacks the ability to express the activity of BM. Thus, in current clinical practice, medical practitioners manually delineate the BM on CT images by corresponding to MR images. However, the time?consuming delineating BM by hand cannot guarantee the accuracy due to the inconsistency of the CT-MR multimodal images. In this study, we propose a multimodal image oriented automatic registration method for pelvic BM sparing, which consists of three-dimensional bone point cloud reconstruction, a local spherical system iteration closest point registration for marking BM on CT images. Experiments on patient dataset reveal that our proposed method can enhance the multimodal image registration accuracy and efficiency for medical practitioners in sparing BM of cervical cancer radiotherapy. The method proposed in this contribution might also provide references for similar studies in other clinical application.