 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAIDX: A Retrieval-Augmented Generation and GRPO Reinforcement Learning Framework for Explainable Deepfake Detection
Aug 06, 2025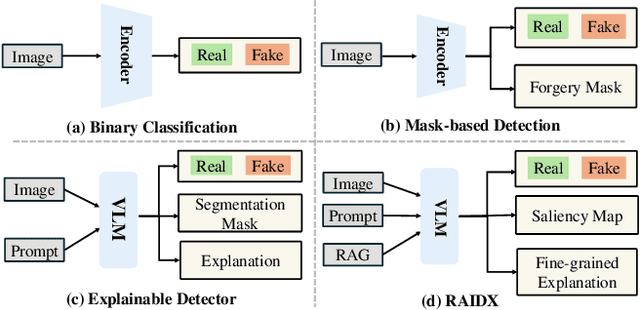
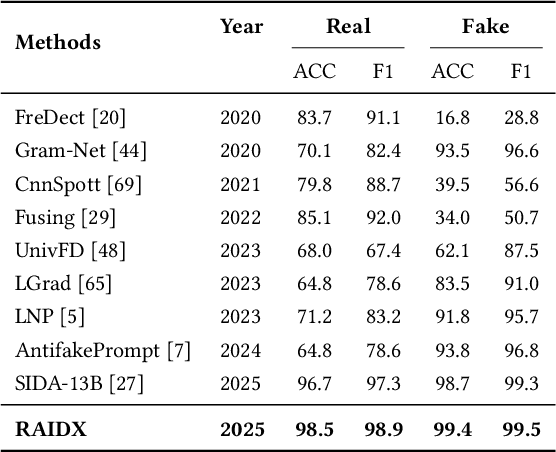
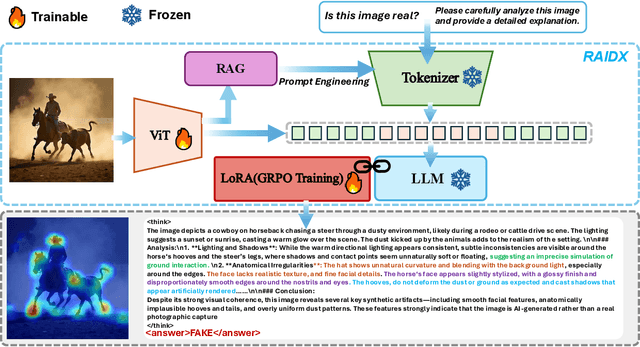
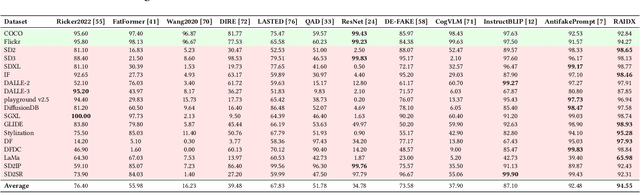
The rapid advancement of AI-generation models has enabled the creation of hyperrealistic imagery, posing ethical risks through widespread misinformation. Current deepfake detection methods, categorized as face specific detectors or general AI-generated detectors, lack transparency by framing detection as a classification task without explaining decisions. While several LLM-based approaches offer explainability, they suffer from coarse-grained analyses and dependency on labor-intensive annotations. This paper introduces RAIDX (Retrieval-Augmented Image Deepfake Detection and Explainability), a novel deepfake detection framework integrating Retrieval-Augmented Generation (RAG) and Group Relative Policy Optimization (GRPO) to enhance detection accuracy and decision explainability. Specifically, RAIDX leverages RAG to incorporate external knowledge for improved detection accuracy and employs GRPO to autonomously generate fine-grained textual explanations and saliency maps, eliminating the need for extensive manual annotations. Experiments on multiple benchmarks demonstrate RAIDX's effectiveness in identifying real or fake, and providing interpretable rationales in both textual descriptions and saliency maps, achieving state-of-the-art detection performance while advancing transparency in deepfake identification. RAIDX represents the first unified framework to synergize RAG and GRPO, addressing critical gaps in accuracy and explainability. Our code and models will be publicly available.
So-Fake: Benchmarking and Explaining Social Media Image Forgery Detection
May 24, 2025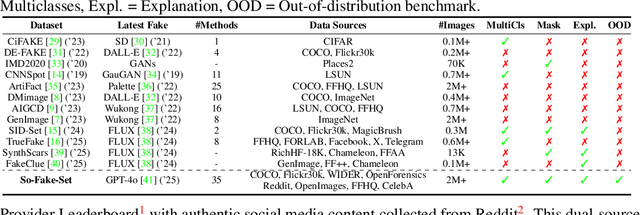
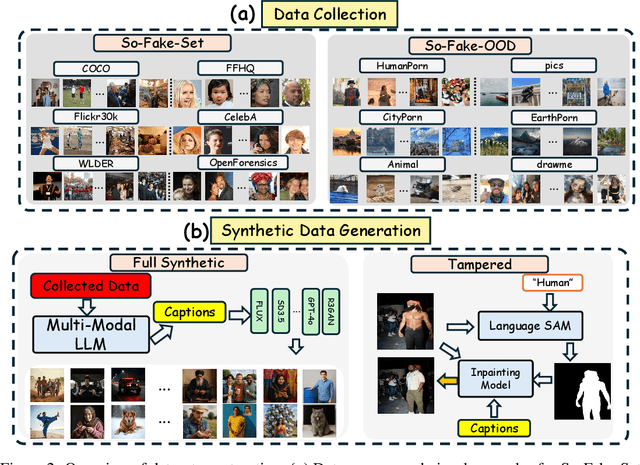
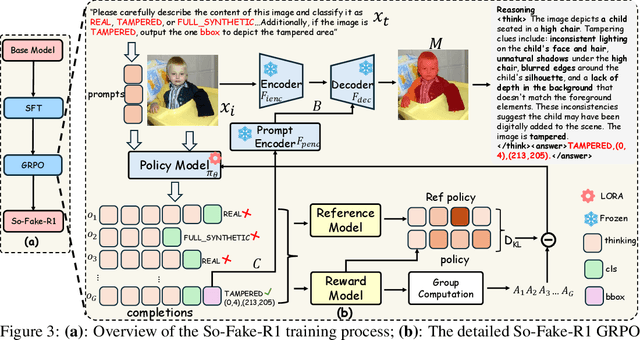
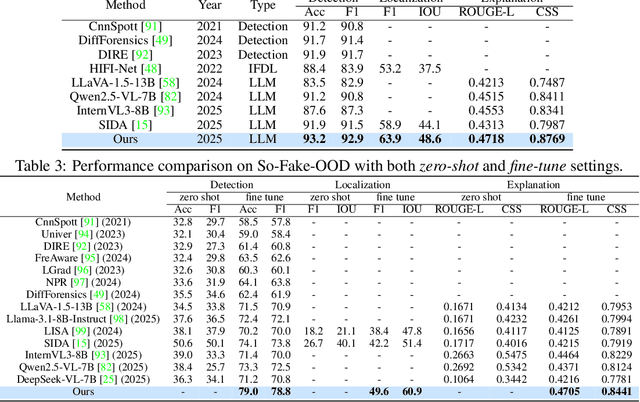
Recent advances in AI-powered generative models have enabled the creation of increasingly realistic synthetic images, posing significant risks to information integrity and public trust on social media platforms. While robust detection frameworks and diverse, large-scale datasets are essential to mitigate these risks, existing academic efforts remain limited in scope: current datasets lack the diversity, scale, and realism required for social media contexts, while detection methods struggle with generalization to unseen generative technologies. To bridge this gap, we introduce So-Fake-Set, a comprehensive social media-oriented dataset with over 2 million high-quality images, diverse generative sources, and photorealistic imagery synthesized using 35 state-of-the-art generative models. To rigorously evaluate cross-domain robustness, we establish a novel and large-scale (100K) out-of-domain benchmark (So-Fake-OOD) featuring synthetic imagery from commercial models explicitly excluded from the training distribution, creating a realistic testbed for evaluating real-world performance. Leveraging these resources, we present So-Fake-R1, an advanced vision-language framework that employs reinforcement learning for highly accurate forgery detection, precise localization, and explainable inference through interpretable visual rationales. Extensive experiments show that So-Fake-R1 outperforms the second-best method, with a 1.3% gain in detection accuracy and a 4.5% increase in localization IoU. By integrating a scalable dataset, a challenging OOD benchmark, and an advanced detection framework, this work establishes a new foundation for social media-centric forgery detection research. The code, models, and datasets will be released publicly.
BusterX: MLLM-Powered AI-Generated Video Forgery Detection and Explanation
May 19, 2025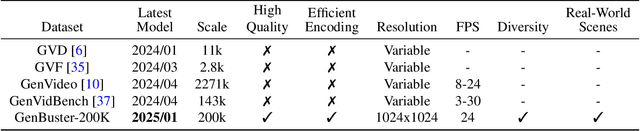
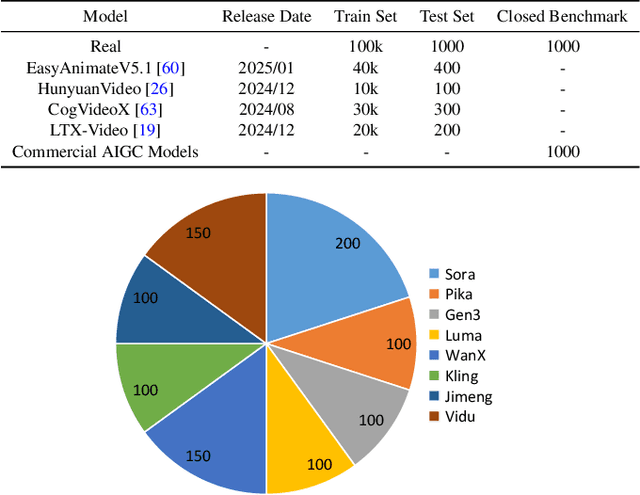
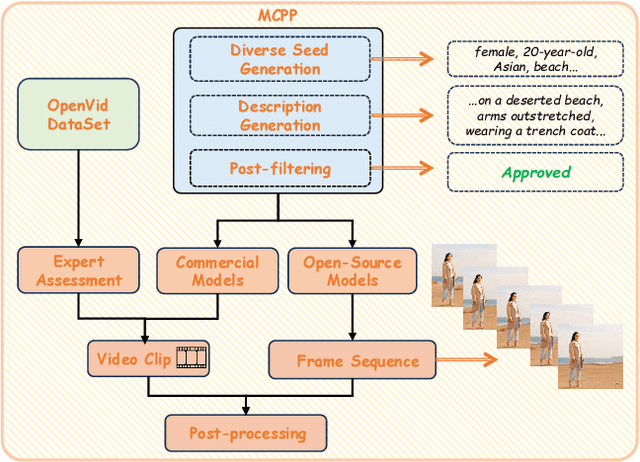
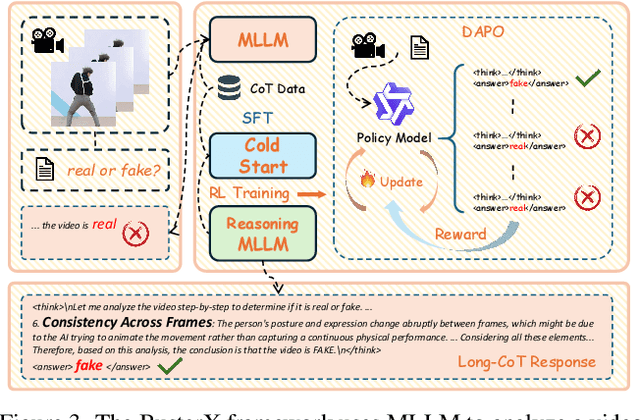
Advances in AI generative models facilitate super-realistic video synthesis, amplifying misinformation risks via social media and eroding trust in digital content. Several research works have explored new deepfake detection methods on AI-generated images to alleviate these risks. However, with the fast development of video generation models, such as Sora and WanX, there is currently a lack of large-scale, high-quality AI-generated video datasets for forgery detection. In addition, existing detection approaches predominantly treat the task as binary classification, lacking explainability in model decision-making and failing to provide actionable insights or guidance for the public. To address these challenges, we propose \textbf{GenBuster-200K}, a large-scale AI-generated video dataset featuring 200K high-resolution video clips, diverse latest generative techniques, and real-world scenes. We further introduce \textbf{BusterX}, a novel AI-generated video detection and explanation framework leveraging multimodal large language model (MLLM) and reinforcement learning for authenticity determination and explainable rationale. To our knowledge, GenBuster-200K is the {\it \textbf{first}} large-scale, high-quality AI-generated video dataset that incorporates the latest generative techniques for real-world scenarios. BusterX is the {\it \textbf{first}} framework to integrate MLLM with reinforcement learning for explainable AI-generated video detection. Extensive comparisons with state-of-the-art methods and ablation studies validate the effectiveness and generalizability of BusterX. The code, models, and datasets will be released.
FALCON: Fine-grained Activation Manipulation by Contrastive Orthogonal Unalignment for Large Language Model
Feb 03, 2025Large language models have been widely applied, but can inadvertently encode sensitive or harmful information, raising significant safety concerns. Machine unlearning has emerged to alleviate this concern; however, existing training-time unlearning approaches, relying on coarse-grained loss combinations, have limitations in precisely separating knowledge and balancing removal effectiveness with model utility. In contrast, we propose Fine-grained Activation manipuLation by Contrastive Orthogonal uNalignment (FALCON), a novel representation-guided unlearning approach that leverages information-theoretic guidance for efficient parameter selection, employs contrastive mechanisms to enhance representation separation, and projects conflict gradients onto orthogonal subspaces to resolve conflicts between forgetting and retention objectives. Extensive experiments demonstrate that FALCON achieves superior unlearning effectiveness while maintaining model utility, exhibiting robust resistance against knowledge recovery attempts.
SIDA: Social Media Image Deepfake Detection, Localization and Explanation with Large Multimodal Model
Dec 05, 2024



The rapid advancement of generative models in creating highly realistic images poses substantial risks for misinformation dissemination. For instance, a synthetic image, when shared on social media, can mislead extensive audiences and erode trust in digital content, resulting in severe repercussions. Despite some progress, academia has not yet created a large and diversified deepfake detection dataset for social media, nor has it devised an effective solution to address this issue. In this paper, we introduce the Social media Image Detection dataSet (SID-Set), which offers three key advantages: (1) extensive volume, featuring 300K AI-generated/tampered and authentic images with comprehensive annotations, (2) broad diversity, encompassing fully synthetic and tampered images across various classes, and (3) elevated realism, with images that are predominantly indistinguishable from genuine ones through mere visual inspection. Furthermore, leveraging the exceptional capabilities of large multimodal models, we propose a new image deepfake detection, localization, and explanation framework, named SIDA (Social media Image Detection, localization, and explanation Assistant). SIDA not only discerns the authenticity of images, but also delineates tampered regions through mask prediction and provides textual explanations of the model's judgment criteria. Compared with state-of-the-art deepfake detection models on SID-Set and other benchmarks, extensive experiments demonstrate that SIDA achieves superior performance among diversified settings. The code, model, and dataset will be released.
IPMix: Label-Preserving Data Augmentation Method for Training Robust Classifiers
Oct 17, 2023
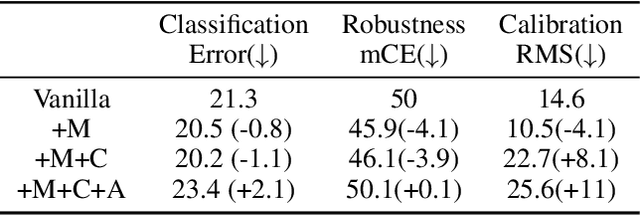

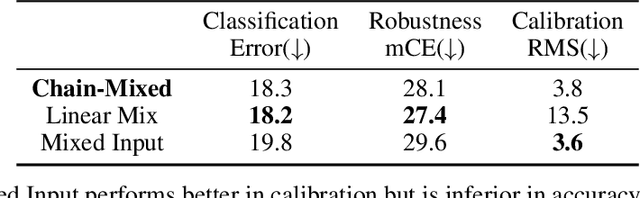
Data augmentation has been proven effective for training high-accuracy convolutional neural network classifiers by preventing overfitting. However, building deep neural networks in real-world scenarios requires not only high accuracy on clean data but also robustness when data distributions shift. While prior methods have proposed that there is a trade-off between accuracy and robustness, we propose IPMix, a simple data augmentation approach to improve robustness without hurting clean accuracy. IPMix integrates three levels of data augmentation (image-level, patch-level, and pixel-level) into a coherent and label-preserving technique to increase the diversity of training data with limited computational overhead. To further improve the robustness, IPMix introduces structural complexity at different levels to generate more diverse images and adopts the random mixing method for multi-scale information fusion. Experiments demonstrate that IPMix outperforms state-of-the-art corruption robustness on CIFAR-C and ImageNet-C. In addition, we show that IPMix also significantly improves the other safety measures, including robustness to adversarial perturbations, calibration, prediction consistency, and anomaly detection, achieving state-of-the-art or comparable results on several benchmarks, including ImageNet-R, ImageNet-A, and ImageNet-O.