 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxyThinker: Test-Time Guidance through Small Visual Reasoners
May 30, 2025Recent advancements in reinforcement learning with verifiable rewards have pushed the boundaries of the visual reasoning capabilities in large vision-language models (LVLMs). However, training LVLMs with reinforcement fine-tuning (RFT) is computationally expensive, posing a significant challenge to scaling model size. In this work, we propose ProxyThinker, an inference-time technique that enables large models to inherit the visual reasoning capabilities from small, slow-thinking visual reasoners without any training. By subtracting the output distributions of base models from those of RFT reasoners, ProxyThinker modifies the decoding dynamics and successfully elicits the slow-thinking reasoning demonstrated by the emerged sophisticated behaviors such as self-verification and self-correction. ProxyThinker consistently boosts performance on challenging visual benchmarks on spatial, mathematical, and multi-disciplinary reasoning, enabling untuned base models to compete with the performance of their full-scale RFT counterparts. Furthermore, our implementation efficiently coordinates multiple language models with parallelism techniques and achieves up to 38 $\times$ faster inference compared to previous decoding-time methods, paving the way for the practical deployment of ProxyThinker. Code is available at https://github.com/MrZilinXiao/ProxyThinker.
LOCORE: Image Re-ranking with Long-Context Sequence Modeling
Mar 27, 2025We introduce LOCORE, Long-Context Re-ranker, a model that takes as input local descriptors corresponding to an image query and a list of gallery images and outputs similarity scores between the query and each gallery image. This model is used for image retrieval, where typically a first ranking is performed with an efficient similarity measure, and then a shortlist of top-ranked images is re-ranked based on a more fine-grained similarity measure. Compared to existing methods that perform pair-wise similarity estimation with local descriptors or list-wise re-ranking with global descriptors, LOCORE is the first method to perform list-wise re-ranking with local descriptors. To achieve this, we leverage efficient long-context sequence models to effectively capture the dependencies between query and gallery images at the local-descriptor level. During testing, we process long shortlists with a sliding window strategy that is tailored to overcome the context size limitations of sequence models. Our approach achieves superior performance compared with other re-rankers on established image retrieval benchmarks of landmarks (ROxf and RPar), products (SOP), fashion items (In-Shop), and bird species (CUB-200) while having comparable latency to the pair-wise local descriptor re-rankers.
ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Oct 08, 2024



Speculative decoding has proven to be an efficient solution to large language model (LLM) inference, where the small drafter predicts future tokens at a low cost, and the target model is leveraged to verify them in parallel. However, most existing works still draft tokens auto-regressively to maintain sequential dependency in language modeling, which we consider a huge computational burden in speculative decoding. We present ParallelSpec, an alternative to auto-regressive drafting strategies in state-of-the-art speculative decoding approaches. In contrast to auto-regressive drafting in the speculative stage, we train a parallel drafter to serve as an efficient speculative model. ParallelSpec learns to efficiently predict multiple future tokens in parallel using a single model, and it can be integrated into any speculative decoding framework that requires aligning the output distributions of the drafter and the target model with minimal training cost. Experimental results show that ParallelSpec accelerates baseline methods in latency up to 62% on text generation benchmarks from different domains, and it achieves 2.84X overall speedup on the Llama-2-13B model using third-party evaluation criteria.
Will the Real Linda Please Stand upto Large Language Models? Examining the Representativeness Heuristic in LLMs
Apr 01, 2024Although large language models (LLMs) have demonstrated remarkable proficiency in understanding text and generating human-like text, they may exhibit biases acquired from training data in doing so. Specifically, LLMs may be susceptible to a common cognitive trap in human decision-making called the representativeness heuristic. This is a concept in psychology that refers to judging the likelihood of an event based on how closely it resembles a well-known prototype or typical example versus considering broader facts or statistical evidence. This work investigates the impact of the representativeness heuristic on LLM reasoning. We created REHEAT (Representativeness Heuristic AI Testing), a dataset containing a series of problems spanning six common types of representativeness heuristics. Experiments reveal that four LLMs applied to REHEAT all exhibited representativeness heuristic biases. We further identify that the model's reasoning steps are often incorrectly based on a stereotype rather than the problem's description. Interestingly, the performance improves when adding a hint in the prompt to remind the model of using its knowledge. This suggests the uniqueness of the representativeness heuristic compared to traditional biases. It can occur even when LLMs possess the correct knowledge while failing in a cognitive trap. This highlights the importance of future research focusing on the representativeness heuristic in model reasoning and decision-making and on developing solutions to address it.
Grounding Language Models for Visual Entity Recognition
Feb 28, 2024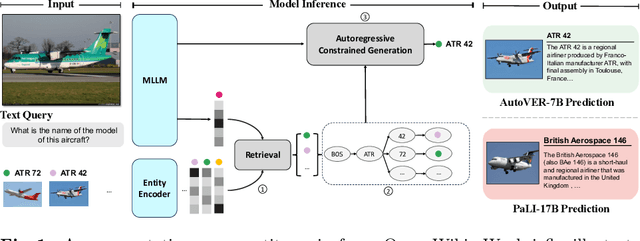
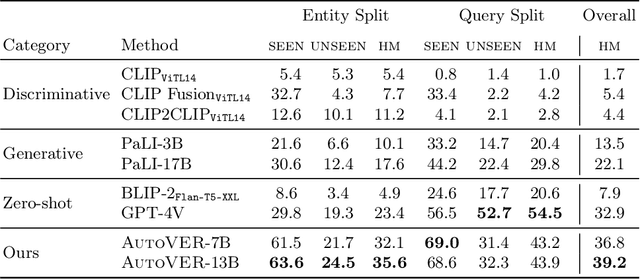
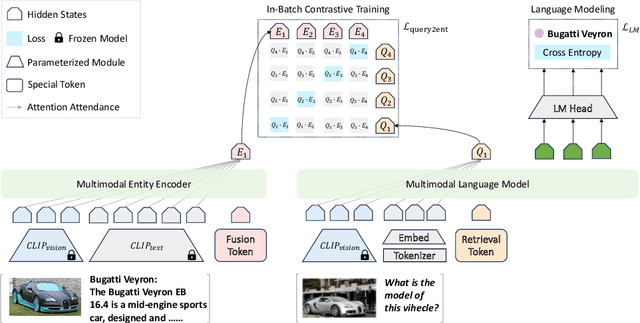
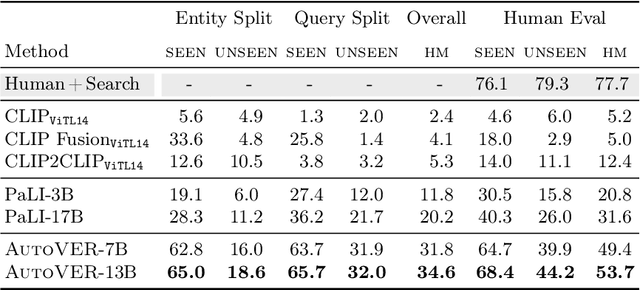
We introduce AutoVER, an Autoregressive model for Visual Entity Recognition. Our model extends an autoregressive Multi-modal Large Language Model by employing retrieval augmented constrained generation. It mitigates low performance on out-of-domain entities while excelling in queries that require visually-situated reasoning. Our method learns to distinguish similar entities within a vast label space by contrastively training on hard negative pairs in parallel with a sequence-to-sequence objective without an external retriever. During inference, a list of retrieved candidate answers explicitly guides language generation by removing invalid decoding paths. The proposed method achieves significant improvements across different dataset splits in the recently proposed Oven-Wiki benchmark. Accuracy on the Entity seen split rises from 32.7% to 61.5%. It also demonstrates superior performance on the unseen and query splits by a substantial double-digit margin.
Coherent Entity Disambiguation via Modeling Topic and Categorical Dependency
Nov 06, 2023



Previous entity disambiguation (ED) methods adopt a discriminative paradigm, where prediction is made based on matching scores between mention context and candidate entities using length-limited encoders. However, these methods often struggle to capture explicit discourse-level dependencies, resulting in incoherent predictions at the abstract level (e.g. topic or category). We propose CoherentED, an ED system equipped with novel designs aimed at enhancing the coherence of entity predictions. Our method first introduces an unsupervised variational autoencoder (VAE) to extract latent topic vectors of context sentences. This approach not only allows the encoder to handle longer documents more effectively, conserves valuable input space, but also keeps a topic-level coherence. Additionally, we incorporate an external category memory, enabling the system to retrieve relevant categories for undecided mentions. By employing step-by-step entity decisions, this design facilitates the modeling of entity-entity interactions, thereby maintaining maximum coherence at the category level. We achieve new state-of-the-art results on popular ED benchmarks, with an average improvement of 1.3 F1 points. Our model demonstrates particularly outstanding performance on challenging long-text scenarios.
Instructed Language Models with Retrievers Are Powerful Entity Linkers
Nov 06, 2023Generative approaches powered by large language models (LLMs) have demonstrated emergent abilities in tasks that require complex reasoning abilities. Yet the generative nature still makes the generated content suffer from hallucinations, thus unsuitable for entity-centric tasks like entity linking (EL) requiring precise entity predictions over a large knowledge base. We present Instructed Generative Entity Linker (INSGENEL), the first approach that enables casual language models to perform entity linking over knowledge bases. Several methods to equip language models with EL capability were proposed in this work, including (i) a sequence-to-sequence training EL objective with instruction-tuning, (ii) a novel generative EL framework based on a light-weight potential mention retriever that frees the model from heavy and non-parallelizable decoding, achieving 4$\times$ speedup without compromise on linking metrics. INSGENEL outperforms previous generative alternatives with +6.8 F1 points gain on average, also with a huge advantage in training data efficiency and training compute consumption. In addition, our skillfully engineered in-context learning (ICL) framework for EL still lags behind INSGENEL significantly, reaffirming that the EL task remains a persistent hurdle for general LLMs.