 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialVeil: Probing Social Intelligence of Language Agents under Communication Barriers
Feb 04, 2026Large language models (LLMs) are increasingly evaluated in interactive environments to test their social intelligence. However, existing benchmarks often assume idealized communication between agents, limiting our ability to diagnose whether LLMs can maintain and repair interactions in more realistic, imperfect settings. To close this gap, we present \textsc{SocialVeil}, a social learning environment that can simulate social interaction under cognitive-difference-induced communication barriers. Grounded in a systematic literature review of communication challenges in human interaction, \textsc{SocialVeil} introduces three representative types of such disruption, \emph{semantic vagueness}, \emph{sociocultural mismatch}, and \emph{emotional interference}. We also introduce two barrier-aware evaluation metrics, \emph{unresolved confusion} and \emph{mutual understanding}, to evaluate interaction quality under impaired communication. Experiments across 720 scenarios and four frontier LLMs show that barriers consistently impair performance, with mutual understanding reduced by over 45\% on average, and confusion elevated by nearly 50\%. Human evaluations validate the fidelity of these simulated barriers (ICC$\approx$0.78, Pearson r$\approx$0.80). We further demonstrate that adaptation strategies (Repair Instruction and Interactive learning) only have a modest effect far from barrier-free performance. This work takes a step toward bringing social interaction environments closer to real-world communication, opening opportunities for exploring the social intelligence of LLM agents.
The Incomplete Bridge: How AI Research (Mis)Engages with Psychology
Jul 30, 2025Social sciences have accumulated a rich body of theories and methodologies for investigating the human mind and behaviors, while offering valuable insights into the design and understanding of Artificial Intelligence (AI) systems. Focusing on psychology as a prominent case, this study explores the interdisciplinary synergy between AI and the field by analyzing 1,006 LLM-related papers published in premier AI venues between 2023 and 2025, along with the 2,544 psychology publications they cite. Through our analysis, we identify key patterns of interdisciplinary integration, locate the psychology domains most frequently referenced, and highlight areas that remain underexplored. We further examine how psychology theories/frameworks are operationalized and interpreted, identify common types of misapplication, and offer guidance for more effective incorporation. Our work provides a comprehensive map of interdisciplinary engagement between AI and psychology, thereby facilitating deeper collaboration and advancing AI systems.
Personality Structured Interview for Large Language Model Simulation in Personality Research
Feb 17, 2025Although psychometrics researchers have recently explored the use of large language models (LLMs) as proxies for human participants, LLMs often fail to generate heterogeneous data with human-like diversity, which diminishes their value in advancing social science research. To address these challenges, we explored the potential of the theory-informed Personality Structured Interview (PSI) as a tool for simulating human responses in personality research. In this approach, the simulation is grounded in nuanced real-human interview transcripts that target the personality construct of interest. We have provided a growing set of 357 structured interview transcripts from a representative sample, each containing an individual's response to 32 open-ended questions carefully designed to gather theory-based personality evidence. Additionally, grounded in psychometric research, we have summarized an evaluation framework to systematically validate LLM-generated psychometric data. Results from three experiments demonstrate that well-designed structured interviews could improve human-like heterogeneity in LLM-simulated personality data and predict personality-related behavioral outcomes (i.e., organizational citizenship behaviors and counterproductive work behavior). We further discuss the role of theory-informed structured interviews in LLM-based simulation and outline a general framework for designing structured interviews to simulate human-like data for psychometric research.
From Babbling to Fluency: Evaluating the Evolution of Language Models in Terms of Human Language Acquisition
Oct 17, 2024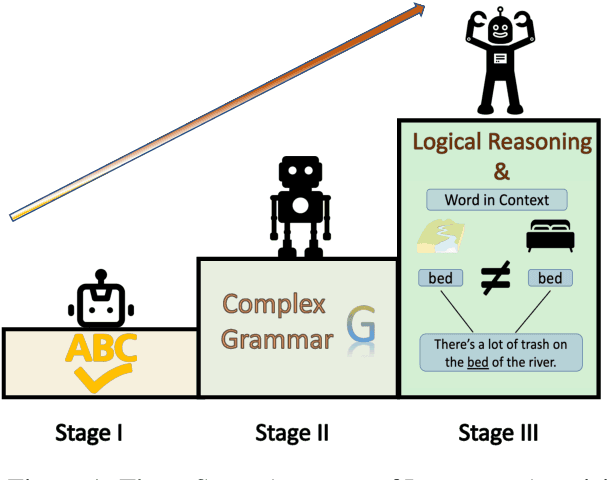
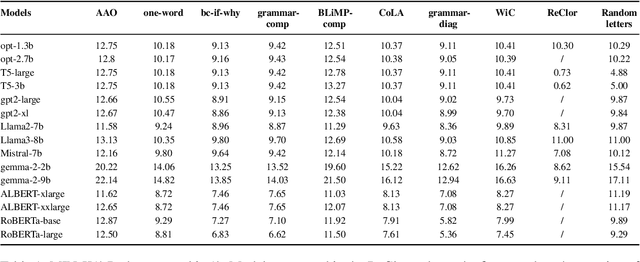
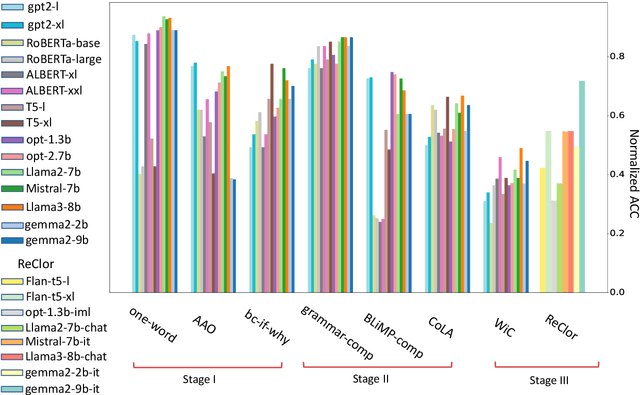
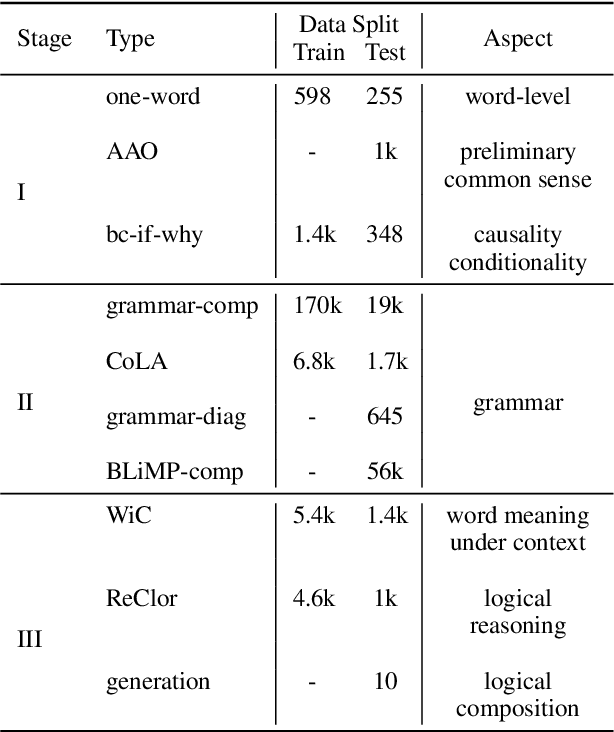
We examine the language capabilities of language models (LMs) from the critical perspective of human language acquisition. Building on classical language development theories, we propose a three-stage framework to assess the abilities of LMs, ranging from preliminary word understanding to complex grammar and complex logical reasoning. Using this framework, we evaluate the generative capacities of LMs using methods from linguistic research. Results indicate that although recent LMs outperform earlier models in overall performance, their developmental trajectory does not strictly follow the path of human language acquisition. Notably, in generation tasks, LMs are more similar to human performance in areas where information is easier to extract from the corpus, such as average word length, clauses, and auxiliary verbs. Newer LMs did not exhibit significant progress in terms of specific dimensions, such as clauses and auxiliary verbs, where the variation across corpora is relatively limited. Register theory offers a plausible explanation for these observations, suggesting that the linguistic features of the training data have a substantial impact on the models' abilities.
Will the Real Linda Please Stand upto Large Language Models? Examining the Representativeness Heuristic in LLMs
Apr 01, 2024Although large language models (LLMs) have demonstrated remarkable proficiency in understanding text and generating human-like text, they may exhibit biases acquired from training data in doing so. Specifically, LLMs may be susceptible to a common cognitive trap in human decision-making called the representativeness heuristic. This is a concept in psychology that refers to judging the likelihood of an event based on how closely it resembles a well-known prototype or typical example versus considering broader facts or statistical evidence. This work investigates the impact of the representativeness heuristic on LLM reasoning. We created REHEAT (Representativeness Heuristic AI Testing), a dataset containing a series of problems spanning six common types of representativeness heuristics. Experiments reveal that four LLMs applied to REHEAT all exhibited representativeness heuristic biases. We further identify that the model's reasoning steps are often incorrectly based on a stereotype rather than the problem's description. Interestingly, the performance improves when adding a hint in the prompt to remind the model of using its knowledge. This suggests the uniqueness of the representativeness heuristic compared to traditional biases. It can occur even when LLMs possess the correct knowledge while failing in a cognitive trap. This highlights the importance of future research focusing on the representativeness heuristic in model reasoning and decision-making and on developing solutions to address it.