 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Babbling to Fluency: Evaluating the Evolution of Language Models in Terms of Human Language Acquisition
Oct 17, 2024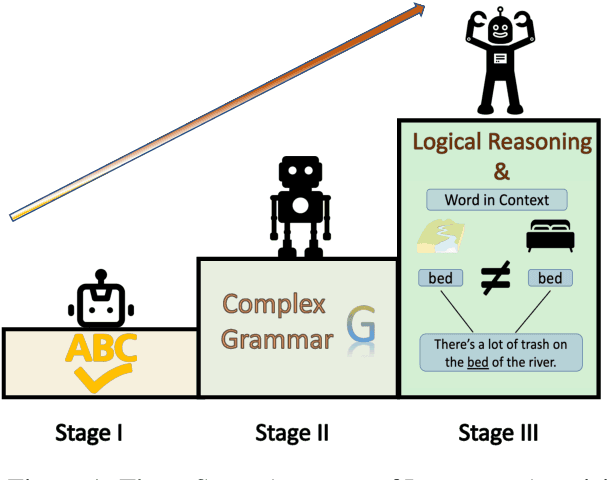
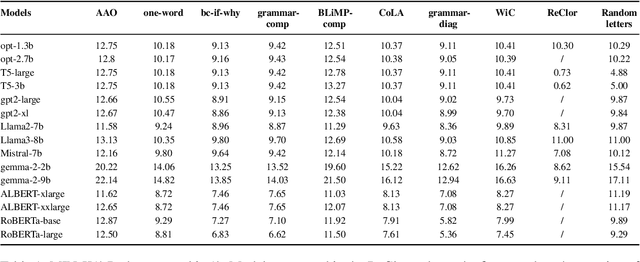
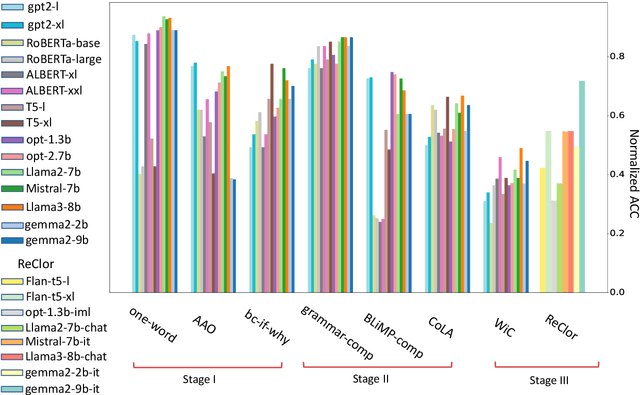
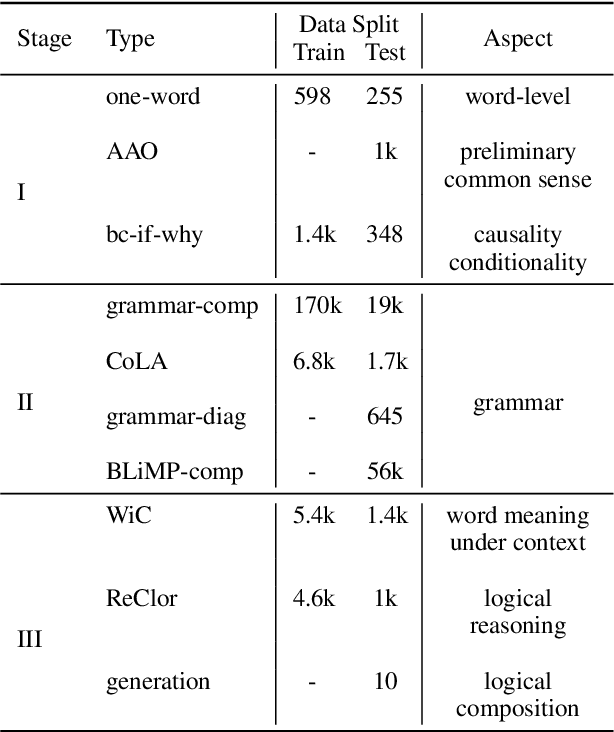
We examine the language capabilities of language models (LMs) from the critical perspective of human language acquisition. Building on classical language development theories, we propose a three-stage framework to assess the abilities of LMs, ranging from preliminary word understanding to complex grammar and complex logical reasoning. Using this framework, we evaluate the generative capacities of LMs using methods from linguistic research. Results indicate that although recent LMs outperform earlier models in overall performance, their developmental trajectory does not strictly follow the path of human language acquisition. Notably, in generation tasks, LMs are more similar to human performance in areas where information is easier to extract from the corpus, such as average word length, clauses, and auxiliary verbs. Newer LMs did not exhibit significant progress in terms of specific dimensions, such as clauses and auxiliary verbs, where the variation across corpora is relatively limited. Register theory offers a plausible explanation for these observations, suggesting that the linguistic features of the training data have a substantial impact on the models' abilities.