 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Agent: Optimizing Planning Capability for Multimodal Retrieval Augmented Generation
Aug 12, 2025Multimodal Retrieval-Augmented Generation (mRAG) has emerged as a promising solution to address the temporal limitations of Multimodal Large Language Models (MLLMs) in real-world scenarios like news analysis and trending topics. However, existing approaches often suffer from rigid retrieval strategies and under-utilization of visual information. To bridge this gap, we propose E-Agent, an agent framework featuring two key innovations: a mRAG planner trained to dynamically orchestrate multimodal tools based on contextual reasoning, and a task executor employing tool-aware execution sequencing to implement optimized mRAG workflows. E-Agent adopts a one-time mRAG planning strategy that enables efficient information retrieval while minimizing redundant tool invocations. To rigorously assess the planning capabilities of mRAG systems, we introduce the Real-World mRAG Planning (RemPlan) benchmark. This novel benchmark contains both retrieval-dependent and retrieval-independent question types, systematically annotated with essential retrieval tools required for each instance. The benchmark's explicit mRAG planning annotations and diverse question design enhance its practical relevance by simulating real-world scenarios requiring dynamic mRAG decisions. Experiments across RemPlan and three established benchmarks demonstrate E-Agent's superiority: 13% accuracy gain over state-of-the-art mRAG methods while reducing redundant searches by 37%.
Progressive Multi-modal Conditional Prompt Tuning
Apr 18, 2024



Pre-trained vision-language models (VLMs) have shown remarkable generalization capabilities via prompting, which leverages VLMs as knowledge bases to extract information beneficial for downstream tasks. However, existing methods primarily employ uni-modal prompting, which only engages a uni-modal branch, failing to simultaneously adjust vision-language (V-L) features. Additionally, the one-pass forward pipeline in VLM encoding struggles to align V-L features that have a huge gap. Confronting these challenges, we propose a novel method, Progressive Multi-modal conditional Prompt Tuning (ProMPT). ProMPT exploits a recurrent structure, optimizing and aligning V-L features by iteratively utilizing image and current encoding information. It comprises an initialization and a multi-modal iterative evolution (MIE) module. Initialization is responsible for encoding image and text using a VLM, followed by a feature filter that selects text features similar to image. MIE then facilitates multi-modal prompting through class-conditional vision prompting, instance-conditional text prompting, and feature filtering. In each MIE iteration, vision prompts are obtained from the filtered text features via a vision generator, promoting image features to focus more on target object during vision prompting. The encoded image features are fed into a text generator to produce text prompts that are more robust to class shift. Thus, V-L features are progressively aligned, enabling advance from coarse to exact classifications. Extensive experiments are conducted in three settings to evaluate the efficacy of ProMPT. The results indicate that ProMPT outperforms existing methods on average across all settings, demonstrating its superior generalization.
Cross-Lingual Transfer for Natural Language Inference via Multilingual Prompt Translator
Mar 19, 2024

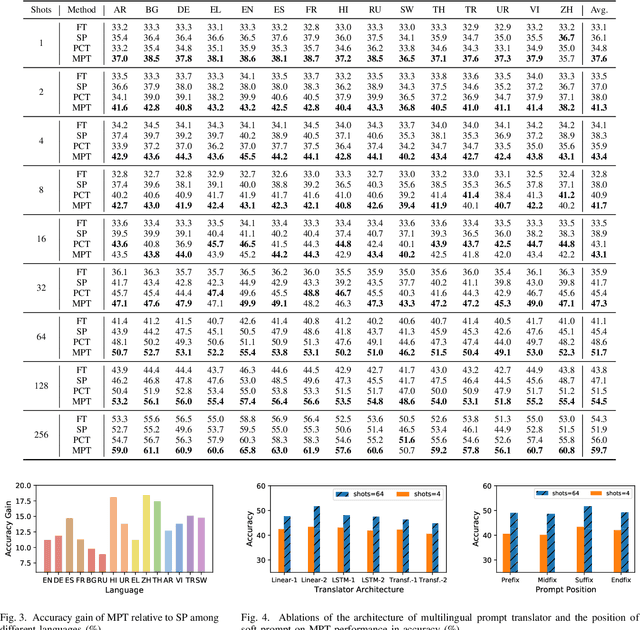

Based on multilingual pre-trained models, cross-lingual transfer with prompt learning has shown promising effectiveness, where soft prompt learned in a source language is transferred to target languages for downstream tasks, particularly in the low-resource scenario. To efficiently transfer soft prompt, we propose a novel framework, Multilingual Prompt Translator (MPT), where a multilingual prompt translator is introduced to properly process crucial knowledge embedded in prompt by changing language knowledge while retaining task knowledge. Concretely, we first train prompt in source language and employ translator to translate it into target prompt. Besides, we extend an external corpus as auxiliary data, on which an alignment task for predicted answer probability is designed to convert language knowledge, thereby equipping target prompt with multilingual knowledge. In few-shot settings on XNLI, MPT demonstrates superiority over baselines by remarkable improvements. MPT is more prominent compared with vanilla prompting when transferring to languages quite distinct from source language.
Text-Only Training for Visual Storytelling
Aug 17, 2023

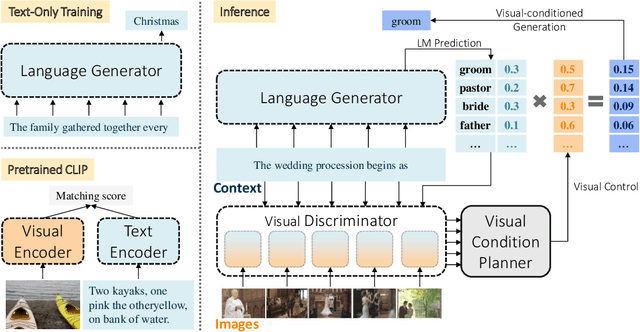

Visual storytelling aims to generate a narrative based on a sequence of images, necessitating both vision-language alignment and coherent story generation. Most existing solutions predominantly depend on paired image-text training data, which can be costly to collect and challenging to scale. To address this, we formulate visual storytelling as a visual-conditioned story generation problem and propose a text-only training method that separates the learning of cross-modality alignment and story generation. Our approach specifically leverages the cross-modality pre-trained CLIP model to integrate visual control into a story generator, trained exclusively on text data. Moreover, we devise a training-free visual condition planner that accounts for the temporal structure of the input image sequence while balancing global and local visual content. The distinctive advantage of requiring only text data for training enables our method to learn from external text story data, enhancing the generalization capability of visual storytelling. We conduct extensive experiments on the VIST benchmark, showcasing the effectiveness of our approach in both in-domain and cross-domain settings. Further evaluations on expression diversity and human assessment underscore the superiority of our method in terms of informativeness and robustness.
Geometric Representation Learning for Document Image Rectification
Oct 15, 2022
In document image rectification, there exist rich geometric constraints between the distorted image and the ground truth one. However, such geometric constraints are largely ignored in existing advanced solutions, which limits the rectification performance. To this end, we present DocGeoNet for document image rectification by introducing explicit geometric representation. Technically, two typical attributes of the document image are involved in the proposed geometric representation learning, i.e., 3D shape and textlines. Our motivation arises from the insight that 3D shape provides global unwarping cues for rectifying a distorted document image while overlooking the local structure. On the other hand, textlines complementarily provide explicit geometric constraints for local patterns. The learned geometric representation effectively bridges the distorted image and the ground truth one. Extensive experiments show the effectiveness of our framework and demonstrate the superiority of our DocGeoNet over state-of-the-art methods on both the DocUNet Benchmark dataset and our proposed DIR300 test set. The code is available at https://github.com/fh2019ustc/DocGeoNet.
DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction
Oct 25, 2021In this work, we propose a new framework, called Document Image Transformer (DocTr), to address the issue of geometry and illumination distortion of the document images. Specifically, DocTr consists of a geometric unwarping transformer and an illumination correction transformer. By setting a set of learned query embedding, the geometric unwarping transformer captures the global context of the document image by self-attention mechanism and decodes the pixel-wise displacement solution to correct the geometric distortion. After geometric unwarping, our illumination correction transformer further removes the shading artifacts to improve the visual quality and OCR accuracy. Extensive evaluations are conducted on several datasets, and superior results are reported against the state-of-the-art methods. Remarkably, our DocTr achieves 20.02% Character Error Rate (CER), a 15% absolute improvement over the state-of-the-art methods. Moreover, it also shows high efficiency on running time and parameter count. The results will be available at https://github.com/fh2019ustc/DocTr for further comparison.
SignBERT: Pre-Training of Hand-Model-Aware Representation for Sign Language Recognition
Oct 11, 2021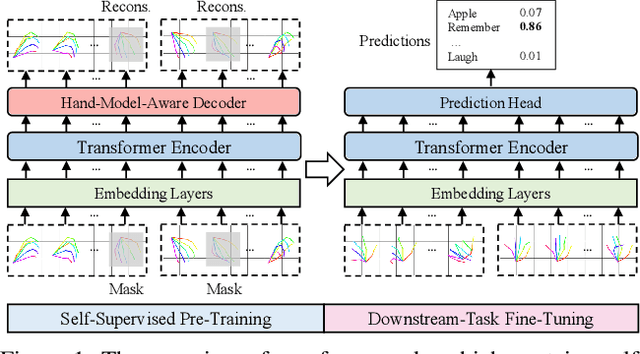
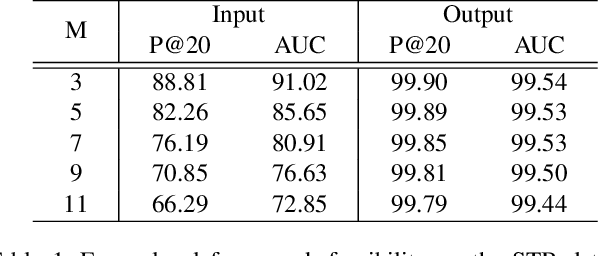
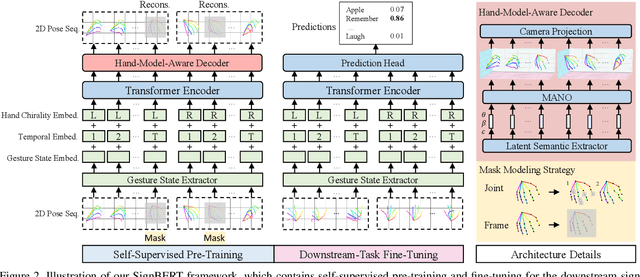
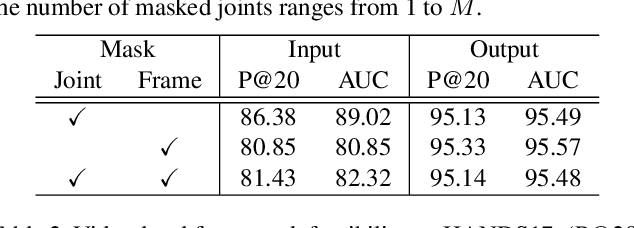
Hand gesture serves as a critical role in sign language. Current deep-learning-based sign language recognition (SLR) methods may suffer insufficient interpretability and overfitting due to limited sign data sources. In this paper, we introduce the first self-supervised pre-trainable SignBERT with incorporated hand prior for SLR. SignBERT views the hand pose as a visual token, which is derived from an off-the-shelf pose extractor. The visual tokens are then embedded with gesture state, temporal and hand chirality information. To take full advantage of available sign data sources, SignBERT first performs self-supervised pre-training by masking and reconstructing visual tokens. Jointly with several mask modeling strategies, we attempt to incorporate hand prior in a model-aware method to better model hierarchical context over the hand sequence. Then with the prediction head added, SignBERT is fine-tuned to perform the downstream SLR task. To validate the effectiveness of our method on SLR, we perform extensive experiments on four public benchmark datasets, i.e., NMFs-CSL, SLR500, MSASL and WLASL. Experiment results demonstrate the effectiveness of both self-supervised learning and imported hand prior. Furthermore, we achieve state-of-the-art performance on all benchmarks with a notable gain.
Weakly Supervised Temporal Adjacent Network for Language Grounding
Jun 30, 2021

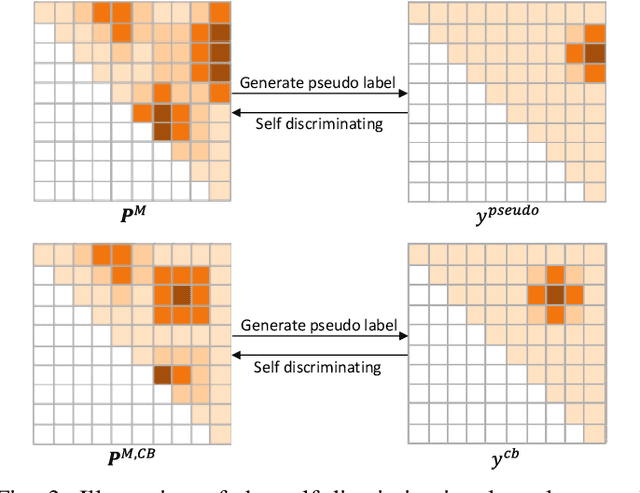

Temporal language grounding (TLG) is a fundamental and challenging problem for vision and language understanding. Existing methods mainly focus on fully supervised setting with temporal boundary labels for training, which, however, suffers expensive cost of annotation. In this work, we are dedicated to weakly supervised TLG, where multiple description sentences are given to an untrimmed video without temporal boundary labels. In this task, it is critical to learn a strong cross-modal semantic alignment between sentence semantics and visual content. To this end, we introduce a novel weakly supervised temporal adjacent network (WSTAN) for temporal language grounding. Specifically, WSTAN learns cross-modal semantic alignment by exploiting temporal adjacent network in a multiple instance learning (MIL) paradigm, with a whole description paragraph as input. Moreover, we integrate a complementary branch into the framework, which explicitly refines the predictions with pseudo supervision from the MIL stage. An additional self-discriminating loss is devised on both the MIL branch and the complementary branch, aiming to enhance semantic discrimination by self-supervising. Extensive experiments are conducted on three widely used benchmark datasets, \emph{i.e.}, ActivityNet-Captions, Charades-STA, and DiDeMo, and the results demonstrate the effectiveness of our approach.
Pre-training Text Representations as Meta Learning
Apr 12, 2020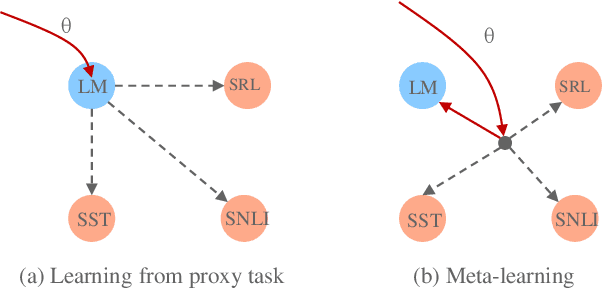
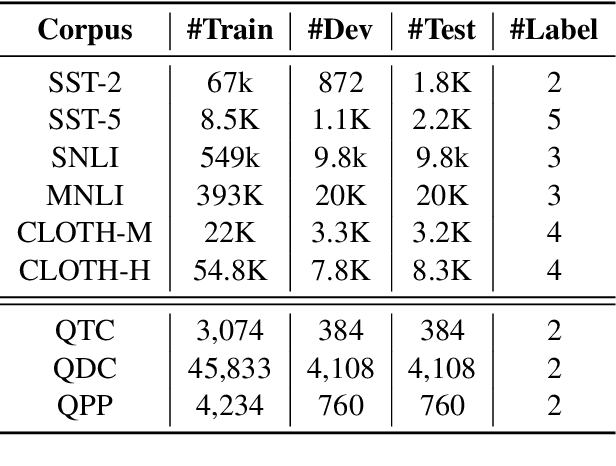
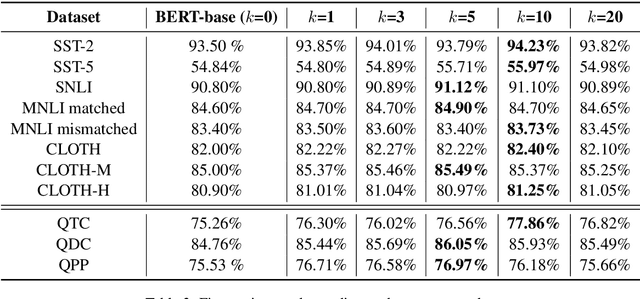
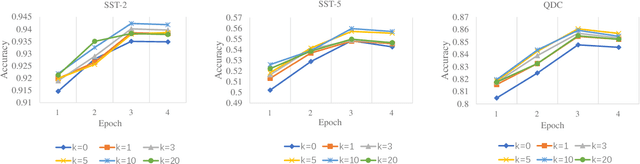
Pre-training text representations has recently been shown to significantly improve the state-of-the-art in many natural language processing tasks. The central goal of pre-training is to learn text representations that are useful for subsequent tasks. However, existing approaches are optimized by minimizing a proxy objective, such as the negative log likelihood of language modeling. In this work, we introduce a learning algorithm which directly optimizes model's ability to learn text representations for effective learning of downstream tasks. We show that there is an intrinsic connection between multi-task pre-training and model-agnostic meta-learning with a sequence of meta-train steps. The standard multi-task learning objective adopted in BERT is a special case of our learning algorithm where the depth of meta-train is zero. We study the problem in two settings: unsupervised pre-training and supervised pre-training with different pre-training objects to verify the generality of our approach.Experimental results show that our algorithm brings improvements and learns better initializations for a variety of downstream tasks.