 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocR1: Evidence Page-Guided GRPO for Multi-Page Document Understanding
Aug 10, 2025Understanding multi-page documents poses a significant challenge for multimodal large language models (MLLMs), as it requires fine-grained visual comprehension and multi-hop reasoning across pages. While prior work has explored reinforcement learning (RL) for enhancing advanced reasoning in MLLMs, its application to multi-page document understanding remains underexplored. In this paper, we introduce DocR1, an MLLM trained with a novel RL framework, Evidence Page-Guided GRPO (EviGRPO). EviGRPO incorporates an evidence-aware reward mechanism that promotes a coarse-to-fine reasoning strategy, guiding the model to first retrieve relevant pages before generating answers. This training paradigm enables us to build high-quality models with limited supervision. To support this, we design a two-stage annotation pipeline and a curriculum learning strategy, based on which we construct two datasets: EviBench, a high-quality training set with 4.8k examples, and ArxivFullQA, an evaluation benchmark with 8.6k QA pairs based on scientific papers. Extensive experiments across a wide range of benchmarks demonstrate that DocR1 achieves state-of-the-art performance on multi-page tasks, while consistently maintaining strong results on single-page benchmarks.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Cross-Modal Consistency Learning for Sign Language Recognition
Mar 16, 2025Pre-training has been proven to be effective in boosting the performance of Isolated Sign Language Recognition (ISLR). Existing pre-training methods solely focus on the compact pose data, which eliminate background perturbation but inevitably suffer from insufficient semantic cues compared to raw RGB videos. Nevertheless, direct representation learning only from RGB videos remains challenging due to the presence of sign-independent visual features. To address this dilemma, we propose a Cross-modal Consistency Learning framework (CCL-SLR), which leverages the cross-modal consistency from both RGB and pose modalities based on self-supervised pre-training. First, CCL-SLR employs contrastive learning for instance discrimination within and across modalities. Through the single-modal and cross-modal contrastive learning, CCL-SLR gradually aligns the feature spaces of RGB and pose modalities, thereby extracting consistent sign representations. Second, we further introduce Motion-Preserving Masking (MPM) and Semantic Positive Mining (SPM) techniques to improve cross-modal consistency from the perspective of data augmentation and sample similarity, respectively. Extensive experiments on four ISLR benchmarks show that CCL-SLR achieves impressive performance, demonstrating its effectiveness. The code will be released to the public.
Uni-Sign: Toward Unified Sign Language Understanding at Scale
Jan 25, 2025



Sign language pre-training has gained increasing attention for its ability to enhance performance across various sign language understanding (SLU) tasks. However, existing methods often suffer from a gap between pre-training and fine-tuning, leading to suboptimal results. To address this, we propose \modelname, a unified pre-training framework that eliminates the gap between pre-training and downstream SLU tasks through a large-scale generative pre-training strategy and a novel fine-tuning paradigm. First, we introduce CSL-News, a large-scale Chinese Sign Language (CSL) dataset containing 1,985 hours of video paired with textual annotations, which enables effective large-scale pre-training. Second, \modelname unifies SLU tasks by treating downstream tasks as a single sign language translation (SLT) task during fine-tuning, ensuring seamless knowledge transfer between pre-training and fine-tuning. Furthermore, we incorporate a prior-guided fusion (PGF) module and a score-aware sampling strategy to efficiently fuse pose and RGB information, addressing keypoint inaccuracies and improving computational efficiency. Extensive experiments across multiple SLU benchmarks demonstrate that \modelname achieves state-of-the-art performance across multiple downstream SLU tasks. Dataset and code are available at \url{github.com/ZechengLi19/Uni-Sign}.
Scaling up Multimodal Pre-training for Sign Language Understanding
Aug 16, 2024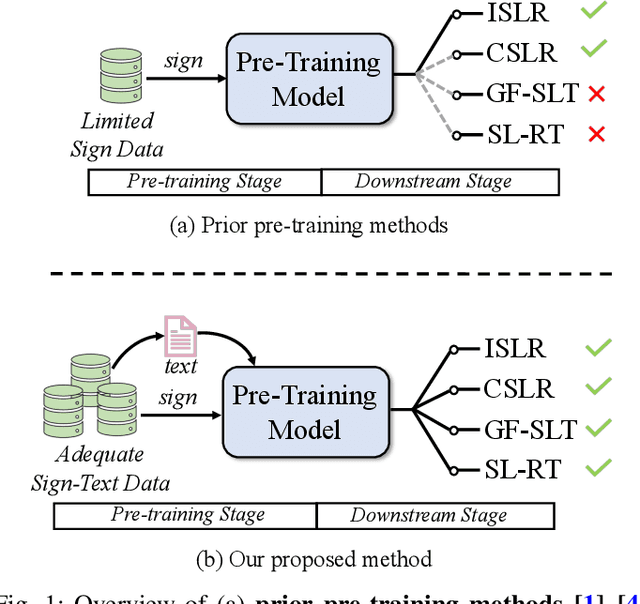



Sign language serves as the primary meaning of communication for the deaf-mute community. Different from spoken language, it commonly conveys information by the collaboration of manual features, i.e., hand gestures and body movements, and non-manual features, i.e., facial expressions and mouth cues. To facilitate communication between the deaf-mute and hearing people, a series of sign language understanding (SLU) tasks have been studied in recent years, including isolated/continuous sign language recognition (ISLR/CSLR), gloss-free sign language translation (GF-SLT) and sign language retrieval (SL-RT). Sign language recognition and translation aims to understand the semantic meaning conveyed by sign languages from gloss-level and sentence-level, respectively. In contrast, SL-RT focuses on retrieving sign videos or corresponding texts from a closed-set under the query-by-example search paradigm. These tasks investigate sign language topics from diverse perspectives and raise challenges in learning effective representation of sign language videos. To advance the development of sign language understanding, exploring a generalized model that is applicable across various SLU tasks is a profound research direction.
TabPedia: Towards Comprehensive Visual Table Understanding with Concept Synergy
Jun 03, 2024



Tables contain factual and quantitative data accompanied by various structures and contents that pose challenges for machine comprehension. Previous methods generally design task-specific architectures and objectives for individual tasks, resulting in modal isolation and intricate workflows. In this paper, we present a novel large vision-language model, TabPedia, equipped with a concept synergy mechanism. In this mechanism, all the involved diverse visual table understanding (VTU) tasks and multi-source visual embeddings are abstracted as concepts. This unified framework allows TabPedia to seamlessly integrate VTU tasks, such as table detection, table structure recognition, table querying, and table question answering, by leveraging the capabilities of large language models (LLMs). Moreover, the concept synergy mechanism enables table perception-related and comprehension-related tasks to work in harmony, as they can effectively leverage the needed clues from the corresponding source perception embeddings. Furthermore, to better evaluate the VTU task in real-world scenarios, we establish a new and comprehensive table VQA benchmark, ComTQA, featuring approximately 9,000 QA pairs. Extensive quantitative and qualitative experiments on both table perception and comprehension tasks, conducted across various public benchmarks, validate the effectiveness of our TabPedia. The superior performance further confirms the feasibility of using LLMs for understanding visual tables when all concepts work in synergy. The benchmark ComTQA has been open-sourced at https://huggingface.co/datasets/ByteDance/ComTQA. The source code and model will be released later.
MASA: Motion-aware Masked Autoencoder with Semantic Alignment for Sign Language Recognition
May 31, 2024



Sign language recognition (SLR) has long been plagued by insufficient model representation capabilities. Although current pre-training approaches have alleviated this dilemma to some extent and yielded promising performance by employing various pretext tasks on sign pose data, these methods still suffer from two primary limitations: 1) Explicit motion information is usually disregarded in previous pretext tasks, leading to partial information loss and limited representation capability. 2) Previous methods focus on the local context of a sign pose sequence, without incorporating the guidance of the global meaning of lexical signs. To this end, we propose a Motion-Aware masked autoencoder with Semantic Alignment (MASA) that integrates rich motion cues and global semantic information in a self-supervised learning paradigm for SLR. Our framework contains two crucial components, i.e., a motion-aware masked autoencoder (MA) and a momentum semantic alignment module (SA). Specifically, in MA, we introduce an autoencoder architecture with a motion-aware masked strategy to reconstruct motion residuals of masked frames, thereby explicitly exploring dynamic motion cues among sign pose sequences. Moreover, in SA, we embed our framework with global semantic awareness by aligning the embeddings of different augmented samples from the input sequence in the shared latent space. In this way, our framework can simultaneously learn local motion cues and global semantic features for comprehensive sign language representation. Furthermore, we conduct extensive experiments to validate the effectiveness of our method, achieving new state-of-the-art performance on four public benchmarks.
Exploiting Spatial-Temporal Context for Interacting Hand Reconstruction on Monocular RGB Video
Aug 08, 2023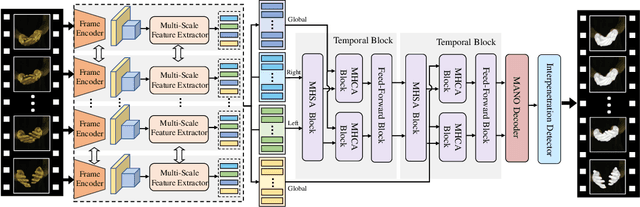
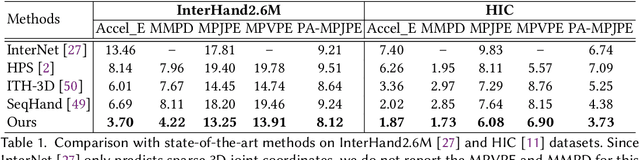
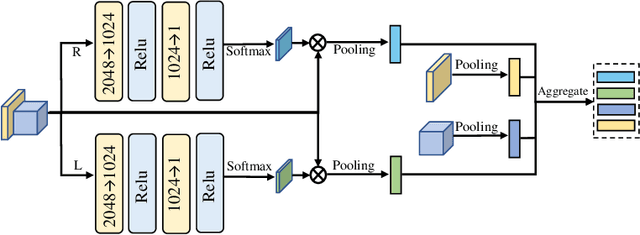
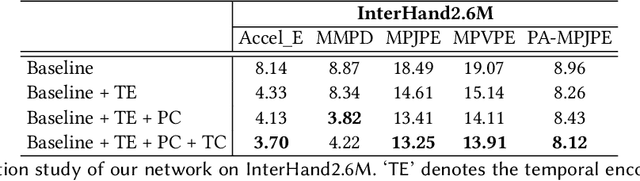
Reconstructing interacting hands from monocular RGB data is a challenging task, as it involves many interfering factors, e.g. self- and mutual occlusion and similar textures. Previous works only leverage information from a single RGB image without modeling their physically plausible relation, which leads to inferior reconstruction results. In this work, we are dedicated to explicitly exploiting spatial-temporal information to achieve better interacting hand reconstruction. On one hand, we leverage temporal context to complement insufficient information provided by the single frame, and design a novel temporal framework with a temporal constraint for interacting hand motion smoothness. On the other hand, we further propose an interpenetration detection module to produce kinetically plausible interacting hands without physical collisions. Extensive experiments are performed to validate the effectiveness of our proposed framework, which achieves new state-of-the-art performance on public benchmarks.
SignBERT+: Hand-model-aware Self-supervised Pre-training for Sign Language Understanding
May 08, 2023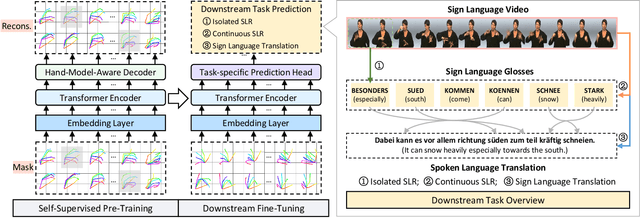
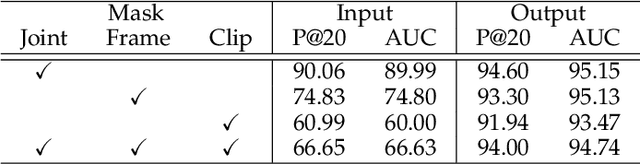
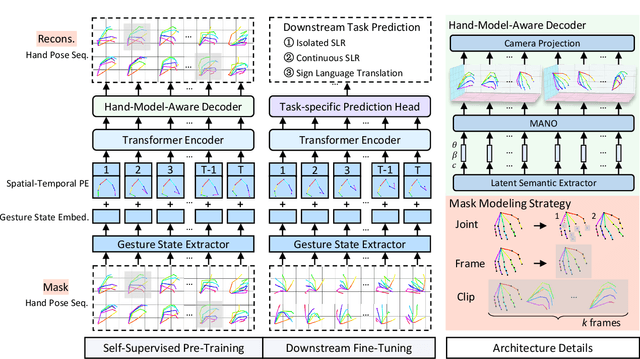
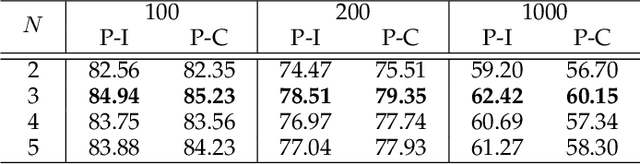
Hand gesture serves as a crucial role during the expression of sign language. Current deep learning based methods for sign language understanding (SLU) are prone to over-fitting due to insufficient sign data resource and suffer limited interpretability. In this paper, we propose the first self-supervised pre-trainable SignBERT+ framework with model-aware hand prior incorporated. In our framework, the hand pose is regarded as a visual token, which is derived from an off-the-shelf detector. Each visual token is embedded with gesture state and spatial-temporal position encoding. To take full advantage of current sign data resource, we first perform self-supervised learning to model its statistics. To this end, we design multi-level masked modeling strategies (joint, frame and clip) to mimic common failure detection cases. Jointly with these masked modeling strategies, we incorporate model-aware hand prior to better capture hierarchical context over the sequence. After the pre-training, we carefully design simple yet effective prediction heads for downstream tasks. To validate the effectiveness of our framework, we perform extensive experiments on three main SLU tasks, involving isolated and continuous sign language recognition (SLR), and sign language translation (SLT). Experimental results demonstrate the effectiveness of our method, achieving new state-of-the-art performance with a notable gain.
BEST: BERT Pre-Training for Sign Language Recognition with Coupling Tokenization
Feb 13, 2023In this work, we are dedicated to leveraging the BERT pre-training success and modeling the domain-specific statistics to fertilize the sign language recognition~(SLR) model. Considering the dominance of hand and body in sign language expression, we organize them as pose triplet units and feed them into the Transformer backbone in a frame-wise manner. Pre-training is performed via reconstructing the masked triplet unit from the corrupted input sequence, which learns the hierarchical correlation context cues among internal and external triplet units. Notably, different from the highly semantic word token in BERT, the pose unit is a low-level signal originally located in continuous space, which prevents the direct adoption of the BERT cross-entropy objective. To this end, we bridge this semantic gap via coupling tokenization of the triplet unit. It adaptively extracts the discrete pseudo label from the pose triplet unit, which represents the semantic gesture/body state. After pre-training, we fine-tune the pre-trained encoder on the downstream SLR task, jointly with the newly added task-specific layer. Extensive experiments are conducted to validate the effectiveness of our proposed method, achieving new state-of-the-art performance on all four benchmarks with a notable gain.