 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up Multimodal Pre-training for Sign Language Understanding
Paper and Code
Aug 16, 2024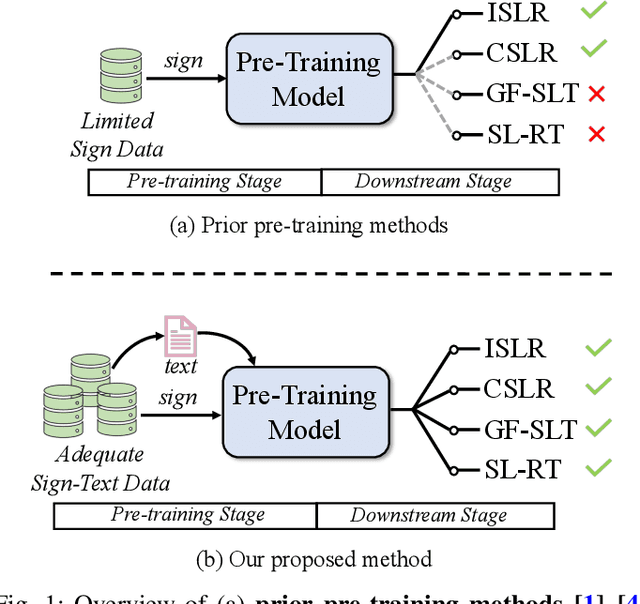



Sign language serves as the primary meaning of communication for the deaf-mute community. Different from spoken language, it commonly conveys information by the collaboration of manual features, i.e., hand gestures and body movements, and non-manual features, i.e., facial expressions and mouth cues. To facilitate communication between the deaf-mute and hearing people, a series of sign language understanding (SLU) tasks have been studied in recent years, including isolated/continuous sign language recognition (ISLR/CSLR), gloss-free sign language translation (GF-SLT) and sign language retrieval (SL-RT). Sign language recognition and translation aims to understand the semantic meaning conveyed by sign languages from gloss-level and sentence-level, respectively. In contrast, SL-RT focuses on retrieving sign videos or corresponding texts from a closed-set under the query-by-example search paradigm. These tasks investigate sign language topics from diverse perspectives and raise challenges in learning effective representation of sign language videos. To advance the development of sign language understanding, exploring a generalized model that is applicable across various SLU tasks is a profound research direction.