 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Uncertainty Quantification of Plug-and-Play Diffusion Priors for Inverse Problems Solving
Feb 04, 2026Plug-and-play diffusion priors (PnPDP) have become a powerful paradigm for solving inverse problems in scientific and engineering domains. Yet, current evaluations of reconstruction quality emphasize point-estimate accuracy metrics on a single sample, which do not reflect the stochastic nature of PnPDP solvers and the intrinsic uncertainty of inverse problems, critical for scientific tasks. This creates a fundamental mismatch: in inverse problems, the desired output is typically a posterior distribution and most PnPDP solvers induce a distribution over reconstructions, but existing benchmarks only evaluate a single reconstruction, ignoring distributional characterization such as uncertainty. To address this gap, we conduct a systematic study to benchmark the uncertainty quantification (UQ) of existing diffusion inverse solvers. Specifically, we design a rigorous toy model simulation to evaluate the uncertainty behavior of various PnPDP solvers, and propose a UQ-driven categorization. Through extensive experiments on toy simulations and diverse real-world scientific inverse problems, we observe uncertainty behaviors consistent with our taxonomy and theoretical justification, providing new insights for evaluating and understanding the uncertainty for PnPDPs.
Progressive Multi-modal Conditional Prompt Tuning
Apr 18, 2024



Pre-trained vision-language models (VLMs) have shown remarkable generalization capabilities via prompting, which leverages VLMs as knowledge bases to extract information beneficial for downstream tasks. However, existing methods primarily employ uni-modal prompting, which only engages a uni-modal branch, failing to simultaneously adjust vision-language (V-L) features. Additionally, the one-pass forward pipeline in VLM encoding struggles to align V-L features that have a huge gap. Confronting these challenges, we propose a novel method, Progressive Multi-modal conditional Prompt Tuning (ProMPT). ProMPT exploits a recurrent structure, optimizing and aligning V-L features by iteratively utilizing image and current encoding information. It comprises an initialization and a multi-modal iterative evolution (MIE) module. Initialization is responsible for encoding image and text using a VLM, followed by a feature filter that selects text features similar to image. MIE then facilitates multi-modal prompting through class-conditional vision prompting, instance-conditional text prompting, and feature filtering. In each MIE iteration, vision prompts are obtained from the filtered text features via a vision generator, promoting image features to focus more on target object during vision prompting. The encoded image features are fed into a text generator to produce text prompts that are more robust to class shift. Thus, V-L features are progressively aligned, enabling advance from coarse to exact classifications. Extensive experiments are conducted in three settings to evaluate the efficacy of ProMPT. The results indicate that ProMPT outperforms existing methods on average across all settings, demonstrating its superior generalization.
Cross-Lingual Transfer for Natural Language Inference via Multilingual Prompt Translator
Mar 19, 2024

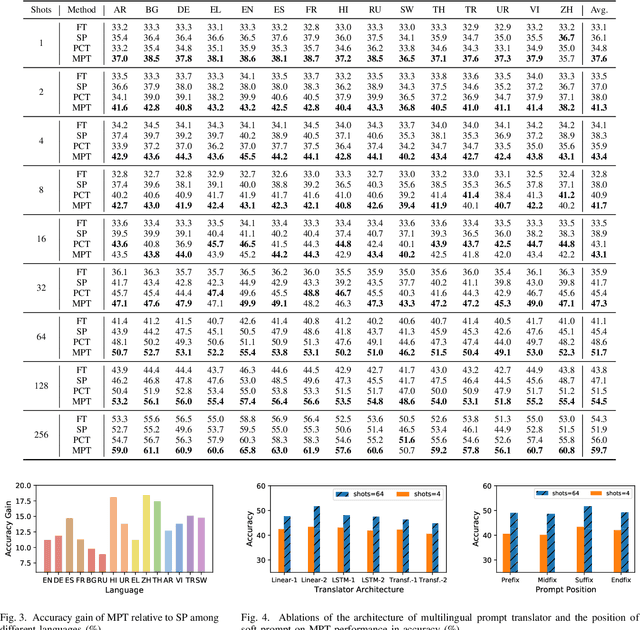

Based on multilingual pre-trained models, cross-lingual transfer with prompt learning has shown promising effectiveness, where soft prompt learned in a source language is transferred to target languages for downstream tasks, particularly in the low-resource scenario. To efficiently transfer soft prompt, we propose a novel framework, Multilingual Prompt Translator (MPT), where a multilingual prompt translator is introduced to properly process crucial knowledge embedded in prompt by changing language knowledge while retaining task knowledge. Concretely, we first train prompt in source language and employ translator to translate it into target prompt. Besides, we extend an external corpus as auxiliary data, on which an alignment task for predicted answer probability is designed to convert language knowledge, thereby equipping target prompt with multilingual knowledge. In few-shot settings on XNLI, MPT demonstrates superiority over baselines by remarkable improvements. MPT is more prominent compared with vanilla prompting when transferring to languages quite distinct from source language.
Intelligence-Endogenous Management Platform for Computing and Network Convergence
Aug 07, 2023



Massive emerging applications are driving demand for the ubiquitous deployment of computing power today. This trend not only spurs the recent popularity of the \emph{Computing and Network Convergence} (CNC), but also introduces an urgent need for the intelligentization of a management platform to coordinate changing resources and tasks in the CNC. Therefore, in this article, we present the concept of an intelligence-endogenous management platform for CNCs called \emph{CNC brain} based on artificial intelligence technologies. It aims at efficiently and automatically matching the supply and demand with high heterogeneity in a CNC via four key building blocks, i.e., perception, scheduling, adaptation, and governance, throughout the CNC's life cycle. Their functionalities, goals, and challenges are presented. To examine the effectiveness of the proposed concept and framework, we also implement a prototype for the CNC brain based on a deep reinforcement learning technology. Also, it is evaluated on a CNC testbed that integrates two open-source and popular frameworks (OpenFaas and Kubernetes) and a real-world business dataset provided by Microsoft Azure. The evaluation results prove the proposed method's effectiveness in terms of resource utilization and performance. Finally, we highlight the future research directions of the CNC brain.
Learning Transferable Pedestrian Representation from Multimodal Information Supervision
Apr 12, 2023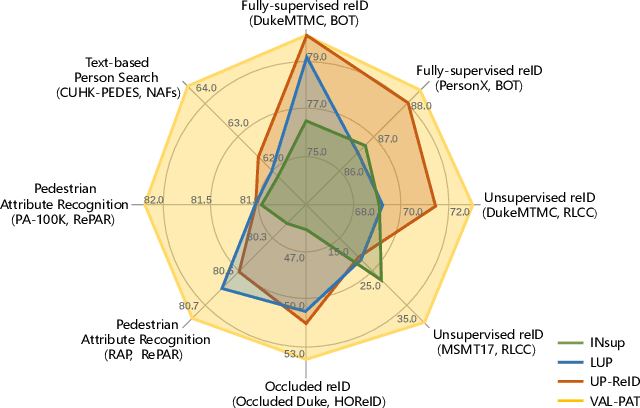

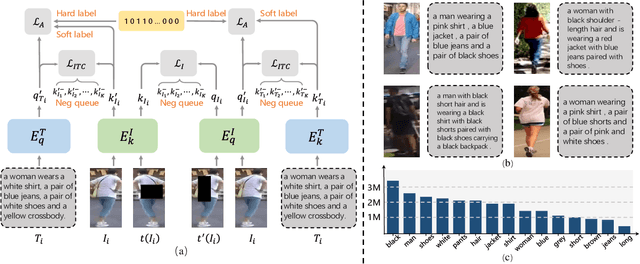

Recent researches on unsupervised person re-identification~(reID) have demonstrated that pre-training on unlabeled person images achieves superior performance on downstream reID tasks than pre-training on ImageNet. However, those pre-trained methods are specifically designed for reID and suffer flexible adaption to other pedestrian analysis tasks. In this paper, we propose VAL-PAT, a novel framework that learns transferable representations to enhance various pedestrian analysis tasks with multimodal information. To train our framework, we introduce three learning objectives, \emph{i.e.,} self-supervised contrastive learning, image-text contrastive learning and multi-attribute classification. The self-supervised contrastive learning facilitates the learning of the intrinsic pedestrian properties, while the image-text contrastive learning guides the model to focus on the appearance information of pedestrians.Meanwhile, multi-attribute classification encourages the model to recognize attributes to excavate fine-grained pedestrian information. We first perform pre-training on LUPerson-TA dataset, where each image contains text and attribute annotations, and then transfer the learned representations to various downstream tasks, including person reID, person attribute recognition and text-based person search. Extensive experiments demonstrate that our framework facilitates the learning of general pedestrian representations and thus leads to promising results on various pedestrian analysis tasks.