 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Pedestrian Representation from Multimodal Information Supervision
Apr 12, 2023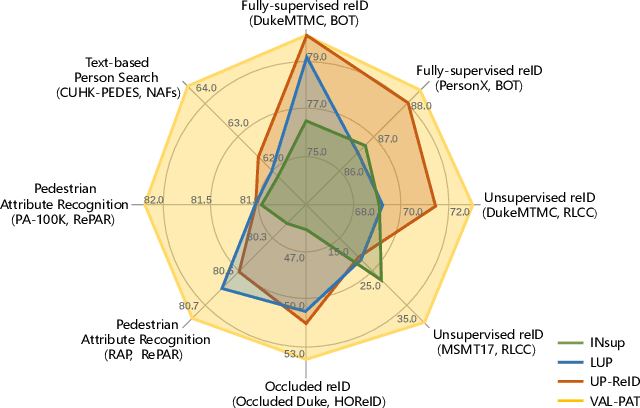

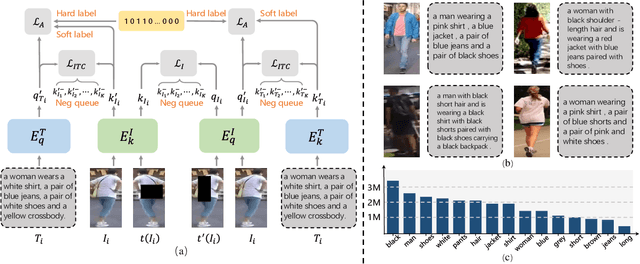

Recent researches on unsupervised person re-identification~(reID) have demonstrated that pre-training on unlabeled person images achieves superior performance on downstream reID tasks than pre-training on ImageNet. However, those pre-trained methods are specifically designed for reID and suffer flexible adaption to other pedestrian analysis tasks. In this paper, we propose VAL-PAT, a novel framework that learns transferable representations to enhance various pedestrian analysis tasks with multimodal information. To train our framework, we introduce three learning objectives, \emph{i.e.,} self-supervised contrastive learning, image-text contrastive learning and multi-attribute classification. The self-supervised contrastive learning facilitates the learning of the intrinsic pedestrian properties, while the image-text contrastive learning guides the model to focus on the appearance information of pedestrians.Meanwhile, multi-attribute classification encourages the model to recognize attributes to excavate fine-grained pedestrian information. We first perform pre-training on LUPerson-TA dataset, where each image contains text and attribute annotations, and then transfer the learned representations to various downstream tasks, including person reID, person attribute recognition and text-based person search. Extensive experiments demonstrate that our framework facilitates the learning of general pedestrian representations and thus leads to promising results on various pedestrian analysis tasks.
Self-Adaptively Learning to Demoire from Focused and Defocused Image Pairs
Nov 05, 2020



Moire artifacts are common in digital photography, resulting from the interference between high-frequency scene content and the color filter array of the camera. Existing deep learning-based demoireing methods trained on large scale datasets are limited in handling various complex moire patterns, and mainly focus on demoireing of photos taken of digital displays. Moreover, obtaining moire-free ground-truth in natural scenes is difficult but needed for training. In this paper, we propose a self-adaptive learning method for demoireing a high-frequency image, with the help of an additional defocused moire-free blur image. Given an image degraded with moire artifacts and a moire-free blur image, our network predicts a moire-free clean image and a blur kernel with a self-adaptive strategy that does not require an explicit training stage, instead performing test-time adaptation. Our model has two sub-networks and works iteratively. During each iteration, one sub-network takes the moire image as input, removing moire patterns and restoring image details, and the other sub-network estimates the blur kernel from the blur image. The two sub-networks are jointly optimized. Extensive experiments demonstrate that our method outperforms state-of-the-art methods and can produce high-quality demoired results. It can generalize well to the task of removing moire artifacts caused by display screens. In addition, we build a new moire dataset, including images with screen and texture moire artifacts. As far as we know, this is the first dataset with real texture moire patterns.