 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Expert Predictions in MoE Inference via Cross-Layer Gate
Feb 17, 2025



Large Language Models (LLMs) have demonstrated impressive performance across various tasks, and their application in edge scenarios has attracted significant attention. However, sparse-activated Mixture-of-Experts (MoE) models, which are well suited for edge scenarios, have received relatively little attention due to their high memory demands. Offload-based methods have been proposed to address this challenge, but they face difficulties with expert prediction. Inaccurate expert predictions can result in prolonged inference delays. To promote the application of MoE models in edge scenarios, we propose Fate, an offloading system designed for MoE models to enable efficient inference in resource-constrained environments. The key insight behind Fate is that gate inputs from adjacent layers can be effectively used for expert prefetching, achieving high prediction accuracy without additional GPU overhead. Furthermore, Fate employs a shallow-favoring expert caching strategy that increases the expert hit rate to 99\%. Additionally, Fate integrates tailored quantization strategies for cache optimization and IO efficiency. Experimental results show that, compared to Load on Demand and Expert Activation Path-based method, Fate achieves up to 4.5x and 1.9x speedups in prefill speed and up to 4.1x and 2.2x speedups in decoding speed, respectively, while maintaining inference quality. Moreover, Fate's performance improvements are scalable across different memory budgets.
Klotski: Efficient Mixture-of-Expert Inference via Expert-Aware Multi-Batch Pipeline
Feb 09, 2025Mixture of Experts (MoE), with its distinctive sparse structure, enables the scaling of language models up to trillions of parameters without significantly increasing computational costs. However, the substantial parameter size presents a challenge for inference, as the expansion in GPU memory cannot keep pace with the growth in parameters. Although offloading techniques utilise memory from the CPU and disk and parallelise the I/O and computation for efficiency, the computation for each expert in MoE models is often less than the I/O, resulting in numerous bubbles in the pipeline. Therefore, we propose Klotski, an efficient MoE inference engine that significantly reduces pipeline bubbles through a novel expert-aware multi-batch pipeline paradigm. The proposed paradigm uses batch processing to extend the computation time of the current layer to overlap with the loading time of the next layer. Although this idea has been effectively applied to dense models, more batches may activate more experts in the MoE, leading to longer loading times and more bubbles. Thus, unlike traditional approaches, we balance computation and I/O time and minimise bubbles by orchestrating their inference orders based on their heterogeneous computation and I/O requirements and activation patterns under different batch numbers. Moreover, to adapt to different hardware environments and models, we design a constraint-sensitive I/O-compute planner and a correlation-aware expert prefetcher for a schedule that minimises pipeline bubbles. Experimental results demonstrate that Klotski achieves a superior throughput-latency trade-off compared to state-of-the-art techniques, with throughput improvements of up to 85.12x.
Training and Serving System of Foundation Models: A Comprehensive Survey
Jan 05, 2024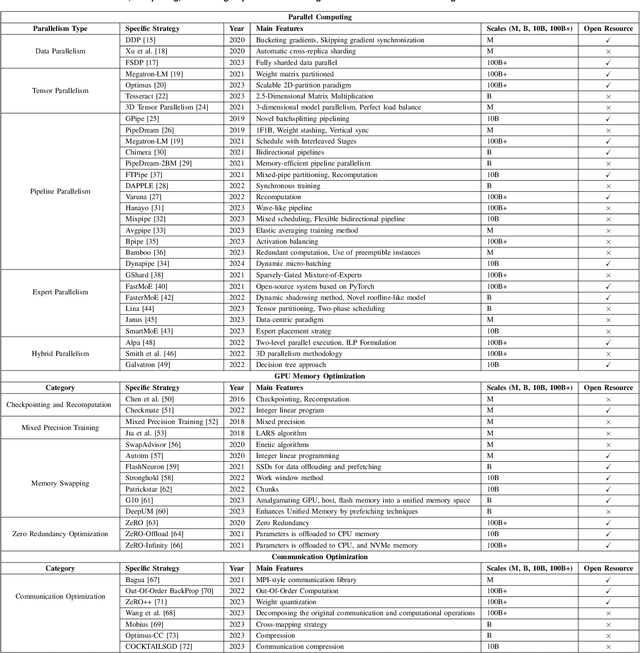
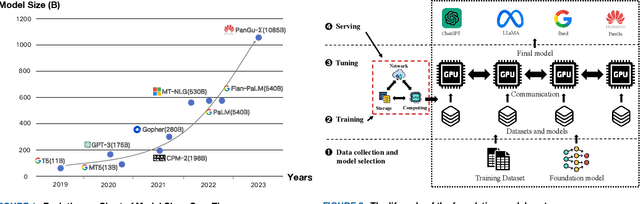
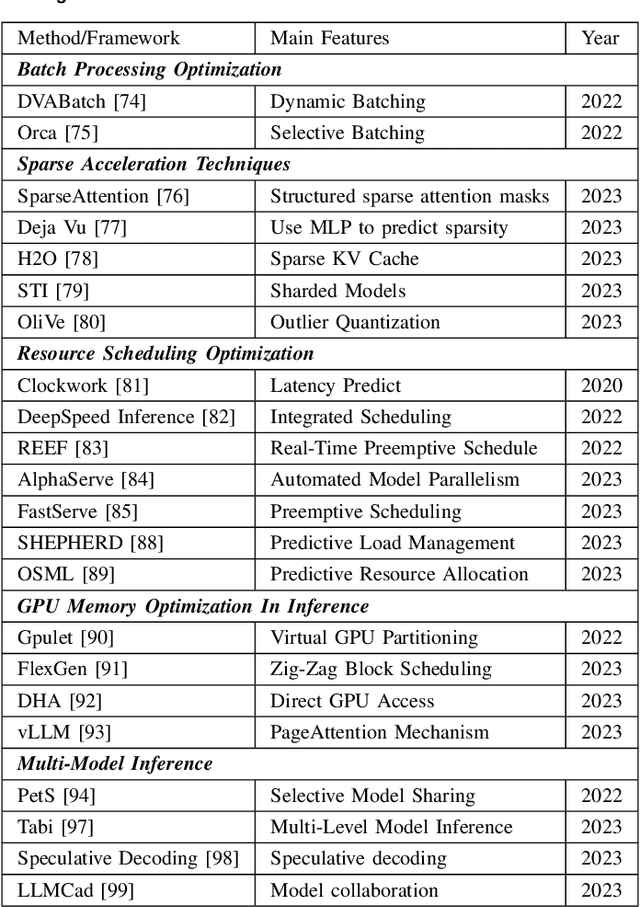
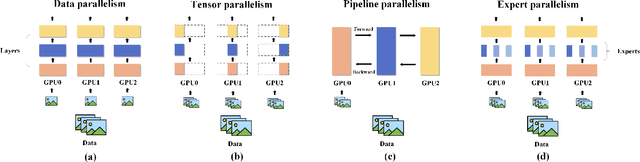
Foundation models (e.g., ChatGPT, DALL-E, PengCheng Mind, PanGu-$\Sigma$) have demonstrated extraordinary performance in key technological areas, such as natural language processing and visual recognition, and have become the mainstream trend of artificial general intelligence. This has led more and more major technology giants to dedicate significant human and financial resources to actively develop their foundation model systems, which drives continuous growth of these models' parameters. As a result, the training and serving of these models have posed significant challenges, including substantial computing power, memory consumption, bandwidth demands, etc. Therefore, employing efficient training and serving strategies becomes particularly crucial. Many researchers have actively explored and proposed effective methods. So, a comprehensive survey of them is essential for system developers and researchers. This paper extensively explores the methods employed in training and serving foundation models from various perspectives. It provides a detailed categorization of these state-of-the-art methods, including finer aspects such as network, computing, and storage. Additionally, the paper summarizes the challenges and presents a perspective on the future development direction of foundation model systems. Through comprehensive discussion and analysis, it hopes to provide a solid theoretical basis and practical guidance for future research and applications, promoting continuous innovation and development in foundation model systems.
Intelligence-Endogenous Management Platform for Computing and Network Convergence
Aug 07, 2023



Massive emerging applications are driving demand for the ubiquitous deployment of computing power today. This trend not only spurs the recent popularity of the \emph{Computing and Network Convergence} (CNC), but also introduces an urgent need for the intelligentization of a management platform to coordinate changing resources and tasks in the CNC. Therefore, in this article, we present the concept of an intelligence-endogenous management platform for CNCs called \emph{CNC brain} based on artificial intelligence technologies. It aims at efficiently and automatically matching the supply and demand with high heterogeneity in a CNC via four key building blocks, i.e., perception, scheduling, adaptation, and governance, throughout the CNC's life cycle. Their functionalities, goals, and challenges are presented. To examine the effectiveness of the proposed concept and framework, we also implement a prototype for the CNC brain based on a deep reinforcement learning technology. Also, it is evaluated on a CNC testbed that integrates two open-source and popular frameworks (OpenFaas and Kubernetes) and a real-world business dataset provided by Microsoft Azure. The evaluation results prove the proposed method's effectiveness in terms of resource utilization and performance. Finally, we highlight the future research directions of the CNC brain.