 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableQnA: Answering List Intent Queries With Web Tables
Paper and Code
Jan 10, 2020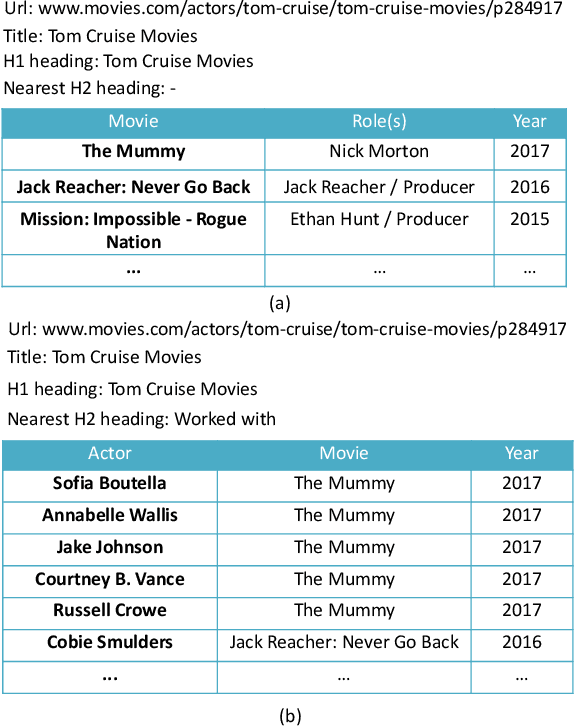
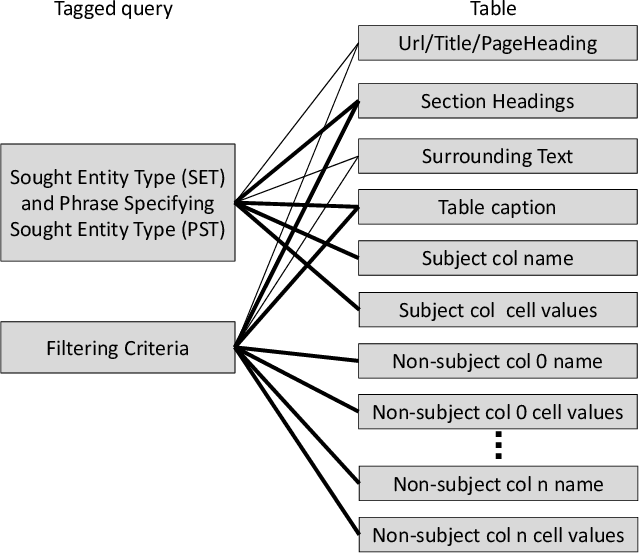

The web contains a vast corpus of HTML tables. They can be used to provide direct answers to many web queries. We focus on answering two classes of queries with those tables: those seeking lists of entities (e.g., `cities in california') and those seeking superlative entities (e.g., `largest city in california'). The main challenge is to achieve high precision with significant coverage. Existing approaches train machine learning models to select the answer from the candidates; they rely on textual match features between the query and the content of the table along with features capturing table quality/importance. These features alone are inadequate for achieving the above goals. Our main insight is that we can improve precision by (i) first extracting intent (structured information) from the query for the above query classes and (ii) then performing structure-aware matching (instead of just textual matching) between the extracted intent and the candidates to select the answer. We model (i) as a sequence tagging task. We leverage state-of-the-art deep neural network models with word embeddings. The model requires large scale training data which is expensive to obtain via manual labeling; we therefore develop a novel method to automatically generate the training data. For (ii), we develop novel features to compute structure-aware match and train a machine learning model. Our experiments on real-life web search queries show that (i) our intent extractor for list and superlative intent queries has significantly higher precision and coverage compared with baseline approaches and (ii) our table answer selector significantly outperforms the state-of-the-art baseline approach. This technology has been used in production by Microsoft's Bing search engine since 2016.