 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Ranking Network for Text-to-SQL
Aug 11, 2020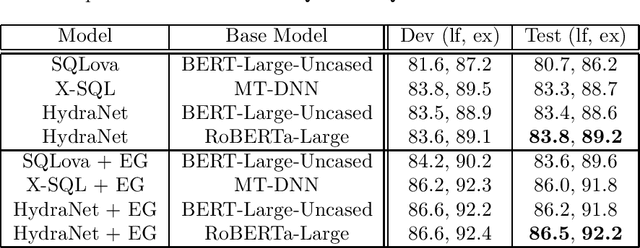
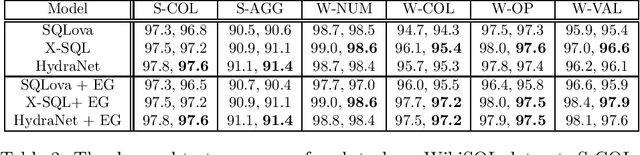
In this paper, we study how to leverage pre-trained language models in Text-to-SQL. We argue that previous approaches under utilize the base language models by concatenating all columns together with the NL question and feeding them into the base language model in the encoding stage. We propose a neat approach called Hybrid Ranking Network (HydraNet) which breaks down the problem into column-wise ranking and decoding and finally assembles the column-wise outputs into a SQL query by straightforward rules. In this approach, the encoder is given a NL question and one individual column, which perfectly aligns with the original tasks BERT/RoBERTa is trained on, and hence we avoid any ad-hoc pooling or additional encoding layers which are necessary in prior approaches. Experiments on the WikiSQL dataset show that the proposed approach is very effective, achieving the top place on the leaderboard.
TableQnA: Answering List Intent Queries With Web Tables
Jan 10, 2020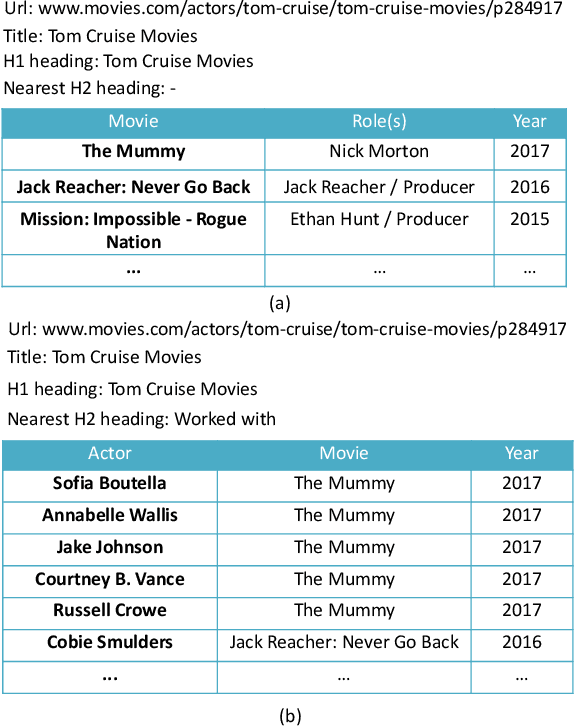

The web contains a vast corpus of HTML tables. They can be used to provide direct answers to many web queries. We focus on answering two classes of queries with those tables: those seeking lists of entities (e.g., `cities in california') and those seeking superlative entities (e.g., `largest city in california'). The main challenge is to achieve high precision with significant coverage. Existing approaches train machine learning models to select the answer from the candidates; they rely on textual match features between the query and the content of the table along with features capturing table quality/importance. These features alone are inadequate for achieving the above goals. Our main insight is that we can improve precision by (i) first extracting intent (structured information) from the query for the above query classes and (ii) then performing structure-aware matching (instead of just textual matching) between the extracted intent and the candidates to select the answer. We model (i) as a sequence tagging task. We leverage state-of-the-art deep neural network models with word embeddings. The model requires large scale training data which is expensive to obtain via manual labeling; we therefore develop a novel method to automatically generate the training data. For (ii), we develop novel features to compute structure-aware match and train a machine learning model. Our experiments on real-life web search queries show that (i) our intent extractor for list and superlative intent queries has significantly higher precision and coverage compared with baseline approaches and (ii) our table answer selector significantly outperforms the state-of-the-art baseline approach. This technology has been used in production by Microsoft's Bing search engine since 2016.
Open Domain Question Answering Using Web Tables
Jan 10, 2020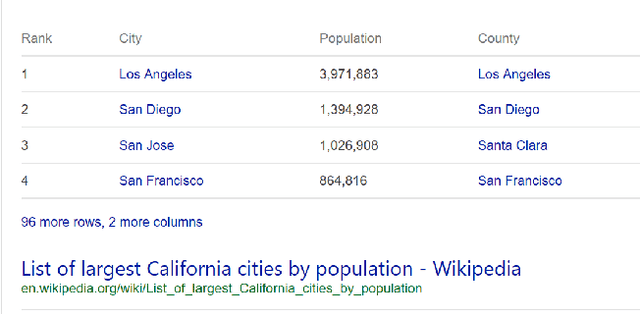

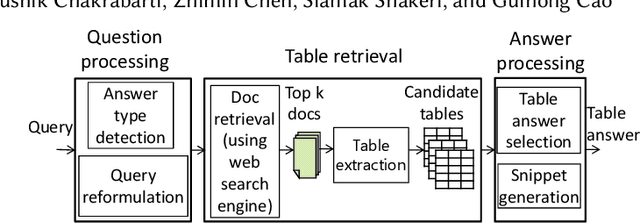
Tables extracted from web documents can be used to directly answer many web search queries. Previous works on question answering (QA) using web tables have focused on factoid queries, i.e., those answerable with a short string like person name or a number. However, many queries answerable using tables are non-factoid in nature. In this paper, we develop an open-domain QA approach using web tables that works for both factoid and non-factoid queries. Our key insight is to combine deep neural network-based semantic similarity between the query and the table with features that quantify the dominance of the table in the document as well as the quality of the information in the table. Our experiments on real-life web search queries show that our approach significantly outperforms state-of-the-art baseline approaches. Our solution is used in production in a major commercial web search engine and serves direct answers for tens of millions of real user queries per month.
X-SQL: reinforce schema representation with context
Aug 21, 2019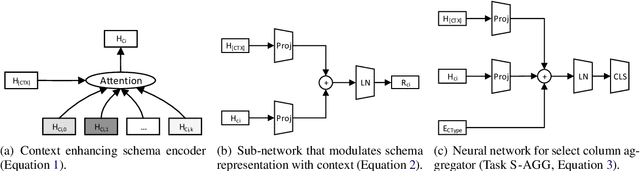


In this work, we present X-SQL, a new network architecture for the problem of parsing natural language to SQL query. X-SQL proposes to enhance the structural schema representation with the contextual output from BERT-style pre-training model, and together with type information to learn a new schema representation for down-stream tasks. We evaluated X-SQL on the WikiSQL dataset and show its new state-of-the-art performance.
IncSQL: Training Incremental Text-to-SQL Parsers with Non-Deterministic Oracles
Oct 01, 2018

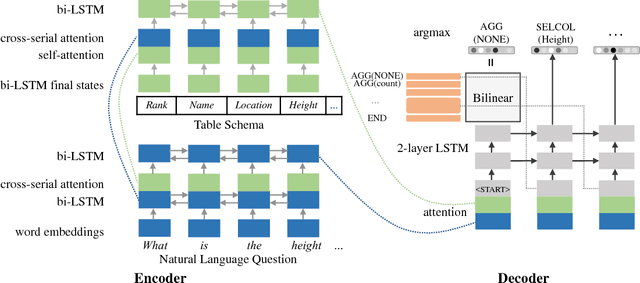
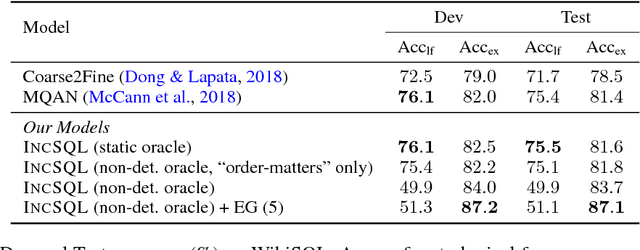
We present a sequence-to-action parsing approach for the natural language to SQL task that incrementally fills the slots of a SQL query with feasible actions from a pre-defined inventory. To account for the fact that typically there are multiple correct SQL queries with the same or very similar semantics, we draw inspiration from syntactic parsing techniques and propose to train our sequence-to-action models with non-deterministic oracles. We evaluate our models on the WikiSQL dataset and achieve an execution accuracy of 83.7% on the test set, a 2.1% absolute improvement over the models trained with traditional static oracles assuming a single correct target SQL query. When further combined with the execution-guided decoding strategy, our model sets a new state-of-the-art performance at an execution accuracy of 87.1%.