 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Ranking Network for Text-to-SQL
Paper and Code
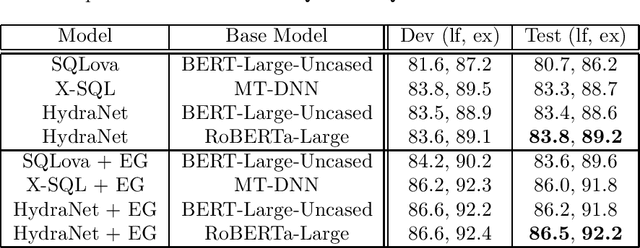
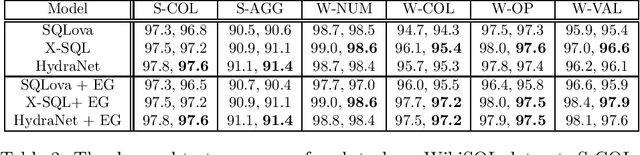
In this paper, we study how to leverage pre-trained language models in Text-to-SQL. We argue that previous approaches under utilize the base language models by concatenating all columns together with the NL question and feeding them into the base language model in the encoding stage. We propose a neat approach called Hybrid Ranking Network (HydraNet) which breaks down the problem into column-wise ranking and decoding and finally assembles the column-wise outputs into a SQL query by straightforward rules. In this approach, the encoder is given a NL question and one individual column, which perfectly aligns with the original tasks BERT/RoBERTa is trained on, and hence we avoid any ad-hoc pooling or additional encoding layers which are necessary in prior approaches. Experiments on the WikiSQL dataset show that the proposed approach is very effective, achieving the top place on the leaderboard.