 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Careful Examination of Large Language Model Performance on Grade School Arithmetic
May 02, 2024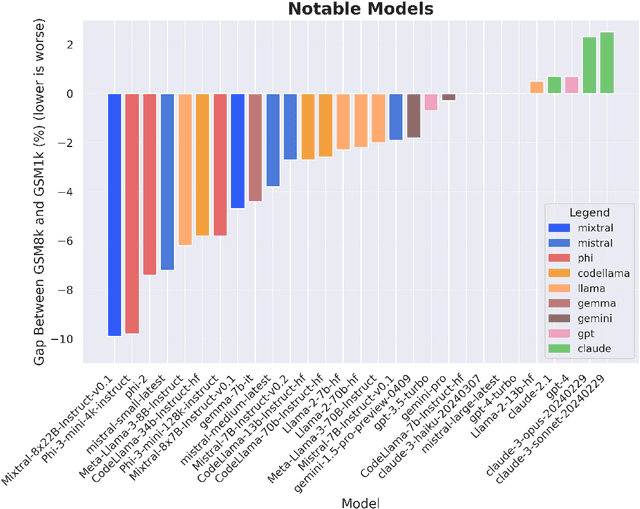

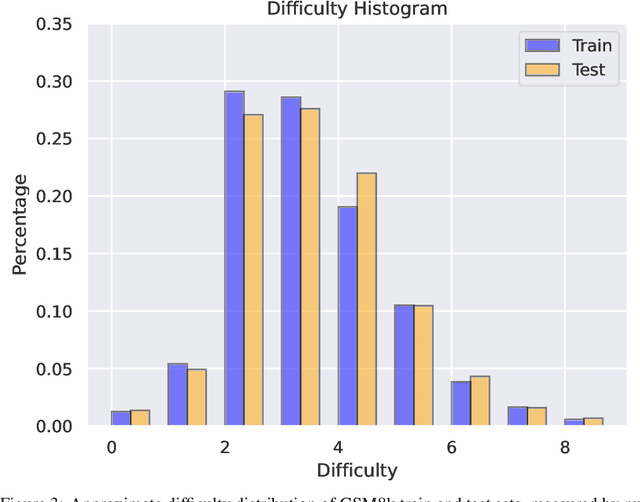
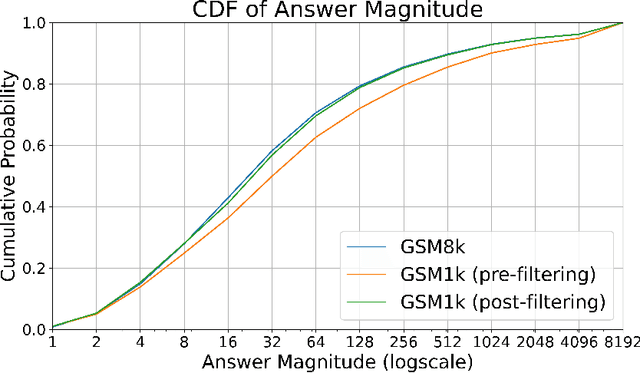
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes. At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman's r^2=0.32) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
Multi-Stage Transmission Line Flow Control Using Centralized and Decentralized Reinforcement Learning Agents
Feb 16, 2021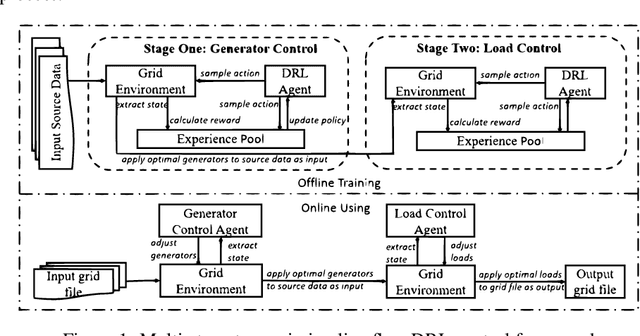
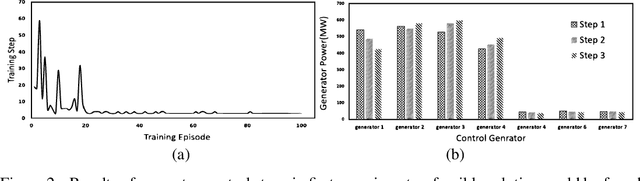
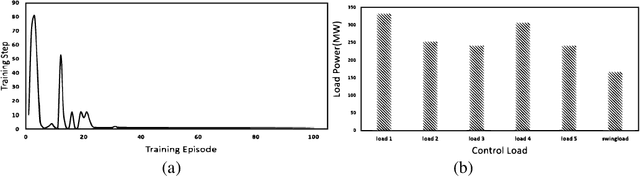
Planning future operational scenarios of bulk power systems that meet security and economic constraints typically requires intensive labor efforts in performing massive simulations. To automate this process and relieve engineers' burden, a novel multi-stage control approach is presented in this paper to train centralized and decentralized reinforcement learning agents that can automatically adjust grid controllers for regulating transmission line flows at normal condition and under contingencies. The power grid flow control problem is formulated as Markov Decision Process (MDP). At stage one, centralized soft actor-critic (SAC) agent is trained to control generator active power outputs in a wide area to control transmission line flows against specified security limits. If line overloading issues remain unresolved, stage two is used to train decentralized SAC agent via load throw-over at local substations. The effectiveness of the proposed approach is verified on a series of actual planning cases used for operating the power grid of SGCC Zhejiang Electric Power Company.
Hybrid Ranking Network for Text-to-SQL
Aug 11, 2020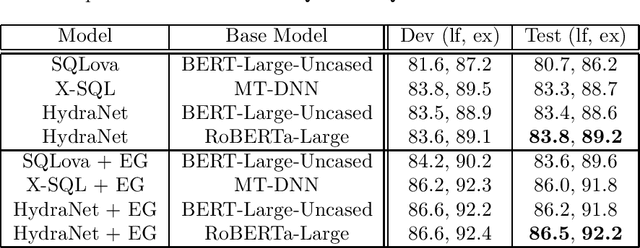
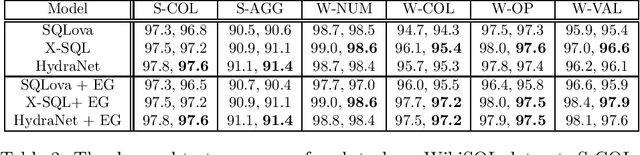
In this paper, we study how to leverage pre-trained language models in Text-to-SQL. We argue that previous approaches under utilize the base language models by concatenating all columns together with the NL question and feeding them into the base language model in the encoding stage. We propose a neat approach called Hybrid Ranking Network (HydraNet) which breaks down the problem into column-wise ranking and decoding and finally assembles the column-wise outputs into a SQL query by straightforward rules. In this approach, the encoder is given a NL question and one individual column, which perfectly aligns with the original tasks BERT/RoBERTa is trained on, and hence we avoid any ad-hoc pooling or additional encoding layers which are necessary in prior approaches. Experiments on the WikiSQL dataset show that the proposed approach is very effective, achieving the top place on the leaderboard.