 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Ranking Network for Text-to-SQL
Aug 11, 2020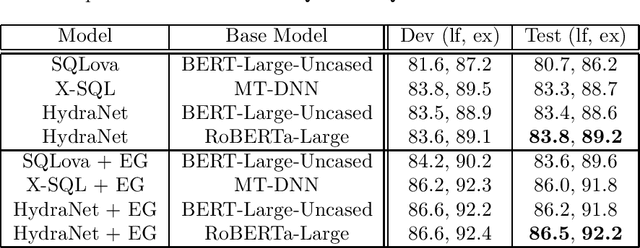
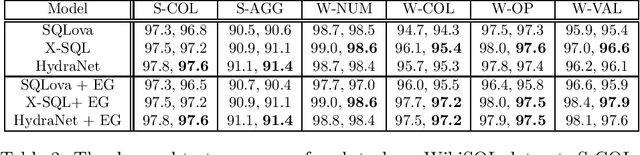
In this paper, we study how to leverage pre-trained language models in Text-to-SQL. We argue that previous approaches under utilize the base language models by concatenating all columns together with the NL question and feeding them into the base language model in the encoding stage. We propose a neat approach called Hybrid Ranking Network (HydraNet) which breaks down the problem into column-wise ranking and decoding and finally assembles the column-wise outputs into a SQL query by straightforward rules. In this approach, the encoder is given a NL question and one individual column, which perfectly aligns with the original tasks BERT/RoBERTa is trained on, and hence we avoid any ad-hoc pooling or additional encoding layers which are necessary in prior approaches. Experiments on the WikiSQL dataset show that the proposed approach is very effective, achieving the top place on the leaderboard.
Community Member Retrieval on Social Media using Textual Information
Apr 16, 2018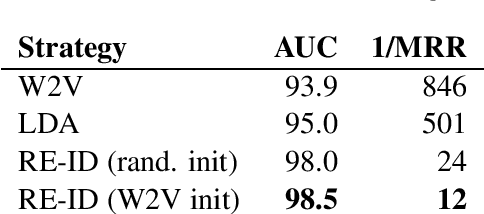
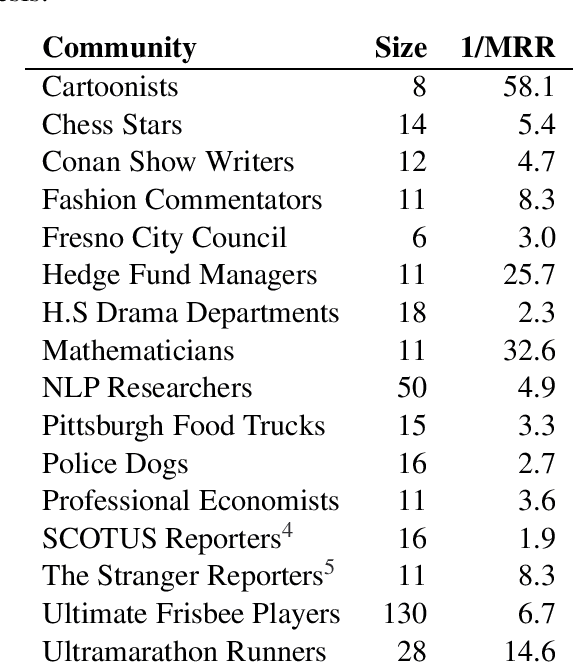

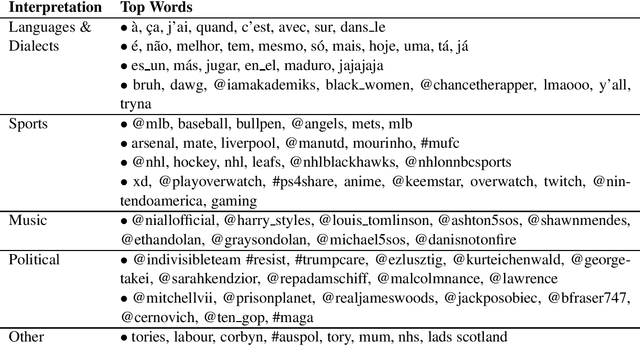
This paper addresses the problem of community membership detection using only text features in a scenario where a small number of positive labeled examples defines the community. The solution introduces an unsupervised proxy task for learning user embeddings: user re-identification. Experiments with 16 different communities show that the resulting embeddings are more effective for community membership identification than common unsupervised representations.
Hierarchical Character-Word Models for Language Identification
Aug 10, 2016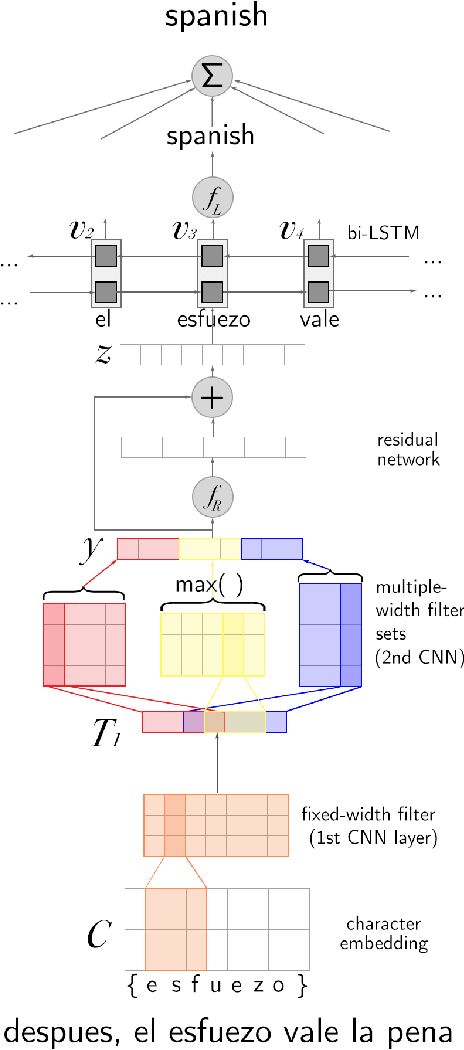
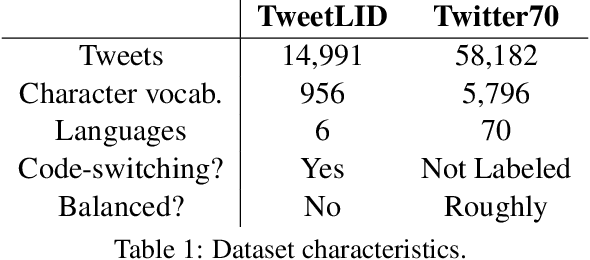
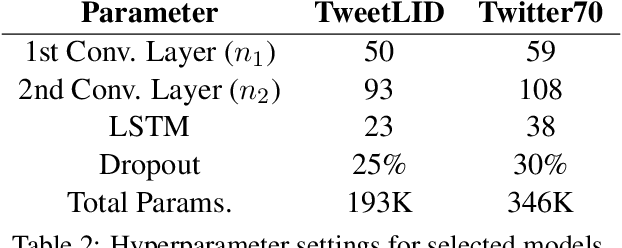
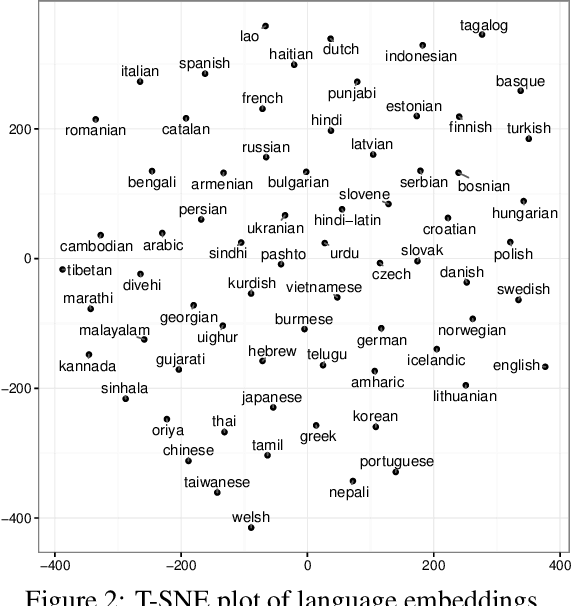
Social media messages' brevity and unconventional spelling pose a challenge to language identification. We introduce a hierarchical model that learns character and contextualized word-level representations for language identification. Our method performs well against strong base- lines, and can also reveal code-switching.