 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent VLMs Guided Self-Training with PNU Loss for Low-Resource Offensive Content Detection
Nov 14, 2025



Accurate detection of offensive content on social media demands high-quality labeled data; however, such data is often scarce due to the low prevalence of offensive instances and the high cost of manual annotation. To address this low-resource challenge, we propose a self-training framework that leverages abundant unlabeled data through collaborative pseudo-labeling. Starting with a lightweight classifier trained on limited labeled data, our method iteratively assigns pseudo-labels to unlabeled instances with the support of Multi-Agent Vision-Language Models (MA-VLMs). Un-labeled data on which the classifier and MA-VLMs agree are designated as the Agreed-Unknown set, while conflicting samples form the Disagreed-Unknown set. To enhance label reliability, MA-VLMs simulate dual perspectives, moderator and user, capturing both regulatory and subjective viewpoints. The classifier is optimized using a novel Positive-Negative-Unlabeled (PNU) loss, which jointly exploits labeled, Agreed-Unknown, and Disagreed-Unknown data while mitigating pseudo-label noise. Experiments on benchmark datasets demonstrate that our framework substantially outperforms baselines under limited supervision and approaches the performance of large-scale models
Strengthened Symbol Binding Makes Large Language Models Reliable Multiple-Choice Selectors
Jun 03, 2024Multiple-Choice Questions (MCQs) constitute a critical area of research in the study of Large Language Models (LLMs). Previous works have investigated the selection bias problem in MCQs within few-shot scenarios, in which the LLM's performance may be influenced by the presentation of answer choices, leaving the selection bias during Supervised Fine-Tuning (SFT) unexplored. In this paper, we reveal that selection bias persists in the SFT phase , primarily due to the LLM's inadequate Multiple Choice Symbol Binding (MCSB) ability. This limitation implies that the model struggles to associate the answer options with their corresponding symbols (e.g., A/B/C/D) effectively. To enhance the model's MCSB capability, we first incorporate option contents into the loss function and subsequently adjust the weights of the option symbols and contents, guiding the model to understand the option content of the current symbol. Based on this, we introduce an efficient SFT algorithm for MCQs, termed Point-wise Intelligent Feedback (PIF). PIF constructs negative instances by randomly combining the incorrect option contents with all candidate symbols, and proposes a point-wise loss to provide feedback on these negative samples into LLMs. Our experimental results demonstrate that PIF significantly reduces the model's selection bias by improving its MCSB capability. Remarkably, PIF exhibits a substantial enhancement in the accuracy for MCQs.
* Accept at ACL2024 Main
Enhancing Reinforcement Learning with Label-Sensitive Reward for Natural Language Understanding
May 30, 2024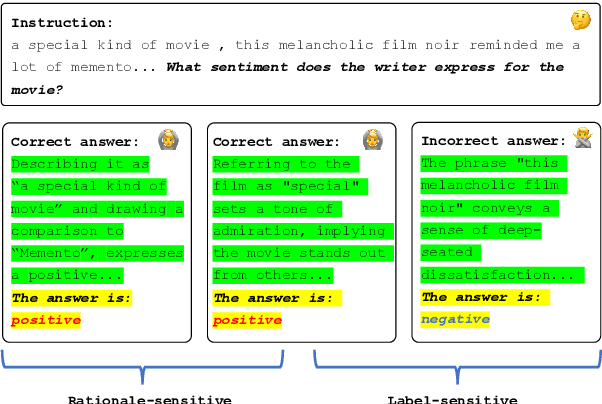



Recent strides in large language models (LLMs) have yielded remarkable performance, leveraging reinforcement learning from human feedback (RLHF) to significantly enhance generation and alignment capabilities. However, RLHF encounters numerous challenges, including the objective mismatch issue, leading to suboptimal performance in Natural Language Understanding (NLU) tasks. To address this limitation, we propose a novel Reinforcement Learning framework enhanced with Label-sensitive Reward (RLLR) to amplify the performance of LLMs in NLU tasks. By incorporating label-sensitive pairs into reinforcement learning, our method aims to adeptly capture nuanced label-sensitive semantic features during RL, thereby enhancing natural language understanding. Experiments conducted on five diverse foundation models across eight tasks showcase promising results. In comparison to Supervised Fine-tuning models (SFT), RLLR demonstrates an average performance improvement of 1.54%. Compared with RLHF models, the improvement averages at 0.69%. These results reveal the effectiveness of our method for LLMs in NLU tasks. Code and data available at: https://github.com/MagiaSN/ACL2024_RLLR.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022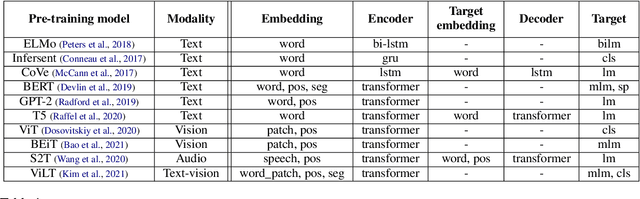
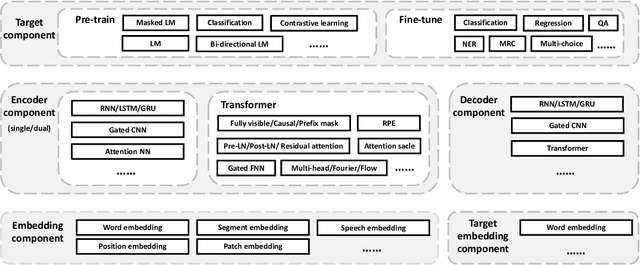
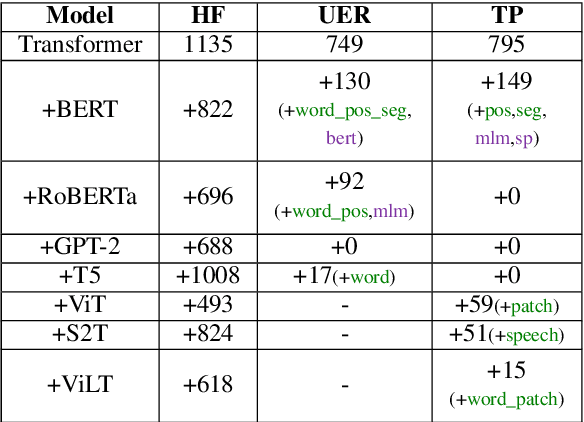
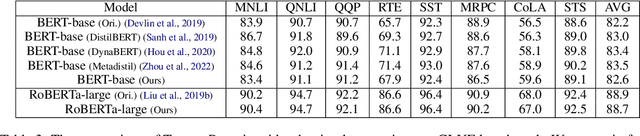
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
Mixture of Virtual-Kernel Experts for Multi-Objective User Profile Modeling
Jun 04, 2021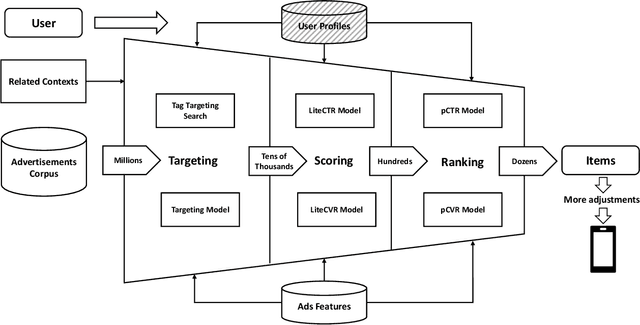

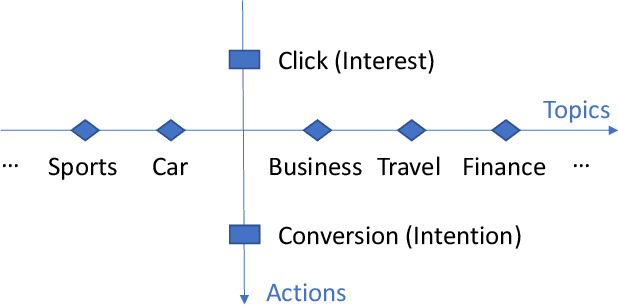
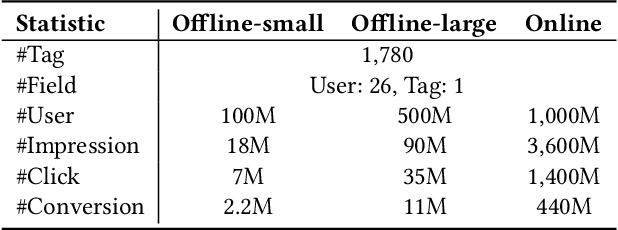
In many industrial applications like online advertising and recommendation systems, diverse and accurate user profiles can greatly help improve personalization. For building user profiles, deep learning is widely used to mine expressive tags to describe users' preferences from their historical actions. For example, tags mined from users' click-action history can represent the categories of ads that users are interested in, and they are likely to continue being clicked in the future. Traditional solutions usually introduce multiple independent Two-Tower models to mine tags from different actions, e.g., click, conversion. However, the models cannot learn complementarily and support effective training for data-sparse actions. Besides, limited by the lack of information fusion between the two towers, the model learning is insufficient to represent users' preferences on various topics well. This paper introduces a novel multi-task model called Mixture of Virtual-Kernel Experts (MVKE) to learn multiple topic-related user preferences based on different actions unitedly. In MVKE, we propose a concept of Virtual-Kernel Expert, which focuses on modeling one particular facet of the user's preference, and all of them learn coordinately. Besides, the gate-based structure used in MVKE builds an information fusion bridge between two towers, improving the model's capability much and maintaining high efficiency. We apply the model in Tencent Advertising System, where both online and offline evaluations show that our method has a significant improvement compared with the existing ones and brings about an obvious lift to actual advertising revenue.
Keyphrase Extraction with Span-based Feature Representations
Feb 13, 2020
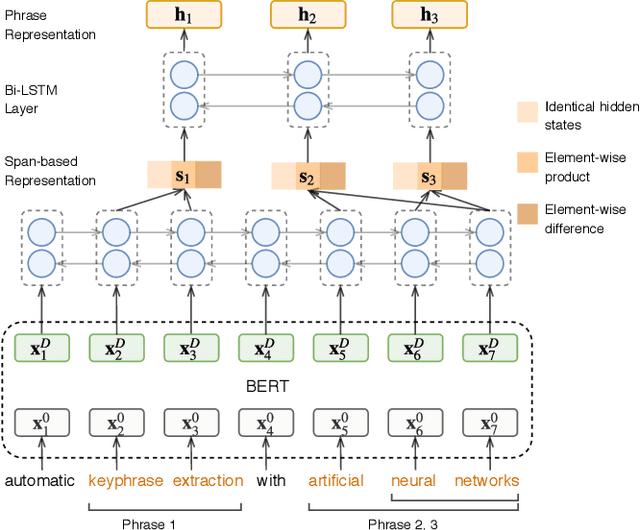

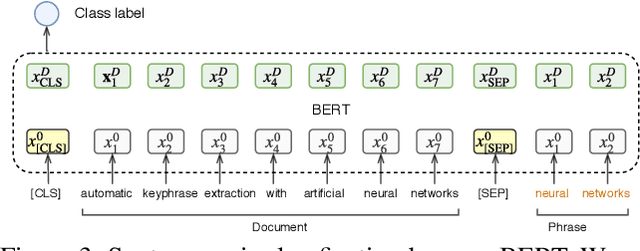
Keyphrases are capable of providing semantic metadata characterizing documents and producing an overview of the content of a document. Since keyphrase extraction is able to facilitate the management, categorization, and retrieval of information, it has received much attention in recent years. There are three approaches to address keyphrase extraction: (i) traditional two-step ranking method, (ii) sequence labeling and (iii) generation using neural networks. Two-step ranking approach is based on feature engineering, which is labor intensive and domain dependent. Sequence labeling is not able to tackle overlapping phrases. Generation methods (i.e., Sequence-to-sequence neural network models) overcome those shortcomings, so they have been widely studied and gain state-of-the-art performance. However, generation methods can not utilize context information effectively. In this paper, we propose a novelty Span Keyphrase Extraction model that extracts span-based feature representation of keyphrase directly from all the content tokens. In this way, our model obtains representation for each keyphrase and further learns to capture the interaction between keyphrases in one document to get better ranking results. In addition, with the help of tokens, our model is able to extract overlapped keyphrases. Experimental results on the benchmark datasets show that our proposed model outperforms the existing methods by a large margin.