 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Point Clouds Transformer for 3D Object Detection
Sep 08, 2023The annotation of 3D datasets is required for semantic-segmentation and object detection in scene understanding. In this paper we present a framework for the weakly supervision of a point clouds transformer that is used for 3D object detection. The aim is to decrease the required amount of supervision needed for training, as a result of the high cost of annotating a 3D datasets. We propose an Unsupervised Voting Proposal Module, which learns randomly preset anchor points and uses voting network to select prepared anchor points of high quality. Then it distills information into student and teacher network. In terms of student network, we apply ResNet network to efficiently extract local characteristics. However, it also can lose much global information. To provide the input which incorporates the global and local information as the input of student networks, we adopt the self-attention mechanism of transformer to extract global features, and the ResNet layers to extract region proposals. The teacher network supervises the classification and regression of the student network using the pre-trained model on ImageNet. On the challenging KITTI datasets, the experimental results have achieved the highest level of average precision compared with the most recent weakly supervised 3D object detectors.
Mixture of Virtual-Kernel Experts for Multi-Objective User Profile Modeling
Jun 04, 2021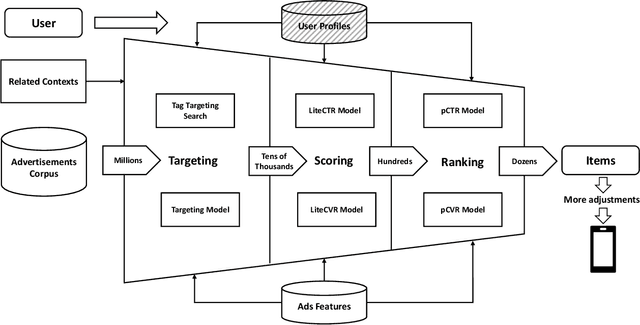

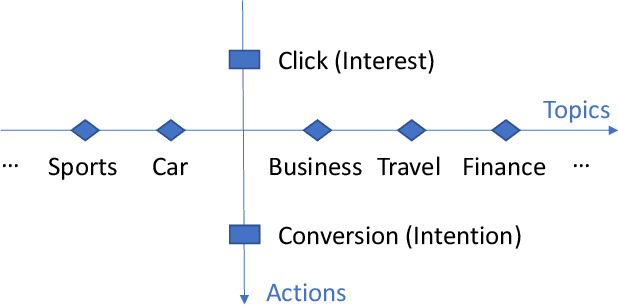
In many industrial applications like online advertising and recommendation systems, diverse and accurate user profiles can greatly help improve personalization. For building user profiles, deep learning is widely used to mine expressive tags to describe users' preferences from their historical actions. For example, tags mined from users' click-action history can represent the categories of ads that users are interested in, and they are likely to continue being clicked in the future. Traditional solutions usually introduce multiple independent Two-Tower models to mine tags from different actions, e.g., click, conversion. However, the models cannot learn complementarily and support effective training for data-sparse actions. Besides, limited by the lack of information fusion between the two towers, the model learning is insufficient to represent users' preferences on various topics well. This paper introduces a novel multi-task model called Mixture of Virtual-Kernel Experts (MVKE) to learn multiple topic-related user preferences based on different actions unitedly. In MVKE, we propose a concept of Virtual-Kernel Expert, which focuses on modeling one particular facet of the user's preference, and all of them learn coordinately. Besides, the gate-based structure used in MVKE builds an information fusion bridge between two towers, improving the model's capability much and maintaining high efficiency. We apply the model in Tencent Advertising System, where both online and offline evaluations show that our method has a significant improvement compared with the existing ones and brings about an obvious lift to actual advertising revenue.
MC-BERT: Efficient Language Pre-Training via a Meta Controller
Jun 16, 2020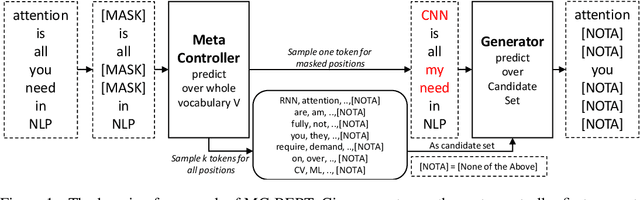

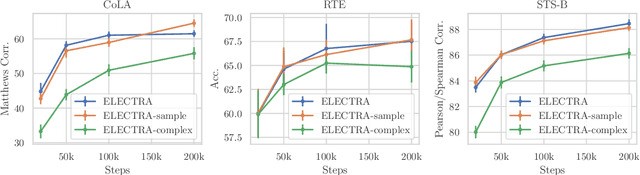

Pre-trained contextual representations (e.g., BERT) have become the foundation to achieve state-of-the-art results on many NLP tasks. However, large-scale pre-training is computationally expensive. ELECTRA, an early attempt to accelerate pre-training, trains a discriminative model that predicts whether each input token was replaced by a generator. Our studies reveal that ELECTRA's success is mainly due to its reduced complexity of the pre-training task: the binary classification (replaced token detection) is more efficient to learn than the generation task (masked language modeling). However, such a simplified task is less semantically informative. To achieve better efficiency and effectiveness, we propose a novel meta-learning framework, MC-BERT. The pre-training task is a multi-choice cloze test with a reject option, where a meta controller network provides training input and candidates. Results over GLUE natural language understanding benchmark demonstrate that our proposed method is both efficient and effective: it outperforms baselines on GLUE semantic tasks given the same computational budget.
Light Multi-segment Activation for Model Compression
Jul 16, 2019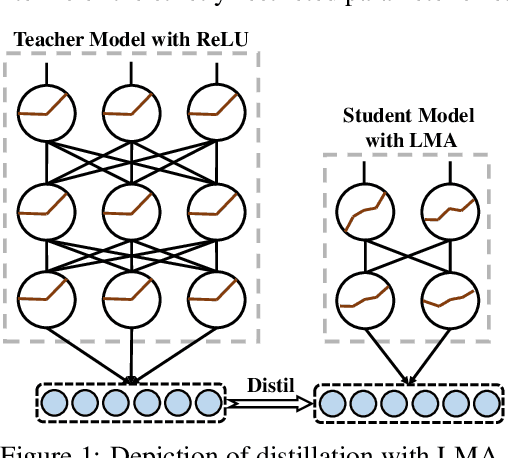

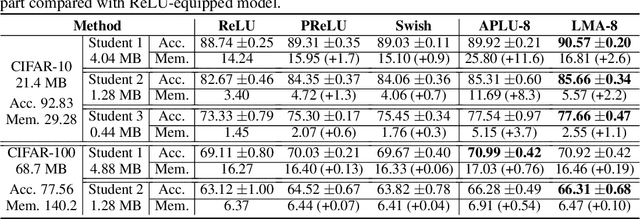
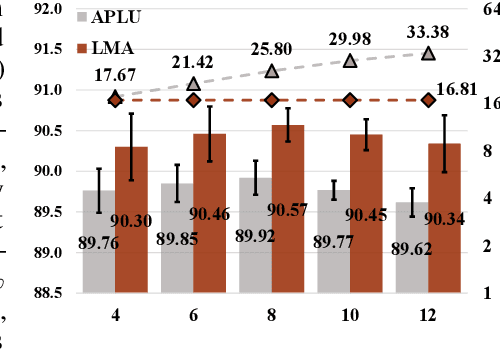
Model compression has become necessary when applying neural networks (NN) into many real application tasks that can accept slightly-reduced model accuracy with strict tolerance to model complexity. Recently, Knowledge Distillation, which distills the knowledge from well-trained and highly complex teacher model into a compact student model, has been widely used for model compression. However, under the strict requirement on the resource cost, it is quite challenging to achieve comparable performance with the teacher model, essentially due to the drastically-reduced expressiveness ability of the compact student model. Inspired by the nature of the expressiveness ability in Neural Networks, we propose to use multi-segment activation, which can significantly improve the expressiveness ability with very little cost, in the compact student model. Specifically, we propose a highly efficient multi-segment activation, called Light Multi-segment Activation (LMA), which can rapidly produce multiple linear regions with very few parameters by leveraging the statistical information. With using LMA, the compact student model is capable of achieving much better performance effectively and efficiently, than the ReLU-equipped one with same model scale. Furthermore, the proposed method is compatible with other model compression techniques, such as quantization, which means they can be used jointly for better compression performance. Experiments on state-of-the-art NN architectures over the real-world tasks demonstrate the effectiveness and extensibility of the LMA.