 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Build a Pre-trained Multimodal model for Simultaneously Chatting and Decision-making?
Oct 21, 2024



Existing large pre-trained models typically map text input to text output in an end-to-end manner, such as ChatGPT, or map a segment of text input to a hierarchy of action decisions, such as OpenVLA. However, humans can simultaneously generate text and actions when receiving specific input signals. For example, a driver can make precise driving decisions while conversing with a friend in the passenger seat. Motivated by this observation, we consider the following question in this work: is it possible to construct a pre-trained model that can provide both language interaction and precise decision-making capabilities in dynamic open scenarios. We provide a definitive answer to this question by developing a new model architecture termed Visual Language Action model for Chatting and Decision Making (VLA4CD), and further demonstrating its performance in challenging autonomous driving tasks. Specifically, we leverage LoRA to fine-tune a pre-trained LLM with data of multiple modalities covering language, visual, and action. Unlike the existing LoRA operations used for LLM fine-tuning, we have designed new computational modules and training cost functions for VLA4CD. These designs enable VLA4CD to provide continuous-valued action decisions while outputting text responses. In contrast, existing LLMs can only output text responses, and current VLA models can only output action decisions. Moreover, these VLA models handle action data by discretizing and then tokenizing the discretized actions, a method unsuitable for complex decision-making tasks involving high-dimensional continuous-valued action vectors, such as autonomous driving. The experimental results on CARLA validate that: (1) our proposed model construction method is effective; (2) compared to the SOTA VLA model, VLA4CD can provide more accurate real-time decision-making while retaining the text interaction capability inherent to LLMs.
Safe and Generalized end-to-end Autonomous Driving System with Reinforcement Learning and Demonstrations
Jan 29, 2024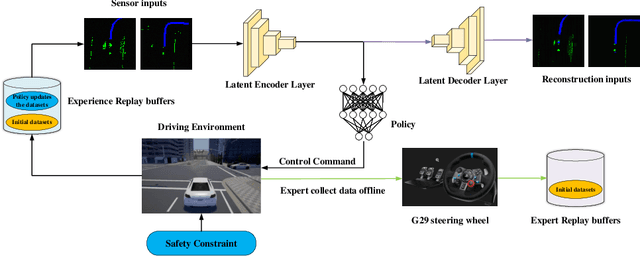
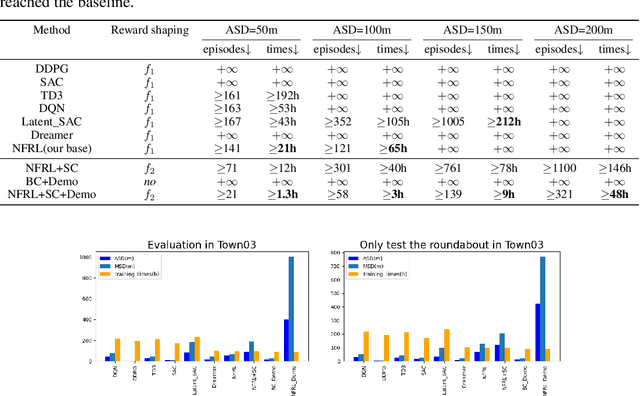
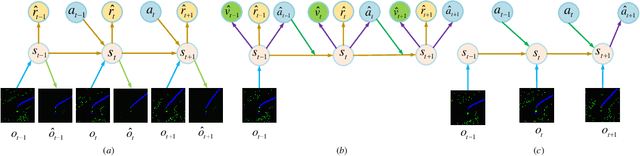
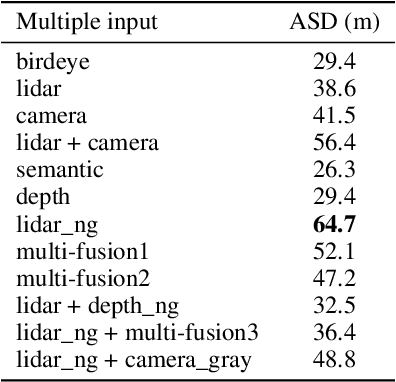
An intelligent driving system should be capable of dynamically formulating appropriate driving strategies based on the current environment and vehicle status, while ensuring the security and reliability of the system. However, existing methods based on reinforcement learning and imitation learning suffer from low safety, poor generalization, and inefficient sampling. Additionally, they cannot accurately predict future driving trajectories, and the accurate prediction of future driving trajectories is a precondition for making optimal decisions. To solve these problems, in this paper, we introduce a Safe and Generalized end-to-end Autonomous Driving System (SGADS) for complex and various scenarios. Our SGADS incorporates variational inference with normalizing flows, enabling the intelligent vehicle to accurately predict future driving trajectories. Moreover, we propose the formulation of robust safety constraints. Furthermore, we combine reinforcement learning with demonstrations to augment search process of the agent. The experimental results demonstrate that our SGADS can significantly improve safety performance, exhibit strong generalization, and enhance the training efficiency of intelligent vehicles in complex urban scenarios compared to existing methods.
Weakly Supervised Point Clouds Transformer for 3D Object Detection
Sep 08, 2023The annotation of 3D datasets is required for semantic-segmentation and object detection in scene understanding. In this paper we present a framework for the weakly supervision of a point clouds transformer that is used for 3D object detection. The aim is to decrease the required amount of supervision needed for training, as a result of the high cost of annotating a 3D datasets. We propose an Unsupervised Voting Proposal Module, which learns randomly preset anchor points and uses voting network to select prepared anchor points of high quality. Then it distills information into student and teacher network. In terms of student network, we apply ResNet network to efficiently extract local characteristics. However, it also can lose much global information. To provide the input which incorporates the global and local information as the input of student networks, we adopt the self-attention mechanism of transformer to extract global features, and the ResNet layers to extract region proposals. The teacher network supervises the classification and regression of the student network using the pre-trained model on ImageNet. On the challenging KITTI datasets, the experimental results have achieved the highest level of average precision compared with the most recent weakly supervised 3D object detectors.