 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrengthened Symbol Binding Makes Large Language Models Reliable Multiple-Choice Selectors
Jun 03, 2024Multiple-Choice Questions (MCQs) constitute a critical area of research in the study of Large Language Models (LLMs). Previous works have investigated the selection bias problem in MCQs within few-shot scenarios, in which the LLM's performance may be influenced by the presentation of answer choices, leaving the selection bias during Supervised Fine-Tuning (SFT) unexplored. In this paper, we reveal that selection bias persists in the SFT phase , primarily due to the LLM's inadequate Multiple Choice Symbol Binding (MCSB) ability. This limitation implies that the model struggles to associate the answer options with their corresponding symbols (e.g., A/B/C/D) effectively. To enhance the model's MCSB capability, we first incorporate option contents into the loss function and subsequently adjust the weights of the option symbols and contents, guiding the model to understand the option content of the current symbol. Based on this, we introduce an efficient SFT algorithm for MCQs, termed Point-wise Intelligent Feedback (PIF). PIF constructs negative instances by randomly combining the incorrect option contents with all candidate symbols, and proposes a point-wise loss to provide feedback on these negative samples into LLMs. Our experimental results demonstrate that PIF significantly reduces the model's selection bias by improving its MCSB capability. Remarkably, PIF exhibits a substantial enhancement in the accuracy for MCQs.
* Accept at ACL2024 Main
Enhancing Reinforcement Learning with Label-Sensitive Reward for Natural Language Understanding
May 30, 2024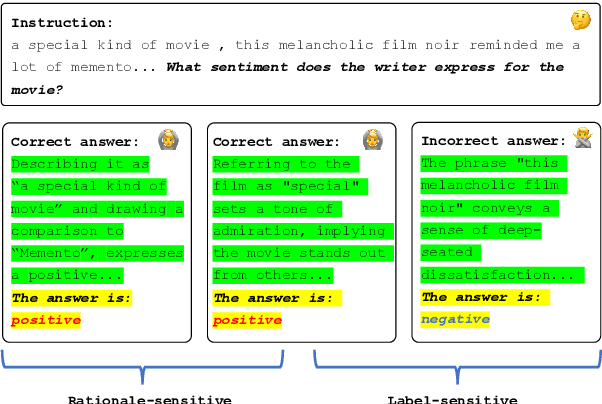



Recent strides in large language models (LLMs) have yielded remarkable performance, leveraging reinforcement learning from human feedback (RLHF) to significantly enhance generation and alignment capabilities. However, RLHF encounters numerous challenges, including the objective mismatch issue, leading to suboptimal performance in Natural Language Understanding (NLU) tasks. To address this limitation, we propose a novel Reinforcement Learning framework enhanced with Label-sensitive Reward (RLLR) to amplify the performance of LLMs in NLU tasks. By incorporating label-sensitive pairs into reinforcement learning, our method aims to adeptly capture nuanced label-sensitive semantic features during RL, thereby enhancing natural language understanding. Experiments conducted on five diverse foundation models across eight tasks showcase promising results. In comparison to Supervised Fine-tuning models (SFT), RLLR demonstrates an average performance improvement of 1.54%. Compared with RLHF models, the improvement averages at 0.69%. These results reveal the effectiveness of our method for LLMs in NLU tasks. Code and data available at: https://github.com/MagiaSN/ACL2024_RLLR.
CausalBERT: Injecting Causal Knowledge Into Pre-trained Models with Minimal Supervision
Aug 08, 2021

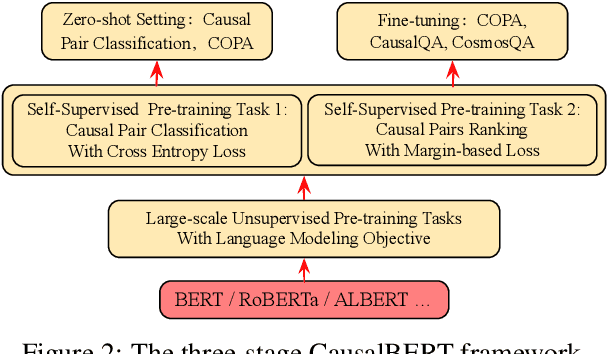

Recent work has shown success in incorporating pre-trained models like BERT to improve NLP systems. However, existing pre-trained models lack of causal knowledge which prevents today's NLP systems from thinking like humans. In this paper, we investigate the problem of injecting causal knowledge into pre-trained models. There are two fundamental problems: 1) how to collect various granularities of causal pairs from unstructured texts; 2) how to effectively inject causal knowledge into pre-trained models. To address these issues, we extend the idea of CausalBERT from previous studies, and conduct experiments on various datasets to evaluate its effectiveness. In addition, we adopt a regularization-based method to preserve the already learned knowledge with an extra regularization term while injecting causal knowledge. Extensive experiments on 7 datasets, including four causal pair classification tasks, two causal QA tasks and a causal inference task, demonstrate that CausalBERT captures rich causal knowledge and outperforms all pre-trained models-based state-of-the-art methods, achieving a new causal inference benchmark.
Event Representation Learning Enhanced with External Commonsense Knowledge
Sep 09, 2019

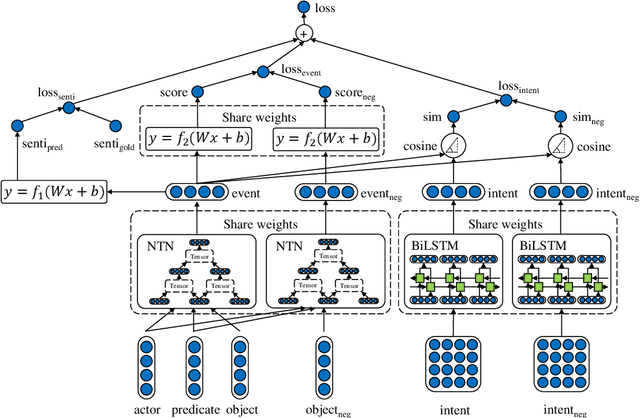

Prior work has proposed effective methods to learn event representations that can capture syntactic and semantic information over text corpus, demonstrating their effectiveness for downstream tasks such as script event prediction. On the other hand, events extracted from raw texts lacks of commonsense knowledge, such as the intents and emotions of the event participants, which are useful for distinguishing event pairs when there are only subtle differences in their surface realizations. To address this issue, this paper proposes to leverage external commonsense knowledge about the intent and sentiment of the event. Experiments on three event-related tasks, i.e., event similarity, script event prediction and stock market prediction, show that our model obtains much better event embeddings for the tasks, achieving 78% improvements on hard similarity task, yielding more precise inferences on subsequent events under given contexts, and better accuracies in predicting the volatilities of the stock market.
ELG: An Event Logic Graph
Aug 07, 2019

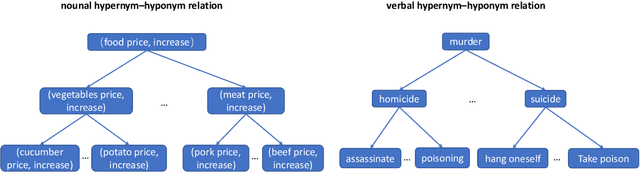

The evolution and development of events have their own basic principles, which make events happen sequentially. Therefore, the discovery of such evolutionary patterns among events are of great value for event prediction, decision-making and scenario design of dialog systems. However, conventional knowledge graph mainly focuses on the entities and their relations, which neglects the real world events. In this paper, we present a novel type of knowledge base - Event Logic Graph (ELG), which can reveal evolutionary patterns and development logics of real world events. Specifically, ELG is a directed cyclic graph, whose nodes are events, and edges stand for the sequential, causal, conditional or hypernym-hyponym (is-a) relations between events. We constructed two domain ELG: financial domain ELG, which consists of more than 1.5 million of event nodes and more than 1.8 million of directed edges, and travel domain ELG, which consists of about 30 thousand of event nodes and more than 234 thousand of directed edges. Experimental results show that ELG is effective for the task of script event prediction.