 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrengthened Symbol Binding Makes Large Language Models Reliable Multiple-Choice Selectors
Jun 03, 2024Multiple-Choice Questions (MCQs) constitute a critical area of research in the study of Large Language Models (LLMs). Previous works have investigated the selection bias problem in MCQs within few-shot scenarios, in which the LLM's performance may be influenced by the presentation of answer choices, leaving the selection bias during Supervised Fine-Tuning (SFT) unexplored. In this paper, we reveal that selection bias persists in the SFT phase , primarily due to the LLM's inadequate Multiple Choice Symbol Binding (MCSB) ability. This limitation implies that the model struggles to associate the answer options with their corresponding symbols (e.g., A/B/C/D) effectively. To enhance the model's MCSB capability, we first incorporate option contents into the loss function and subsequently adjust the weights of the option symbols and contents, guiding the model to understand the option content of the current symbol. Based on this, we introduce an efficient SFT algorithm for MCQs, termed Point-wise Intelligent Feedback (PIF). PIF constructs negative instances by randomly combining the incorrect option contents with all candidate symbols, and proposes a point-wise loss to provide feedback on these negative samples into LLMs. Our experimental results demonstrate that PIF significantly reduces the model's selection bias by improving its MCSB capability. Remarkably, PIF exhibits a substantial enhancement in the accuracy for MCQs.
* Accept at ACL2024 Main
Enhancing Reinforcement Learning with Label-Sensitive Reward for Natural Language Understanding
May 30, 2024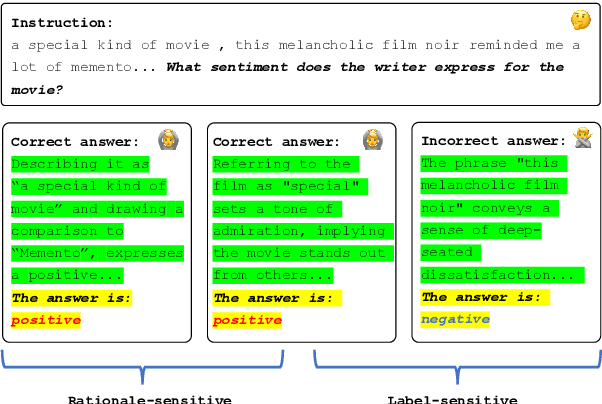



Recent strides in large language models (LLMs) have yielded remarkable performance, leveraging reinforcement learning from human feedback (RLHF) to significantly enhance generation and alignment capabilities. However, RLHF encounters numerous challenges, including the objective mismatch issue, leading to suboptimal performance in Natural Language Understanding (NLU) tasks. To address this limitation, we propose a novel Reinforcement Learning framework enhanced with Label-sensitive Reward (RLLR) to amplify the performance of LLMs in NLU tasks. By incorporating label-sensitive pairs into reinforcement learning, our method aims to adeptly capture nuanced label-sensitive semantic features during RL, thereby enhancing natural language understanding. Experiments conducted on five diverse foundation models across eight tasks showcase promising results. In comparison to Supervised Fine-tuning models (SFT), RLLR demonstrates an average performance improvement of 1.54%. Compared with RLHF models, the improvement averages at 0.69%. These results reveal the effectiveness of our method for LLMs in NLU tasks. Code and data available at: https://github.com/MagiaSN/ACL2024_RLLR.