 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyphrase Extraction with Span-based Feature Representations
Feb 13, 2020
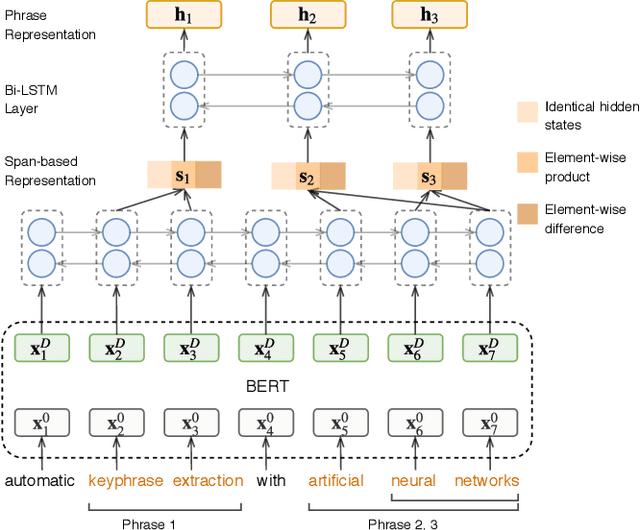

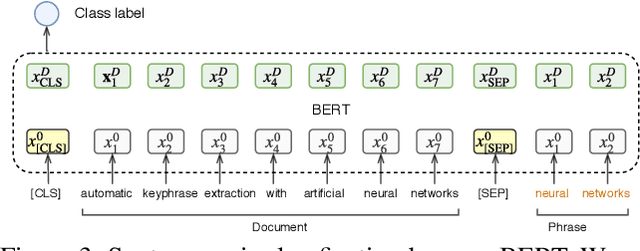
Keyphrases are capable of providing semantic metadata characterizing documents and producing an overview of the content of a document. Since keyphrase extraction is able to facilitate the management, categorization, and retrieval of information, it has received much attention in recent years. There are three approaches to address keyphrase extraction: (i) traditional two-step ranking method, (ii) sequence labeling and (iii) generation using neural networks. Two-step ranking approach is based on feature engineering, which is labor intensive and domain dependent. Sequence labeling is not able to tackle overlapping phrases. Generation methods (i.e., Sequence-to-sequence neural network models) overcome those shortcomings, so they have been widely studied and gain state-of-the-art performance. However, generation methods can not utilize context information effectively. In this paper, we propose a novelty Span Keyphrase Extraction model that extracts span-based feature representation of keyphrase directly from all the content tokens. In this way, our model obtains representation for each keyphrase and further learns to capture the interaction between keyphrases in one document to get better ranking results. In addition, with the help of tokens, our model is able to extract overlapped keyphrases. Experimental results on the benchmark datasets show that our proposed model outperforms the existing methods by a large margin.