 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Based Machine Reading Comprehension
Paper and Code
Sep 12, 2018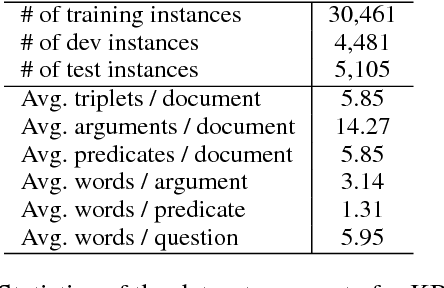
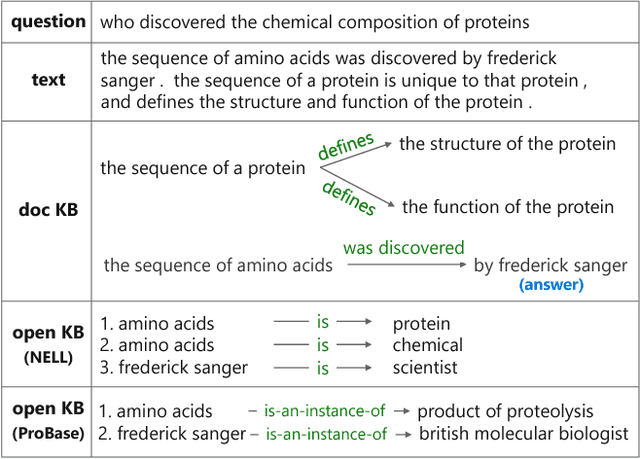
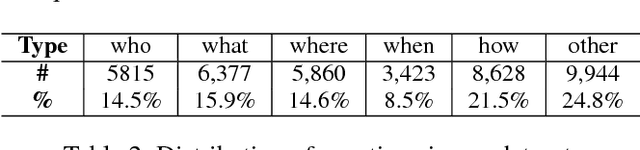
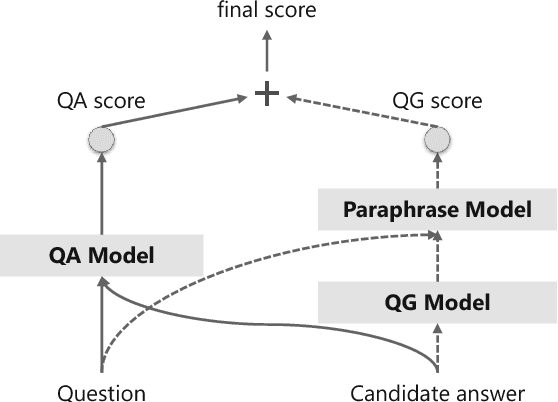
Machine reading comprehension (MRC) requires reasoning about both the knowledge involved in a document and knowledge about the world. However, existing datasets are typically dominated by questions that can be well solved by context matching, which fail to test this capability. To encourage the progress on knowledge-based reasoning in MRC, we present knowledge-based MRC in this paper, and build a new dataset consisting of 40,047 question-answer pairs. The annotation of this dataset is designed so that successfully answering the questions requires understanding and the knowledge involved in a document. We implement a framework consisting of both a question answering model and a question generation model, both of which take the knowledge extracted from the document as well as relevant facts from an external knowledge base such as Freebase/ProBase/Reverb/NELL. Results show that incorporating side information from external KB improves the accuracy of the baseline question answer system. We compare it with a standard MRC model BiDAF, and also provide the difficulty of the dataset and lay out remaining challenges.