 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAND: Semantic Anchoring Constraint with Dual-Granularity Disambiguation for Remote Sensing Image Change Captioning
Apr 25, 2026Remote sensing image change captioning (RSICC) aims to describe the difference between two remote sensing images. While recent methods have explored video modeling, they largely overlook the inherent ambiguities in viewpoint, scale, and prior knowledge, lacking effective constraints on the encoder. In this paper, we present STAND, a Semantic Anchoring Constraint with Dual-Granularity Disambiguation for RSICC, to progressively resolve these ambiguities. Specifically, to establish a reliable feature foundation, we first introduce an interpretable constraint to regularize temporal representations. Operating on these purified features, a dual-granularity disambiguation module resolves spatial uncertainties by coupling macro-level global context aggregation for viewpoint confusion with micro-level frequency-refocused attention for small-object scale enhancement. Ultimately, to translate these visually disambiguated features into precise text, a semantic concept anchoring module leverages language categorical priors to tackle knowledge ambiguity during decoding. Extensive experiments verify the superiority of STAND and its effectiveness in addressing ambiguities.
Uncertainty-boosted Robust Video Activity Anticipation
Apr 29, 2024



Video activity anticipation aims to predict what will happen in the future, embracing a broad application prospect ranging from robot vision and autonomous driving. Despite the recent progress, the data uncertainty issue, reflected as the content evolution process and dynamic correlation in event labels, has been somehow ignored. This reduces the model generalization ability and deep understanding on video content, leading to serious error accumulation and degraded performance. In this paper, we address the uncertainty learning problem and propose an uncertainty-boosted robust video activity anticipation framework, which generates uncertainty values to indicate the credibility of the anticipation results. The uncertainty value is used to derive a temperature parameter in the softmax function to modulate the predicted target activity distribution. To guarantee the distribution adjustment, we construct a reasonable target activity label representation by incorporating the activity evolution from the temporal class correlation and the semantic relationship. Moreover, we quantify the uncertainty into relative values by comparing the uncertainty among sample pairs and their temporal-lengths. This relative strategy provides a more accessible way in uncertainty modeling than quantifying the absolute uncertainty values on the whole dataset. Experiments on multiple backbones and benchmarks show our framework achieves promising performance and better robustness/interpretability. Source codes are available at https://github.com/qzhb/UbRV2A.
Bias-Conflict Sample Synthesis and Adversarial Removal Debias Strategy for Temporal Sentence Grounding in Video
Jan 19, 2024



Temporal Sentence Grounding in Video (TSGV) is troubled by dataset bias issue, which is caused by the uneven temporal distribution of the target moments for samples with similar semantic components in input videos or query texts. Existing methods resort to utilizing prior knowledge about bias to artificially break this uneven distribution, which only removes a limited amount of significant language biases. In this work, we propose the bias-conflict sample synthesis and adversarial removal debias strategy (BSSARD), which dynamically generates bias-conflict samples by explicitly leveraging potentially spurious correlations between single-modality features and the temporal position of the target moments. Through adversarial training, its bias generators continuously introduce biases and generate bias-conflict samples to deceive its grounding model. Meanwhile, the grounding model continuously eliminates the introduced biases, which requires it to model multi-modality alignment information. BSSARD will cover most kinds of coupling relationships and disrupt language and visual biases simultaneously. Extensive experiments on Charades-CD and ActivityNet-CD demonstrate the promising debiasing capability of BSSARD. Source codes are available at https://github.com/qzhb/BSSARD.
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
Nov 23, 2021
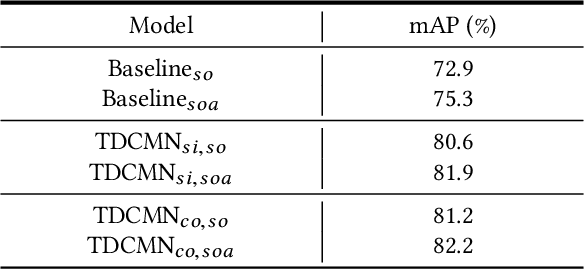
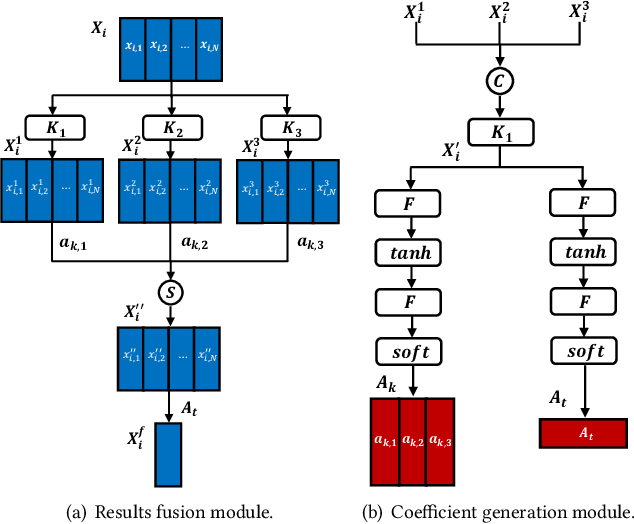
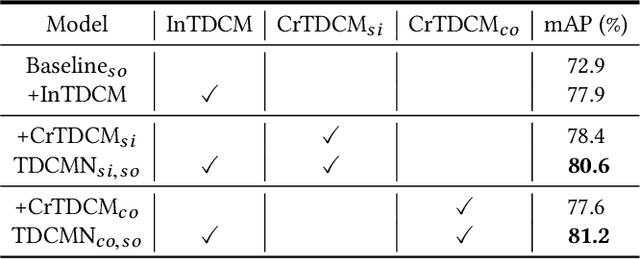
Event analysis in untrimmed videos has attracted increasing attention due to the application of cutting-edge techniques such as CNN. As a well studied property for CNN-based models, the receptive field is a measurement for measuring the spatial range covered by a single feature response, which is crucial in improving the image categorization accuracy. In video domain, video event semantics are actually described by complex interaction among different concepts, while their behaviors vary drastically from one video to another, leading to the difficulty in concept-based analytics for accurate event categorization. To model the concept behavior, we study temporal concept receptive field of concept-based event representation, which encodes the temporal occurrence pattern of different mid-level concepts. Accordingly, we introduce temporal dynamic convolution (TDC) to give stronger flexibility to concept-based event analytics. TDC can adjust the temporal concept receptive field size dynamically according to different inputs. Notably, a set of coefficients are learned to fuse the results of multiple convolutions with different kernel widths that provide various temporal concept receptive field sizes. Different coefficients can generate appropriate and accurate temporal concept receptive field size according to input videos and highlight crucial concepts. Based on TDC, we propose the temporal dynamic concept modeling network (TDCMN) to learn an accurate and complete concept representation for efficient untrimmed video analysis. Experiment results on FCVID and ActivityNet show that TDCMN demonstrates adaptive event recognition ability conditioned on different inputs, and improve the event recognition performance of Concept-based methods by a large margin. Code is available at https://github.com/qzhb/TDCMN.
Self-Regulated Learning for Egocentric Video Activity Anticipation
Nov 23, 2021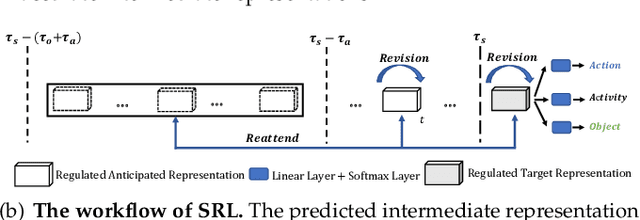
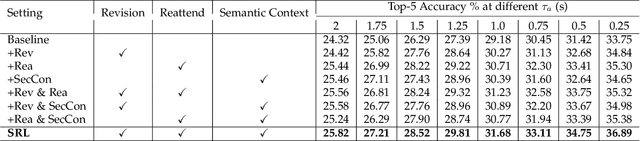
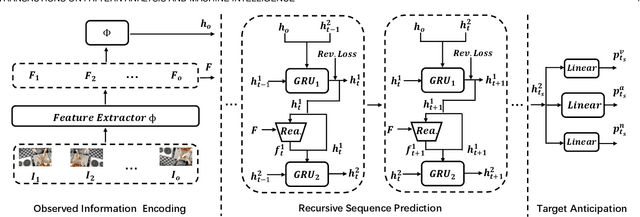
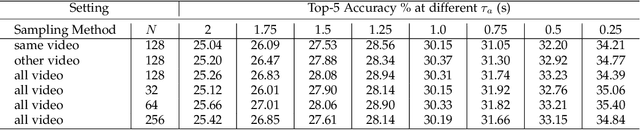
Future activity anticipation is a challenging problem in egocentric vision. As a standard future activity anticipation paradigm, recursive sequence prediction suffers from the accumulation of errors. To address this problem, we propose a simple and effective Self-Regulated Learning framework, which aims to regulate the intermediate representation consecutively to produce representation that (a) emphasizes the novel information in the frame of the current time-stamp in contrast to previously observed content, and (b) reflects its correlation with previously observed frames. The former is achieved by minimizing a contrastive loss, and the latter can be achieved by a dynamic reweighing mechanism to attend to informative frames in the observed content with a similarity comparison between feature of the current frame and observed frames. The learned final video representation can be further enhanced by multi-task learning which performs joint feature learning on the target activity labels and the automatically detected action and object class tokens. SRL sharply outperforms existing state-of-the-art in most cases on two egocentric video datasets and two third-person video datasets. Its effectiveness is also verified by the experimental fact that the action and object concepts that support the activity semantics can be accurately identified.