 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Intent to Evidence: A Categorical Approach for Structural Evaluation of Deep Research Agents
Mar 26, 2026Although deep research agents (DRAs) have emerged as a promising paradigm for complex information synthesis, their evaluation remains constrained by ad hoc empirical benchmarks. These heuristic approaches do not rigorously model agent behavior or adequately stress-test long-horizon synthesis and ambiguity resolution. To bridge this gap, we formalize DRA behavior through the lens of category theory, modeling deep research workflow as a composition of structure-preserving maps (functors). Grounded in this theoretical framework, we introduce a novel mechanism-aware benchmark with 296 questions designed to stress-test agents along four interpretable axes: traversing sequential connectivity chains, verifying intersections within V-structure pullbacks, imposing topological ordering on retrieved substructures, and performing ontological falsification via the Yoneda Probe. Our rigorous evaluation of 11 leading models establishes a persistently low baseline, with the state-of-the-art achieving only a 19.9\% average accuracy, exposing the difficulty of formal structural stress-testing. Furthermore, our findings reveal a stark dichotomy in the current AI capabilities. While advanced deep research pipelines successfully redefine dynamic topological re-ordering and exhibit robust ontological verification -- matching pure reasoning models in falsifying hallucinated premises -- they almost universally collapse on multi-hop structural synthesis. Crucially, massive performance variance across tasks exposes a lingering reliance on brittle heuristics rather than a systemic understanding. Ultimately, this work demonstrates that while top-tier autonomous agents can now organically unify search and reasoning, achieving a generalized mastery over complex structural information remains a formidable open challenge.\footnote{Our implementation will be available at https://github.com/tzq1999/CDR.
A Theoretical Lens for RL-Tuned Language Models via Energy-Based Models
Dec 21, 2025Large language models (LLMs) trained via KL-regularized reinforcement learning demonstrate strong instruction following, self-correction, and reasoning abilities. Yet their theoretical underpinnings remain limited. We exploit the closed-form energy-based model (EBM) structure of the optimal KL-regularized policy to provide a unified variational analysis of LLMs. For instruction-tuned models, under natural assumptions on reward potentials and pretraining symmetry, we prove that the transition kernel satisfies detailed balance with respect to a scalar potential encoding response quality. This yields monotonic KL convergence to a high-quality stationary distribution, bounded hitting times to superior states, and exponential mixing governed by the spectral gap. For reasoning models trained with verifiable rewards (RLVR), we show the objective is equivalent to expected KL minimization toward an optimal reasoning distribution, with the suboptimality gap reducing to the Bernoulli KL between target and current accuracies along the natural gradient flow. This helps explain empirical entropy-accuracy trade-offs.
Inference-Cost-Aware Dynamic Tree Construction for Efficient Inference in Large Language Models
Oct 30, 2025Large Language Models (LLMs) face significant inference latency challenges stemming from their autoregressive design and large size. To address this, speculative decoding emerges as a solution, enabling the simultaneous generation and validation of multiple tokens. While recent approaches like EAGLE-2 and EAGLE-3 improve speculative decoding using dynamic tree structures, they often neglect the impact of crucial system variables such as GPU devices and batch sizes. Therefore, we introduce a new dynamic tree decoding approach called CAST that takes into account inference costs, including factors such as GPU configurations and batch sizes, to dynamically refine the tree structure. Through comprehensive experimentation across six diverse tasks and utilizing six distinct LLMs, our methodology demonstrates remarkable results, achieving speeds up to 5.2 times faster than conventional decoding methods. Moreover, it generally outperforms existing state-of-the-art techniques from 5% to 20%.
Information-Theoretic Perspectives on Optimizers
Feb 28, 2025



The interplay of optimizers and architectures in neural networks is complicated and hard to understand why some optimizers work better on some specific architectures. In this paper, we find that the traditionally used sharpness metric does not fully explain the intricate interplay and introduces information-theoretic metrics called entropy gap to better help analyze. It is found that both sharpness and entropy gap affect the performance, including the optimization dynamic and generalization. We further use information-theoretic tools to understand a recently proposed optimizer called Lion and find ways to improve it.
ATLAS: Adapter-Based Multi-Modal Continual Learning with a Two-Stage Learning Strategy
Oct 14, 2024



While vision-and-language models significantly advance in many fields, the challenge of continual learning is unsolved. Parameter-efficient modules like adapters and prompts present a promising way to alleviate catastrophic forgetting. However, existing works usually learn individual adapters for each task, which may result in redundant knowledge among adapters. Moreover, they continue to use the original pre-trained model to initialize the downstream model, leading to negligible changes in the model's generalization compared to the original model. In addition, there is still a lack of research investigating the consequences of integrating a multi-modal model into the updating procedure for both uni-modal and multi-modal tasks and the subsequent impacts it has on downstream tasks. In this paper, we propose an adapter-based two-stage learning paradigm, a multi-modal continual learning scheme that consists of experience-based learning and novel knowledge expansion, which helps the model fully use experience knowledge and compensate for novel knowledge. Extensive experiments demonstrate that our method is proficient for continual learning. It expands the distribution of representation upstream while also minimizing the negative impact of forgetting previous tasks. Additionally, it enhances the generalization capability for downstream tasks. Furthermore, we incorporate both multi-modal and uni-modal tasks into upstream continual learning. We observe that learning from upstream tasks can help with downstream tasks. Our code will be available at: https://github.com/lihong2303/ATLAS.
Exploring Information-Theoretic Metrics Associated with Neural Collapse in Supervised Training
Sep 25, 2024



In this paper, we utilize information-theoretic metrics like matrix entropy and mutual information to analyze supervised learning. We explore the information content of data representations and classification head weights and their information interplay during supervised training. Experiments show that matrix entropy cannot solely describe the interaction of the information content of data representation and classification head weights but it can effectively reflect the similarity and clustering behavior of the data. Inspired by this, we propose a cross-modal alignment loss to improve the alignment between the representations of the same class from different modalities. Moreover, in order to assess the interaction of the information content of data representation and classification head weights more accurately, we utilize new metrics like matrix mutual information ratio (MIR) and matrix information entropy difference ratio (HDR). Through theory and experiment, we show that HDR and MIR can not only effectively describe the information interplay of supervised training but also improve the performance of supervised and semi-supervised learning.
Can I understand what I create? Self-Knowledge Evaluation of Large Language Models
Jun 10, 2024Large language models (LLMs) have achieved remarkable progress in linguistic tasks, necessitating robust evaluation frameworks to understand their capabilities and limitations. Inspired by Feynman's principle of understanding through creation, we introduce a self-knowledge evaluation framework that is easy to implement, evaluating models on their ability to comprehend and respond to self-generated questions. Our findings, based on testing multiple models across diverse tasks, reveal significant gaps in the model's self-knowledge ability. Further analysis indicates these gaps may be due to misalignment with human attention mechanisms. Additionally, fine-tuning on self-generated math task may enhance the model's math performance, highlighting the potential of the framework for efficient and insightful model evaluation and may also contribute to the improvement of LLMs.
Unveiling the Dynamics of Information Interplay in Supervised Learning
Jun 06, 2024In this paper, we use matrix information theory as an analytical tool to analyze the dynamics of the information interplay between data representations and classification head vectors in the supervised learning process. Specifically, inspired by the theory of Neural Collapse, we introduce matrix mutual information ratio (MIR) and matrix entropy difference ratio (HDR) to assess the interactions of data representation and class classification heads in supervised learning, and we determine the theoretical optimal values for MIR and HDR when Neural Collapse happens. Our experiments show that MIR and HDR can effectively explain many phenomena occurring in neural networks, for example, the standard supervised training dynamics, linear mode connectivity, and the performance of label smoothing and pruning. Additionally, we use MIR and HDR to gain insights into the dynamics of grokking, which is an intriguing phenomenon observed in supervised training, where the model demonstrates generalization capabilities long after it has learned to fit the training data. Furthermore, we introduce MIR and HDR as loss terms in supervised and semi-supervised learning to optimize the information interactions among samples and classification heads. The empirical results provide evidence of the method's effectiveness, demonstrating that the utilization of MIR and HDR not only aids in comprehending the dynamics throughout the training process but can also enhances the training procedure itself.
Provable Contrastive Continual Learning
May 29, 2024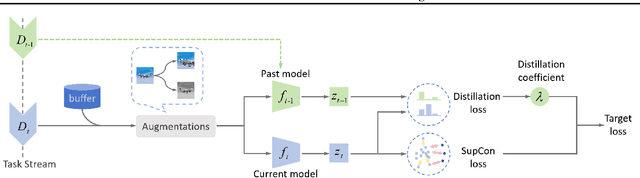


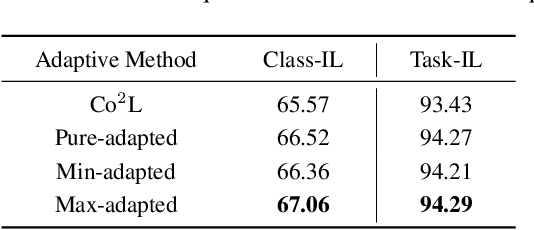
Continual learning requires learning incremental tasks with dynamic data distributions. So far, it has been observed that employing a combination of contrastive loss and distillation loss for training in continual learning yields strong performance. To the best of our knowledge, however, this contrastive continual learning framework lacks convincing theoretical explanations. In this work, we fill this gap by establishing theoretical performance guarantees, which reveal how the performance of the model is bounded by training losses of previous tasks in the contrastive continual learning framework. Our theoretical explanations further support the idea that pre-training can benefit continual learning. Inspired by our theoretical analysis of these guarantees, we propose a novel contrastive continual learning algorithm called CILA, which uses adaptive distillation coefficients for different tasks. These distillation coefficients are easily computed by the ratio between average distillation losses and average contrastive losses from previous tasks. Our method shows great improvement on standard benchmarks and achieves new state-of-the-art performance.
The Information of Large Language Model Geometry
Feb 01, 2024This paper investigates the information encoded in the embeddings of large language models (LLMs). We conduct simulations to analyze the representation entropy and discover a power law relationship with model sizes. Building upon this observation, we propose a theory based on (conditional) entropy to elucidate the scaling law phenomenon. Furthermore, we delve into the auto-regressive structure of LLMs and examine the relationship between the last token and previous context tokens using information theory and regression techniques. Specifically, we establish a theoretical connection between the information gain of new tokens and ridge regression. Additionally, we explore the effectiveness of Lasso regression in selecting meaningful tokens, which sometimes outperforms the closely related attention weights. Finally, we conduct controlled experiments, and find that information is distributed across tokens, rather than being concentrated in specific "meaningful" tokens alone.