 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSP-TransientBench: A Real-Captured Single Photon Perception Benchmark
Jun 16, 2026Single-photon LiDAR (SPL) based on single-photon avalanche diode (SPAD) sensing enables time-resolved photon measurements with extreme sensitivity, offering unique potential for active 3D perception in photon-starved scenarios.However, real-world single photon perception remains fundamentally challenging due to unique measurement noise and complex multi-return transient phenomena, which jointly complicate geometric reconstruction and semantic scene understanding. Despite growing interest in SPAD-based sensing, existing studies are largely limited to simulated data or small-scale controlled captures. As a result, systematic evaluation of real-world single photon perception across depth estimation, multi-view reconstruction, and 3D semantic understanding remains underexplored. To bridge this gap, we introduce SP-TransientBench (STB), a real-captured multi-task benchmark for single photon perception. SP-TransientBenc comprises 10 diverse scenes and 10,297 views captured using a solid-state single-photon LiDAR at $256\times192$ resolution. Each view provides full time-of-flight histograms with multi-return behavior,standardized metadata, and calibrated camera poses for multi-view evaluation. We further provide 13-class 3D semantic annotations for selected scenes. By providing dedicated data splits and evaluation protocols for each task, STB enables consistent and reproducible benchmarking of real-world single photon perception across multiple 3D vision problems. The dataset and code will be released upon acceptance.
Label-efficient Single Photon Images Classification via Active Learning
May 07, 2025Single-photon LiDAR achieves high-precision 3D imaging in extreme environments through quantum-level photon detection technology. Current research primarily focuses on reconstructing 3D scenes from sparse photon events, whereas the semantic interpretation of single-photon images remains underexplored, due to high annotation costs and inefficient labeling strategies. This paper presents the first active learning framework for single-photon image classification. The core contribution is an imaging condition-aware sampling strategy that integrates synthetic augmentation to model variability across imaging conditions. By identifying samples where the model is both uncertain and sensitive to these conditions, the proposed method selectively annotates only the most informative examples. Experiments on both synthetic and real-world datasets show that our approach outperforms all baselines and achieves high classification accuracy with significantly fewer labeled samples. Specifically, our approach achieves 97% accuracy on synthetic single-photon data using only 1.5% labeled samples. On real-world data, we maintain 90.63% accuracy with just 8% labeled samples, which is 4.51% higher than the best-performing baseline. This illustrates that active learning enables the same level of classification performance on single-photon images as on classical images, opening doors to large-scale integration of single-photon data in real-world applications.
Feature Alignment: Rethinking Efficient Active Learning via Proxy in the Context of Pre-trained Models
Mar 02, 2024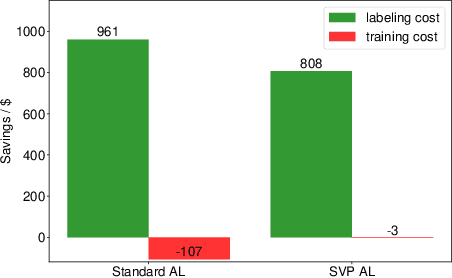
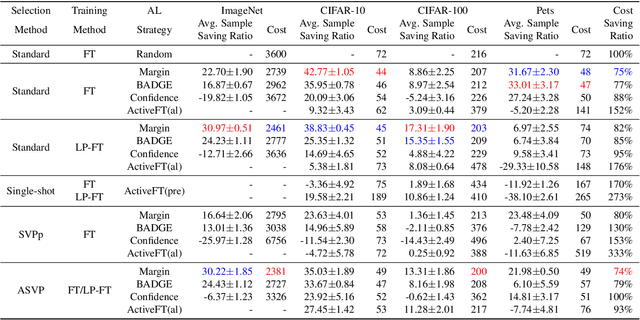
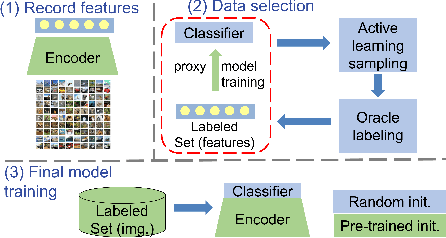
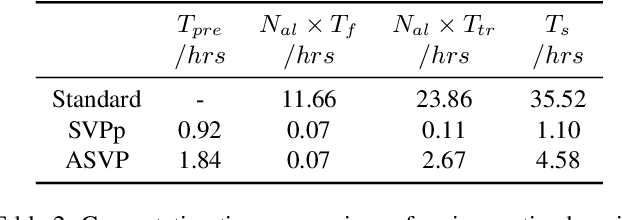
Fine-tuning the pre-trained model with active learning holds promise for reducing annotation costs. However, this combination introduces significant computational costs, particularly with the growing scale of pre-trained models. Recent research has proposed proxy-based active learning, which pre-computes features to reduce computational costs. Yet, this approach often incurs a significant loss in active learning performance, which may even outweigh the computational cost savings. In this paper, we argue the performance drop stems not only from pre-computed features' inability to distinguish between categories of labeled samples, resulting in the selection of redundant samples but also from the tendency to compromise valuable pre-trained information when fine-tuning with samples selected through the proxy model. To address this issue, we propose a novel method called aligned selection via proxy to update pre-computed features while selecting a proper training method to inherit valuable pre-training information. Extensive experiments validate that our method significantly improves the total cost of efficient active learning while maintaining computational efficiency.
NTKCPL: Active Learning on Top of Self-Supervised Model by Estimating True Coverage
Jun 07, 2023
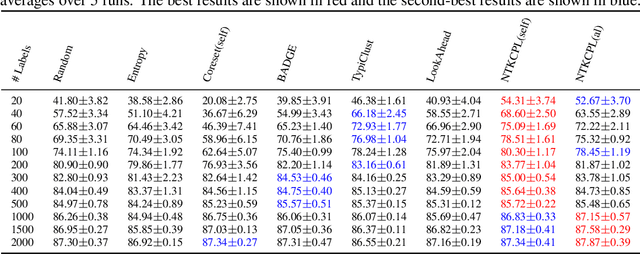
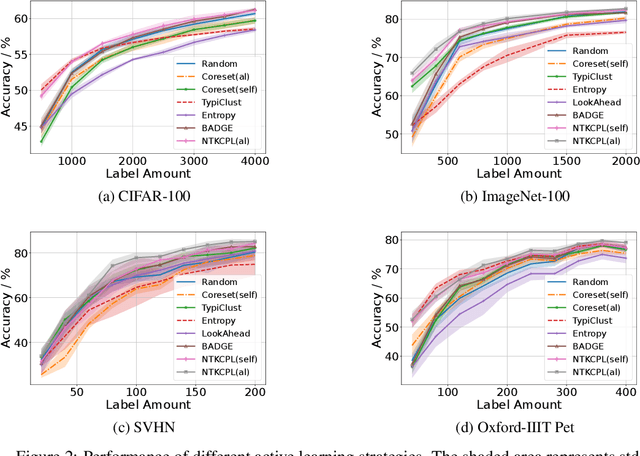
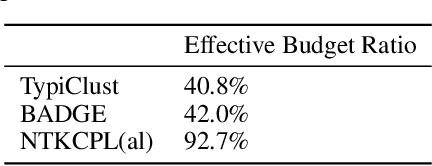
High annotation cost for training machine learning classifiers has driven extensive research in active learning and self-supervised learning. Recent research has shown that in the context of supervised learning different active learning strategies need to be applied at various stages of the training process to ensure improved performance over the random baseline. We refer to the point where the number of available annotations changes the suitable active learning strategy as the phase transition point. In this paper, we establish that when combining active learning with self-supervised models to achieve improved performance, the phase transition point occurs earlier. It becomes challenging to determine which strategy should be used for previously unseen datasets. We argue that existing active learning algorithms are heavily influenced by the phase transition because the empirical risk over the entire active learning pool estimated by these algorithms is inaccurate and influenced by the number of labeled samples. To address this issue, we propose a novel active learning strategy, neural tangent kernel clustering-pseudo-labels (NTKCPL). It estimates empirical risk based on pseudo-labels and the model prediction with NTK approximation. We analyze the factors affecting this approximation error and design a pseudo-label clustering generation method to reduce the approximation error. We validate our method on five datasets, empirically demonstrating that it outperforms the baseline methods in most cases and is valid over a wider range of training budgets.
Active Self-Semi-Supervised Learning for Few Labeled Samples Fast Training
Mar 09, 2022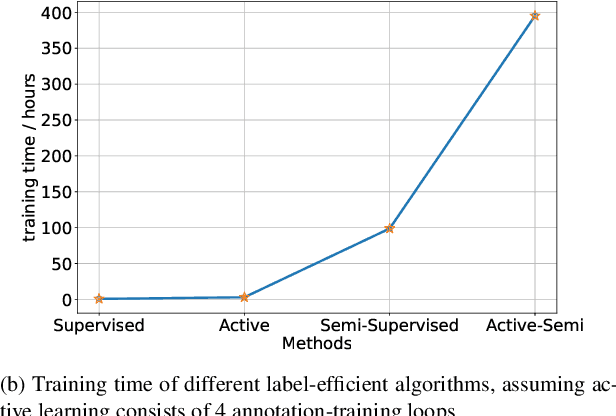
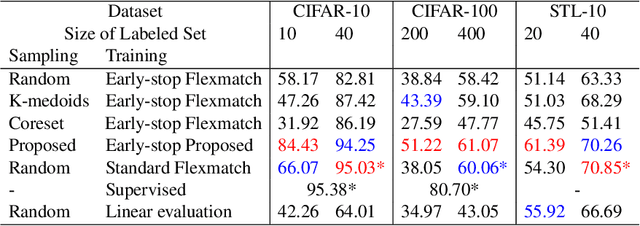


Faster training and fewer annotations are two key issues for applying deep models to various practical domains. Now, semi-supervised learning has achieved great success in training with few annotations. However, low-quality labeled samples produced by random sampling make it difficult to continue to reduce the number of annotations. In this paper we propose an active self-semi-supervised training framework that bootstraps semi-supervised models with good prior pseudo-labels, where the priors are obtained by label propagation over self-supervised features. Because the accuracy of the prior is not only affected by the quality of features, but also by the selection of the labeled samples. We develop active learning and label propagation strategies to obtain better prior pseudo-labels. Consequently, our framework can greatly improve the performance of models with few annotations and greatly reduce the training time. Experiments on three semi-supervised learning benchmarks demonstrate effectiveness. Our method achieves similar accuracy to standard semi-supervised approaches in about 1/3 of the training time, and even outperform them when fewer annotations are available (84.10\% in CIFAR-10 with 10 labels).