 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Endangered Marine Species in Autonomous Underwater Vehicle Imagery Using Point Annotations and Few-Shot Learning
Jun 04, 2024
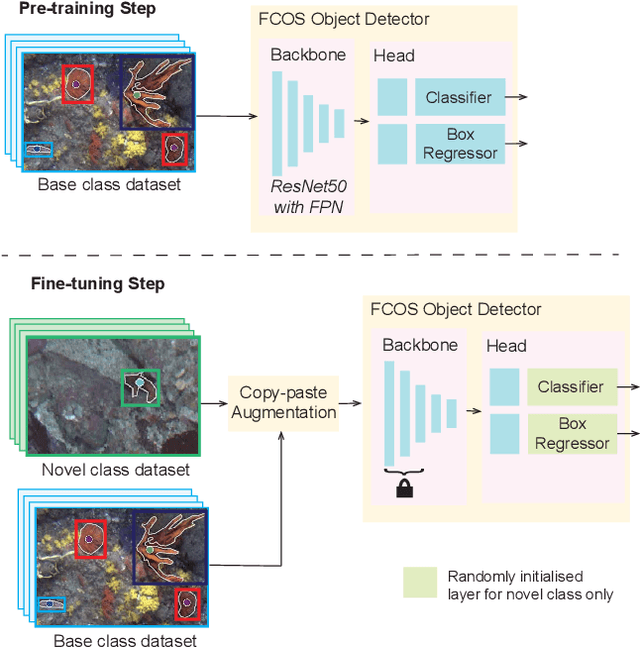


One use of Autonomous Underwater Vehicles (AUVs) is the monitoring of habitats associated with threatened, endangered and protected marine species, such as the handfish of Tasmania, Australia. Seafloor imagery collected by AUVs can be used to identify individuals within their broader habitat context, but the sheer volume of imagery collected can overwhelm efforts to locate rare or cryptic individuals. Machine learning models can be used to identify the presence of a particular species in images using a trained object detector, but the lack of training examples reduces detection performance, particularly for rare species that may only have a small number of examples in the wild. In this paper, inspired by recent work in few-shot learning, images and annotations of common marine species are exploited to enhance the ability of the detector to identify rare and cryptic species. Annotated images of six common marine species are used in two ways. Firstly, the common species are used in a pre-training step to allow the backbone to create rich features for marine species. Secondly, a copy-paste operation is used with the common species images to augment the training data. While annotations for more common marine species are available in public datasets, they are often in point format, which is unsuitable for training an object detector. A popular semantic segmentation model efficiently generates bounding box annotations for training from the available point annotations. Our proposed framework is applied to AUV images of handfish, increasing average precision by up to 48\% compared to baseline object detection training. This approach can be applied to other objects with low numbers of annotations and promises to increase the ability to actively monitor threatened, endangered and protected species.
Feature Alignment: Rethinking Efficient Active Learning via Proxy in the Context of Pre-trained Models
Mar 02, 2024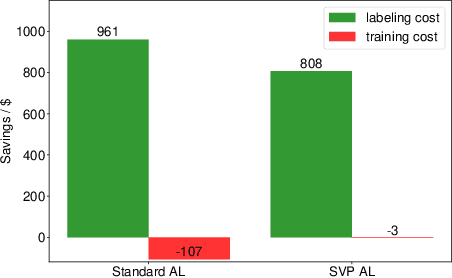
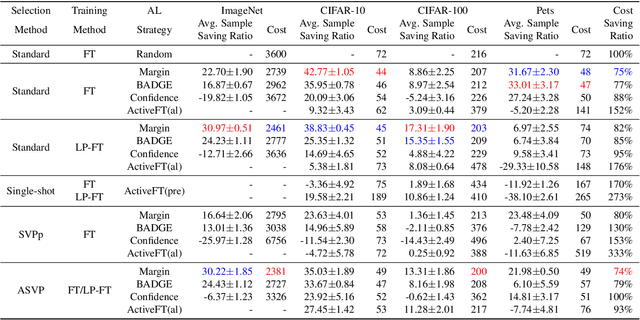
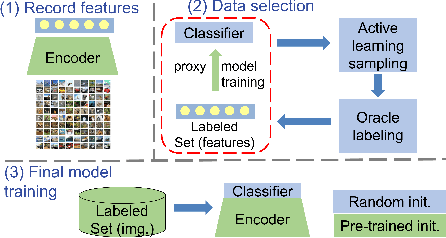
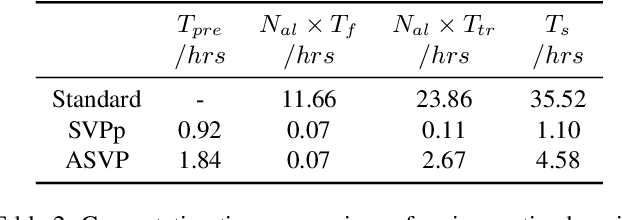
Fine-tuning the pre-trained model with active learning holds promise for reducing annotation costs. However, this combination introduces significant computational costs, particularly with the growing scale of pre-trained models. Recent research has proposed proxy-based active learning, which pre-computes features to reduce computational costs. Yet, this approach often incurs a significant loss in active learning performance, which may even outweigh the computational cost savings. In this paper, we argue the performance drop stems not only from pre-computed features' inability to distinguish between categories of labeled samples, resulting in the selection of redundant samples but also from the tendency to compromise valuable pre-trained information when fine-tuning with samples selected through the proxy model. To address this issue, we propose a novel method called aligned selection via proxy to update pre-computed features while selecting a proper training method to inherit valuable pre-training information. Extensive experiments validate that our method significantly improves the total cost of efficient active learning while maintaining computational efficiency.
Metrically Scaled Monocular Depth Estimation through Sparse Priors for Underwater Robots
Oct 25, 2023



In this work, we address the problem of real-time dense depth estimation from monocular images for mobile underwater vehicles. We formulate a deep learning model that fuses sparse depth measurements from triangulated features to improve the depth predictions and solve the problem of scale ambiguity. To allow prior inputs of arbitrary sparsity, we apply a dense parameterization method. Our model extends recent state-of-the-art approaches to monocular image based depth estimation, using an efficient encoder-decoder backbone and modern lightweight transformer optimization stage to encode global context. The network is trained in a supervised fashion on the forward-looking underwater dataset, FLSea. Evaluation results on this dataset demonstrate significant improvement in depth prediction accuracy by the fusion of the sparse feature priors. In addition, without any retraining, our method achieves similar depth prediction accuracy on a downward looking dataset we collected with a diver operated camera rig, conducting a survey of a coral reef. The method achieves real-time performance, running at 160 FPS on a laptop GPU and 7 FPS on a single CPU core and is suitable for direct deployment on embedded systems. The implementation of this work is made publicly available at https://github.com/ebnerluca/uw_depth.
NTKCPL: Active Learning on Top of Self-Supervised Model by Estimating True Coverage
Jun 07, 2023
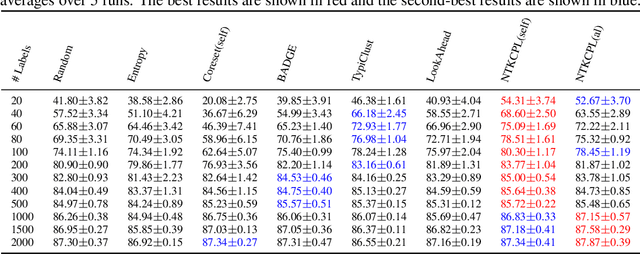
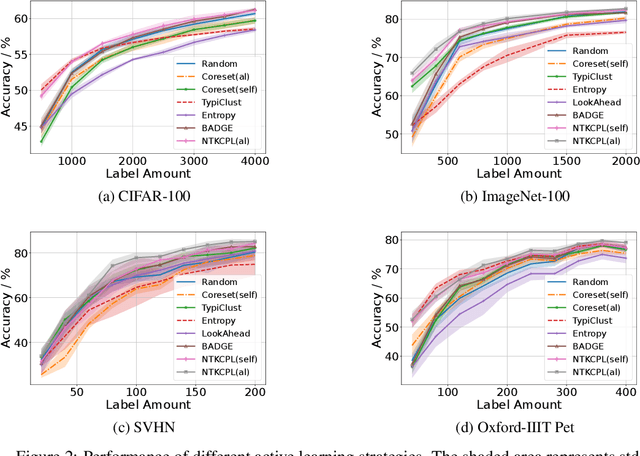
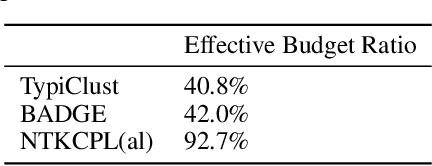
High annotation cost for training machine learning classifiers has driven extensive research in active learning and self-supervised learning. Recent research has shown that in the context of supervised learning different active learning strategies need to be applied at various stages of the training process to ensure improved performance over the random baseline. We refer to the point where the number of available annotations changes the suitable active learning strategy as the phase transition point. In this paper, we establish that when combining active learning with self-supervised models to achieve improved performance, the phase transition point occurs earlier. It becomes challenging to determine which strategy should be used for previously unseen datasets. We argue that existing active learning algorithms are heavily influenced by the phase transition because the empirical risk over the entire active learning pool estimated by these algorithms is inaccurate and influenced by the number of labeled samples. To address this issue, we propose a novel active learning strategy, neural tangent kernel clustering-pseudo-labels (NTKCPL). It estimates empirical risk based on pseudo-labels and the model prediction with NTK approximation. We analyze the factors affecting this approximation error and design a pseudo-label clustering generation method to reduce the approximation error. We validate our method on five datasets, empirically demonstrating that it outperforms the baseline methods in most cases and is valid over a wider range of training budgets.
Contactless hand tremor amplitude measurement using smartphones: development and pilot evaluation
Apr 28, 2023
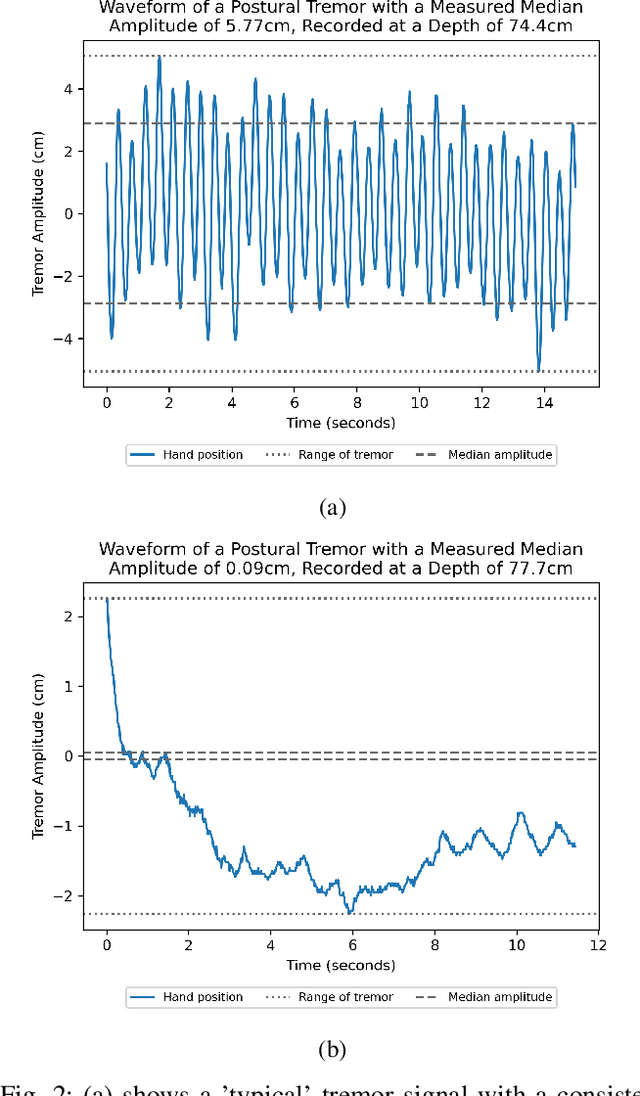

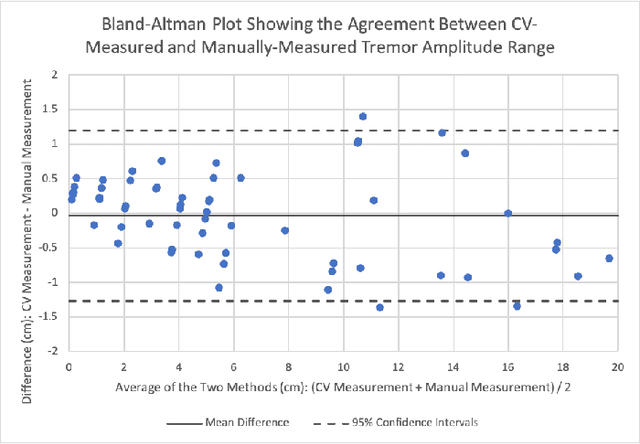
Background: Physiological tremor is defined as an involuntary and rhythmic shaking. Tremor of the hand is a key symptom of multiple neurological diseases, and its frequency and amplitude differs according to both disease type and disease progression. In routine clinical practice, tremor frequency and amplitude are assessed by expert rating using a 0 to 4 integer scale. Such ratings are subjective and have poor inter-rater reliability. There is thus a clinical need for a practical and accurate method for objectively assessing hand tremor. Objective: to develop a proof of principle method to measure hand tremor amplitude from smartphone videos. Methods: We created a computer vision pipeline that automatically extracts salient points on the hand and produces a 1-D time series of movement due to tremor, in pixels. Using the smartphones' depth measurement, we convert this measure into real distance units. We assessed the accuracy of the method using 60 videos of simulated tremor of different amplitudes from two healthy adults. Videos were taken at distances of 50, 75 and 100 cm between hand and camera. The participants had skin tone II and VI on the Fitzpatrick scale. We compared our method to a gold-standard measurement from a slide rule. Bland-Altman methods agreement analysis indicated a bias of 0.04 cm and 95% limits of agreement from -1.27 to 1.20 cm. Furthermore, we qualitatively observed that the method was robust to differences in skin tone and limited occlusion, such as a band-aid affixed to the participant's hand. Clinical relevance: We have demonstrated how tremor amplitude can be measured from smartphone videos. In conjunction with tremor frequency, this approach could be used to help diagnose and monitor neurological diseases
Active Self-Semi-Supervised Learning for Few Labeled Samples Fast Training
Mar 09, 2022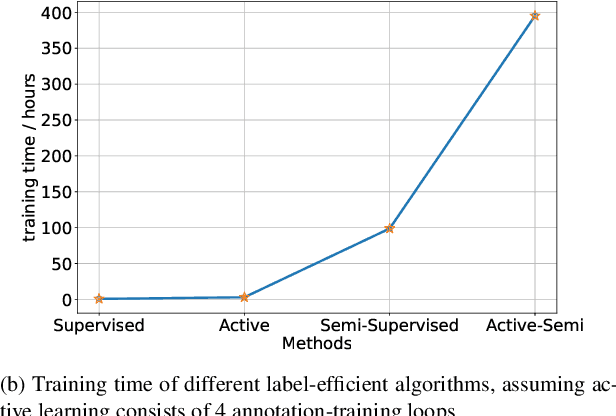
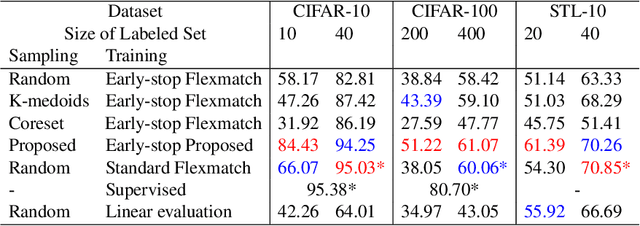


Faster training and fewer annotations are two key issues for applying deep models to various practical domains. Now, semi-supervised learning has achieved great success in training with few annotations. However, low-quality labeled samples produced by random sampling make it difficult to continue to reduce the number of annotations. In this paper we propose an active self-semi-supervised training framework that bootstraps semi-supervised models with good prior pseudo-labels, where the priors are obtained by label propagation over self-supervised features. Because the accuracy of the prior is not only affected by the quality of features, but also by the selection of the labeled samples. We develop active learning and label propagation strategies to obtain better prior pseudo-labels. Consequently, our framework can greatly improve the performance of models with few annotations and greatly reduce the training time. Experiments on three semi-supervised learning benchmarks demonstrate effectiveness. Our method achieves similar accuracy to standard semi-supervised approaches in about 1/3 of the training time, and even outperform them when fewer annotations are available (84.10\% in CIFAR-10 with 10 labels).
Analysis of an adaptive lead weighted ResNet for multiclass classification of 12-lead ECGs
Dec 01, 2021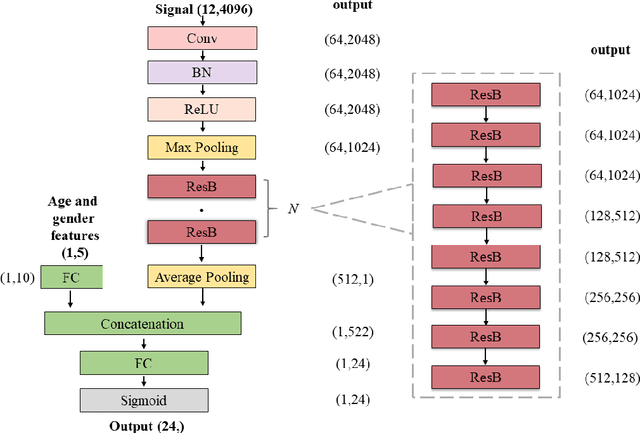

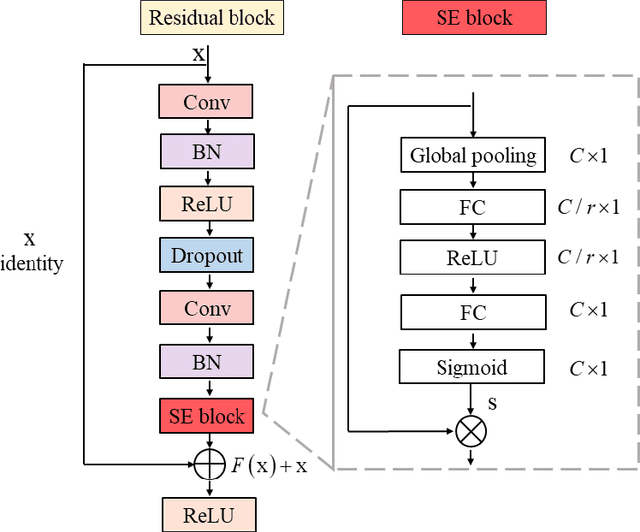
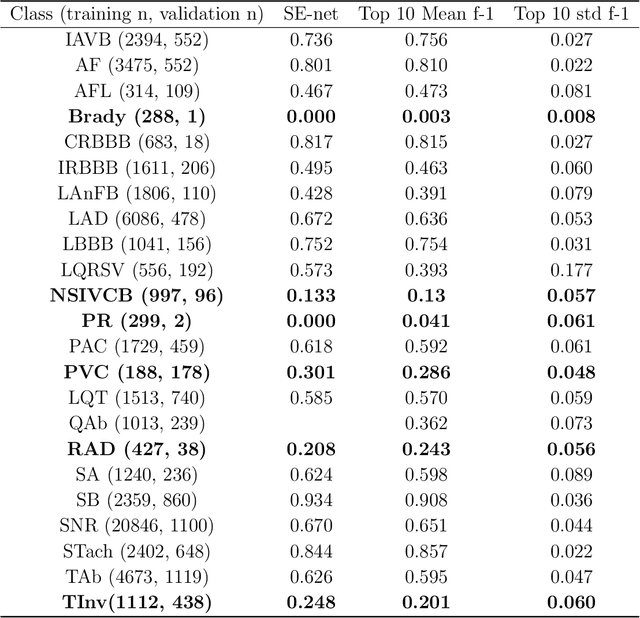
Background: Twelve lead ECGs are a core diagnostic tool for cardiovascular diseases. Here, we describe and analyse an ensemble deep neural network architecture to classify 24 cardiac abnormalities from 12-lead ECGs. Method: We proposed a squeeze and excite ResNet to automatically learn deep features from 12-lead ECGs, in order to identify 24 cardiac conditions. The deep features were augmented with age and gender features in the final fully connected layers. Output thresholds for each class were set using a constrained grid search. To determine why the model made incorrect predictions, two expert clinicians independently interpreted a random set of 100 misclassified ECGs concerning Left Axis Deviation. Results: Using the bespoke weighted accuracy metric, we achieved a 5-fold cross validation score of 0.684, and sensitivity and specificity of 0.758 and 0.969, respectively. We scored 0.520 on the full test data, and ranked 2nd out of 41 in the official challenge rankings. On a random set of misclassified ECGs, agreement between two clinicians and training labels was poor (clinician 1: kappa = -0.057, clinician 2: kappa = -0.159). In contrast, agreement between the clinicians was very high (kappa = 0.92). Discussion: The proposed prediction model performed well on the validation and hidden test data in comparison to models trained on the same data. We also discovered considerable inconsistency in training labels, which is likely to hinder development of more accurate models.