 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Endangered Marine Species in Autonomous Underwater Vehicle Imagery Using Point Annotations and Few-Shot Learning
Jun 04, 2024
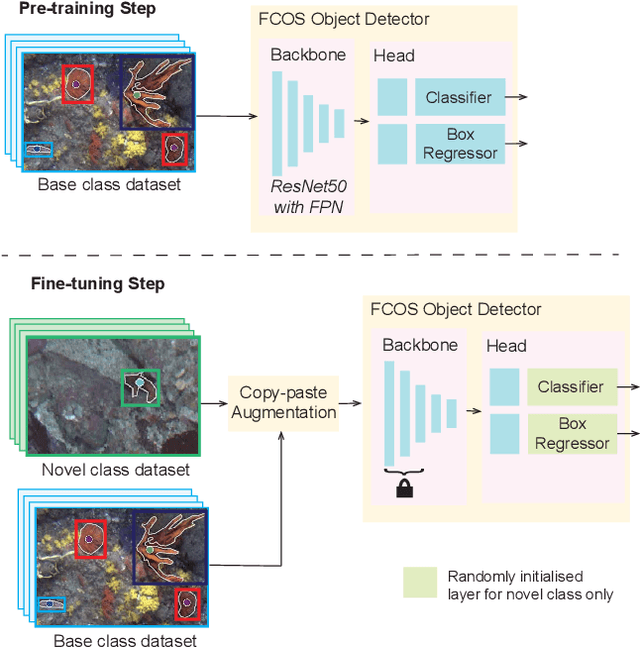


One use of Autonomous Underwater Vehicles (AUVs) is the monitoring of habitats associated with threatened, endangered and protected marine species, such as the handfish of Tasmania, Australia. Seafloor imagery collected by AUVs can be used to identify individuals within their broader habitat context, but the sheer volume of imagery collected can overwhelm efforts to locate rare or cryptic individuals. Machine learning models can be used to identify the presence of a particular species in images using a trained object detector, but the lack of training examples reduces detection performance, particularly for rare species that may only have a small number of examples in the wild. In this paper, inspired by recent work in few-shot learning, images and annotations of common marine species are exploited to enhance the ability of the detector to identify rare and cryptic species. Annotated images of six common marine species are used in two ways. Firstly, the common species are used in a pre-training step to allow the backbone to create rich features for marine species. Secondly, a copy-paste operation is used with the common species images to augment the training data. While annotations for more common marine species are available in public datasets, they are often in point format, which is unsuitable for training an object detector. A popular semantic segmentation model efficiently generates bounding box annotations for training from the available point annotations. Our proposed framework is applied to AUV images of handfish, increasing average precision by up to 48\% compared to baseline object detection training. This approach can be applied to other objects with low numbers of annotations and promises to increase the ability to actively monitor threatened, endangered and protected species.
BenthicNet: A global compilation of seafloor images for deep learning applications
May 08, 2024Advances in underwater imaging enable the collection of extensive seafloor image datasets that are necessary for monitoring important benthic ecosystems. The ability to collect seafloor imagery has outpaced our capacity to analyze it, hindering expedient mobilization of this crucial environmental information. Recent machine learning approaches provide opportunities to increase the efficiency with which seafloor image datasets are analyzed, yet large and consistent datasets necessary to support development of such approaches are scarce. Here we present BenthicNet: a global compilation of seafloor imagery designed to support the training and evaluation of large-scale image recognition models. An initial set of over 11.4 million images was collected and curated to represent a diversity of seafloor environments using a representative subset of 1.3 million images. These are accompanied by 2.6 million annotations translated to the CATAMI scheme, which span 190,000 of the images. A large deep learning model was trained on this compilation and preliminary results suggest it has utility for automating large and small-scale image analysis tasks. The compilation and model are made openly available for use by the scientific community at https://doi.org/10.20383/103.0614.