 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction-Based Anomaly Localization via Knowledge-Informed Self-Training
Feb 22, 2024



Anomaly localization, which involves localizing anomalous regions within images, is a significant industrial task. Reconstruction-based methods are widely adopted for anomaly localization because of their low complexity and high interpretability. Most existing reconstruction-based methods only use normal samples to construct model. If anomalous samples are appropriately utilized in the process of anomaly localization, the localization performance can be improved. However, usually only weakly labeled anomalous samples are available, which limits the improvement. In many cases, we can obtain some knowledge of anomalies summarized by domain experts. Taking advantage of such knowledge can help us better utilize the anomalous samples and thus further improve the localization performance. In this paper, we propose a novel reconstruction-based method named knowledge-informed self-training (KIST) which integrates knowledge into reconstruction model through self-training. Specifically, KIST utilizes weakly labeled anomalous samples in addition to the normal ones and exploits knowledge to yield pixel-level pseudo-labels of the anomalous samples. Based on the pseudo labels, a novel loss which promotes the reconstruction of normal pixels while suppressing the reconstruction of anomalous pixels is used. We conduct experiments on different datasets and demonstrate the advantages of KIST over the existing reconstruction-based methods.
Low-Multi-Rank High-Order Bayesian Robust Tensor Factorization
Nov 10, 2023The recently proposed tensor robust principal component analysis (TRPCA) methods based on tensor singular value decomposition (t-SVD) have achieved numerous successes in many fields. However, most of these methods are only applicable to third-order tensors, whereas the data obtained in practice are often of higher order, such as fourth-order color videos, fourth-order hyperspectral videos, and fifth-order light-field images. Additionally, in the t-SVD framework, the multi-rank of a tensor can describe more fine-grained low-rank structure in the tensor compared with the tubal rank. However, determining the multi-rank of a tensor is a much more difficult problem than determining the tubal rank. Moreover, most of the existing TRPCA methods do not explicitly model the noises except the sparse noise, which may compromise the accuracy of estimating the low-rank tensor. In this work, we propose a novel high-order TRPCA method, named as Low-Multi-rank High-order Bayesian Robust Tensor Factorization (LMH-BRTF), within the Bayesian framework. Specifically, we decompose the observed corrupted tensor into three parts, i.e., the low-rank component, the sparse component, and the noise component. By constructing a low-rank model for the low-rank component based on the order-$d$ t-SVD and introducing a proper prior for the model, LMH-BRTF can automatically determine the tensor multi-rank. Meanwhile, benefiting from the explicit modeling of both the sparse and noise components, the proposed method can leverage information from the noises more effectivly, leading to an improved performance of TRPCA. Then, an efficient variational inference algorithm is established for parameters estimation. Empirical studies on synthetic and real-world datasets demonstrate the effectiveness of the proposed method in terms of both qualitative and quantitative results.
On the Connection of Generative Models and Discriminative Models for Anomaly Detection
Nov 16, 2022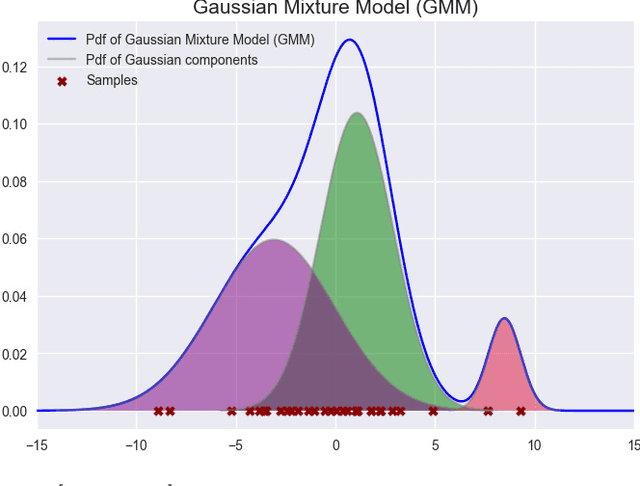
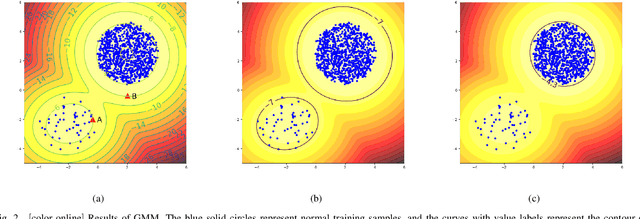
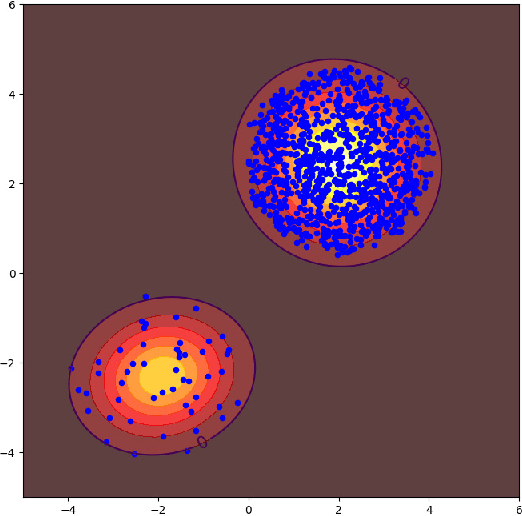
Anomaly detection (AD) has attracted considerable attention in both academia and industry. Due to the lack of anomalous data in many practical cases, AD is usually solved by first modeling the normal data pattern and then determining if data fit this model. Generative models (GMs) seem a natural tool to achieve this purpose, which learn the normal data distribution and estimate it using a probability density function (PDF). However, some works have observed the ideal performance of such GM-based AD methods. In this paper, we propose a new perspective on the ideal performance of GM-based AD methods. We state that in these methods, the implicit assumption that connects GMs'results to AD's goal is usually implausible due to normal data's multi-peaked distribution characteristic, which is quite common in practical cases. We first qualitatively formulate this perspective, and then focus on the Gaussian mixture model (GMM) to intuitively illustrate the perspective, which is a typical GM and has the natural property to approximate multi-peaked distributions. Based on the proposed perspective, in order to bypass the implicit assumption in the GMM-based AD method, we suggest integrating the Discriminative idea to orient GMM to AD tasks (DiGMM). With DiGMM, we establish a connection of generative and discriminative models, which are two key paradigms for AD and are usually treated separately before. This connection provides a possible direction for future works to jointly consider the two paradigms and incorporate their complementary characteristics for AD.
A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection
Mar 05, 2022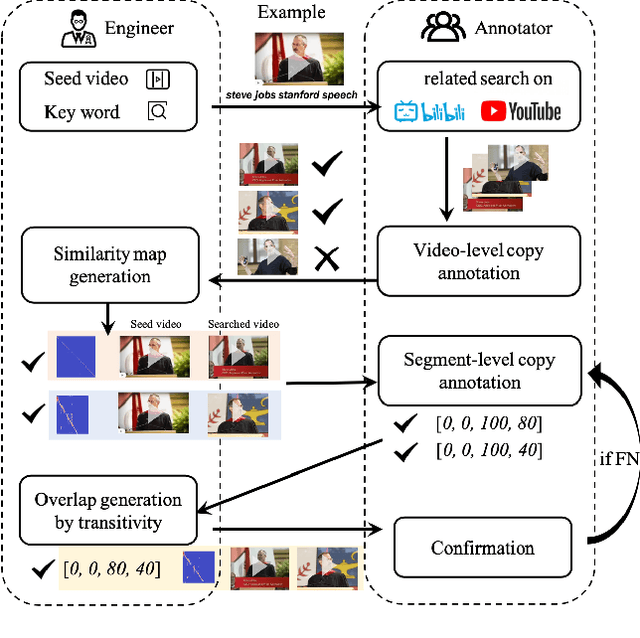
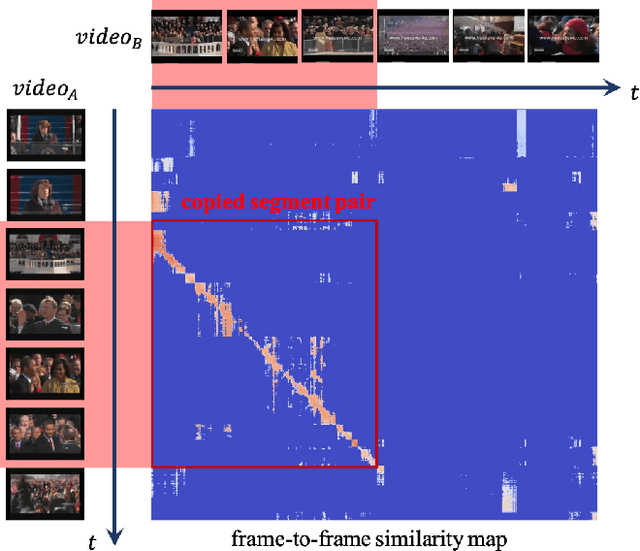
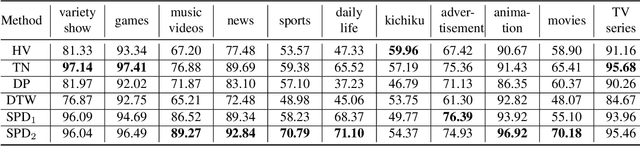
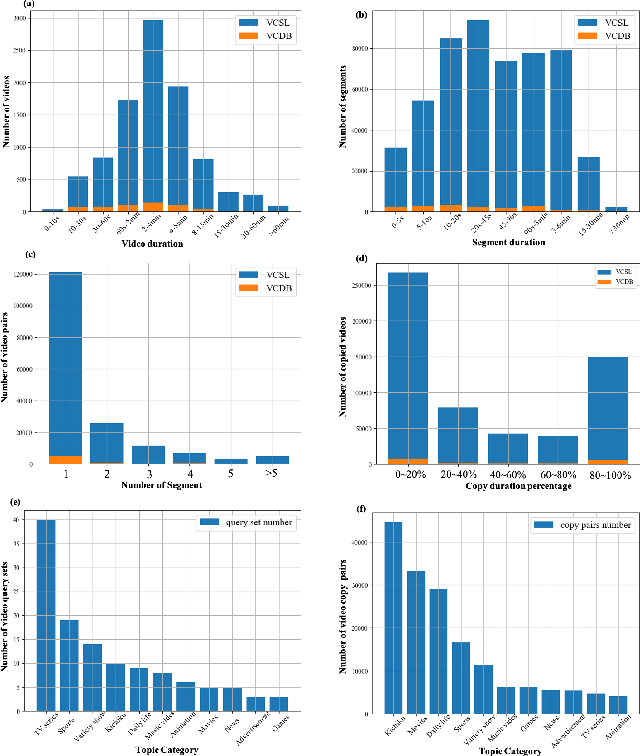
In this paper, we introduce VCSL (Video Copy Segment Localization), a new comprehensive segment-level annotated video copy dataset. Compared with existing copy detection datasets restricted by either video-level annotation or small-scale, VCSL not only has two orders of magnitude more segment-level labelled data, with 160k realistic video copy pairs containing more than 280k localized copied segment pairs, but also covers a variety of video categories and a wide range of video duration. All the copied segments inside each collected video pair are manually extracted and accompanied by precisely annotated starting and ending timestamps. Alongside the dataset, we also propose a novel evaluation protocol that better measures the prediction accuracy of copy overlapping segments between a video pair and shows improved adaptability in different scenarios. By benchmarking several baseline and state-of-the-art segment-level video copy detection methods with the proposed dataset and evaluation metric, we provide a comprehensive analysis that uncovers the strengths and weaknesses of current approaches, hoping to open up promising directions for future works. The VCSL dataset, metric and benchmark codes are all publicly available at https://github.com/alipay/VCSL.
PCNet: A Structure Similarity Enhancement Method for Multispectral and Multimodal Image Registration
Jun 09, 2021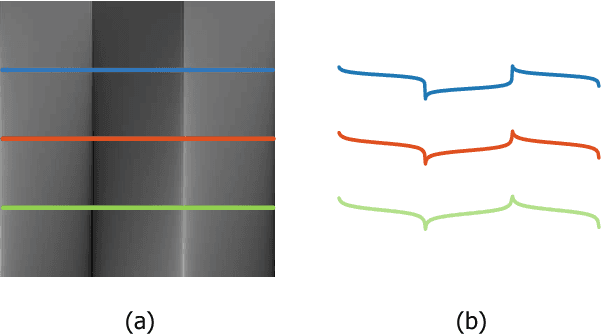
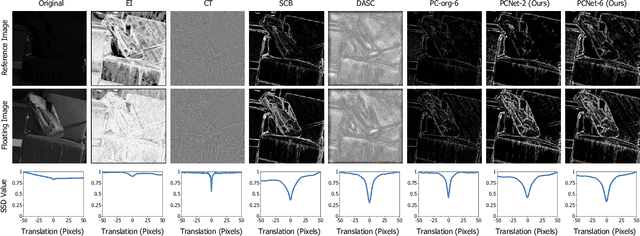


Multispectral and multimodal image processing is important in the community of computer vision and computational photography. As the acquired multispectral and multimodal data are generally misaligned due to the alternation or movement of the image device, the image registration procedure is necessary. The registration of multispectral or multimodal image is challenging due to the non-linear intensity and gradient variation. To cope with this challenge, we propose the phase congruency network (PCNet), which is able to enhance the structure similarity and alleviate the non-linear intensity and gradient variation. The images can then be aligned using the similarity enhanced features produced by the network. PCNet is constructed under the guidance of the phase congruency prior. The network contains three trainable layers accompany with the modified learnable Gabor kernels according to the phase congruency theory. Thanks to the prior knowledge, PCNet is extremely light-weight and can be trained on quite a small amount of multispectral data. PCNet can be viewed to be fully convolutional and hence can take input of arbitrary sizes. Once trained, PCNet is applicable on a variety of multispectral and multimodal data such as RGB/NIR and flash/no-flash images without additional further tuning. Experimental results validate that PCNet outperforms current state-of-the-art registration algorithms, including the deep-learning based ones that have the number of parameters hundreds times compared to PCNet. Thanks to the similarity enhancement training, PCNet outperforms the original phase congruency algorithm with two-thirds less feature channels.
Distributed Variational Bayesian Algorithms Over Sensor Networks
Nov 27, 2020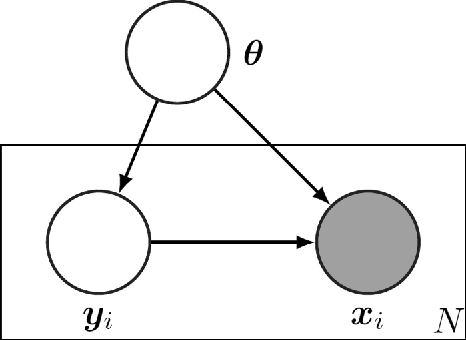
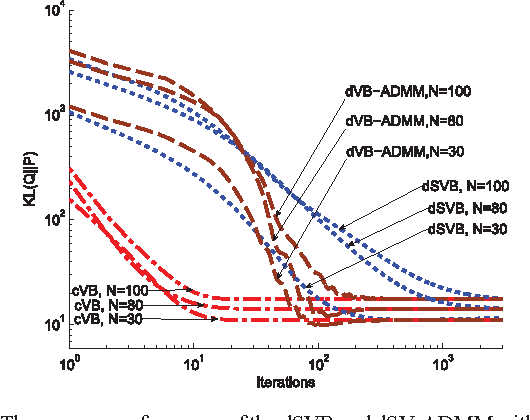
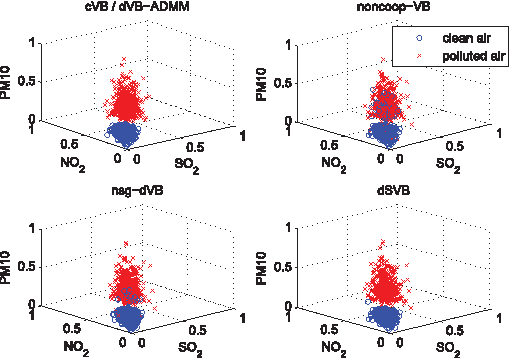

Distributed inference/estimation in Bayesian framework in the context of sensor networks has recently received much attention due to its broad applicability. The variational Bayesian (VB) algorithm is a technique for approximating intractable integrals arising in Bayesian inference. In this paper, we propose two novel distributed VB algorithms for general Bayesian inference problem, which can be applied to a very general class of conjugate-exponential models. In the first approach, the global natural parameters at each node are optimized using a stochastic natural gradient that utilizes the Riemannian geometry of the approximation space, followed by an information diffusion step for cooperation with the neighbors. In the second method, a constrained optimization formulation for distributed estimation is established in natural parameter space and solved by alternating direction method of multipliers (ADMM). An application of the distributed inference/estimation of a Bayesian Gaussian mixture model is then presented, to evaluate the effectiveness of the proposed algorithms. Simulations on both synthetic and real datasets demonstrate that the proposed algorithms have excellent performance, which are almost as good as the corresponding centralized VB algorithm relying on all data available in a fusion center.
Online Learning Algorithms for Quaternion ARMA Model
Apr 26, 2019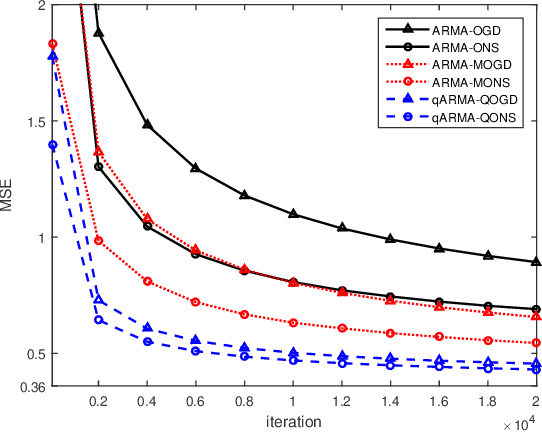
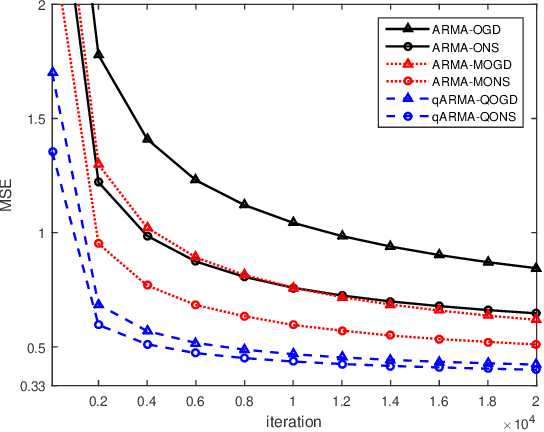
In this paper, we address the problem of adaptive learning for autoregressive moving average (ARMA) model in the quaternion domain. By transforming the original learning problem into a full information optimization task without explicit noise terms, and then solving the optimization problem using the gradient descent and the Newton analogues, we obtain two online learning algorithms for the quaternion ARMA. Furthermore, regret bound analysis accounting for the specific properties of quaternion algebra is presented, which proves that the performance of the online algorithms asymptotically approaches that of the best quaternion ARMA model in hindsight.
Distributed Variational Bayesian Algorithms for Extended Object Tracking
Mar 01, 2019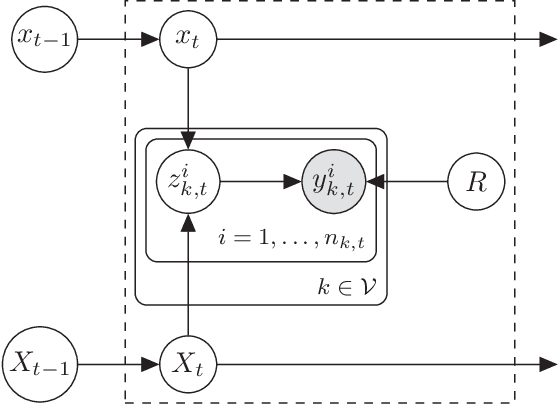
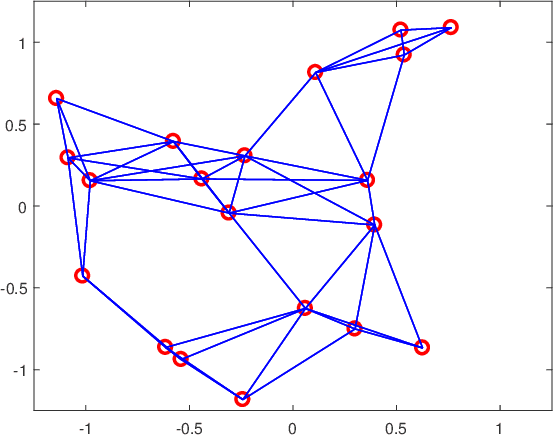
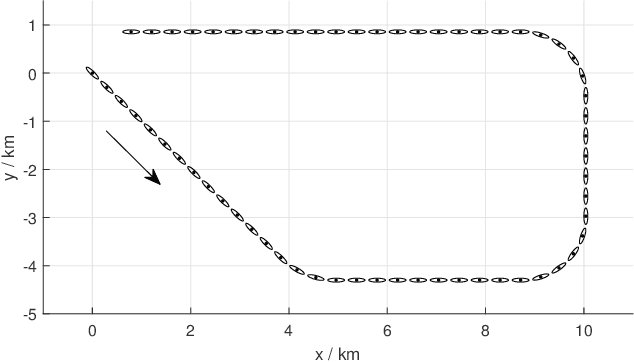
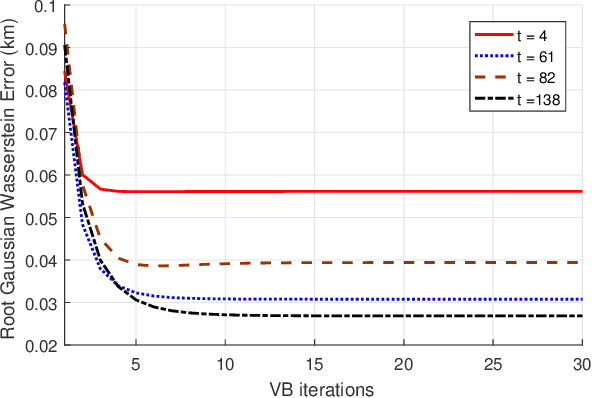
This paper is concerned with the problem of distributed extended object tracking, which aims to collaboratively estimate the state and extension of an object by a network of nodes. In traditional tracking applications, most approaches consider an object as a point source of measurements due to limited sensor resolution capabilities. Recently, some studies consider the extended objects, which are spatially structured, i.e., multiple resolution cells are occupied by an object. In this setting, multiple measurements are generated by each object per time step. In this paper, we present a Bayesian model for extended object tracking problem in a sensor network. In this model, the object extension is represented by a symmetric positive definite random matrix, and we assume that the measurement noise exists but is unknown. Using this Bayesian model, we first propose a novel centralized algorithm for extended object tracking based on variational Bayesian methods. Then, we extend it to the distributed scenario based on the alternating direction method of multipliers (ADMM) technique. The proposed algorithms can simultaneously estimate the extended object state (the kinematic state and extension) and the measurement noise covariance. Simulations on both extended object tracking and group target tracking are given to verify the effectiveness of the proposed model and algorithms.