 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Photo Source Identification based on Neural Enhanced Camera Fingerprint
Feb 18, 2023With the growing popularity of smartphone photography in recent years, web photos play an increasingly important role in all walks of life. Source camera identification of web photos aims to establish a reliable linkage from the captured images to their source cameras, and has a broad range of applications, such as image copyright protection, user authentication, investigated evidence verification, etc. This paper presents an innovative and practical source identification framework that employs neural-network enhanced sensor pattern noise to trace back web photos efficiently while ensuring security. Our proposed framework consists of three main stages: initial device fingerprint registration, fingerprint extraction and cryptographic connection establishment while taking photos, and connection verification between photos and source devices. By incorporating metric learning and frequency consistency into the deep network design, our proposed fingerprint extraction algorithm achieves state-of-the-art performance on modern smartphone photos for reliable source identification. Meanwhile, we also propose several optimization sub-modules to prevent fingerprint leakage and improve accuracy and efficiency. Finally for practical system design, two cryptographic schemes are introduced to reliably identify the correlation between registered fingerprint and verified photo fingerprint, i.e. fuzzy extractor and zero-knowledge proof (ZKP). The codes for fingerprint extraction network and benchmark dataset with modern smartphone cameras photos are all publicly available at https://github.com/PhotoNecf/PhotoNecf.
Sophisticated deep learning with on-chip optical diffractive tensor processing
Dec 20, 2022



The ever-growing deep learning technologies are making revolutionary changes for modern life. However, conventional computing architectures are designed to process sequential and digital programs, being extremely burdened with performing massive parallel and adaptive deep learning applications. Photonic integrated circuits provide an efficient approach to mitigate bandwidth limitations and power-wall brought by its electronic counterparts, showing great potential in ultrafast and energy-free high-performance computing. Here, we propose an optical computing architecture enabled by on-chip diffraction to implement convolutional acceleration, termed optical convolution unit (OCU). We demonstrate that any real-valued convolution kernels can be exploited by OCU with a prominent computational throughput boosting via the concept of structral re-parameterization. With OCU as the fundamental unit, we build an optical convolutional neural network (oCNN) to implement two popular deep learning tasks: classification and regression. For classification, Fashion-MNIST and CIFAR-4 datasets are tested with accuracy of 91.63% and 86.25%, respectively. For regression, we build an optical denoising convolutional neural network (oDnCNN) to handle Gaussian noise in gray scale images with noise level {\sigma} = 10, 15, 20, resulting clean images with average PSNR of 31.70dB, 29.39dB and 27.72dB, respectively. The proposed OCU presents remarkable performance of low energy consumption and high information density due to its fully passive nature and compact footprint, providing a highly parallel while lightweight solution for future computing architecture to handle high dimensional tensors in deep learning.
Passive Non-line-of-sight Imaging for Moving Targets with an Event Camera
Sep 27, 2022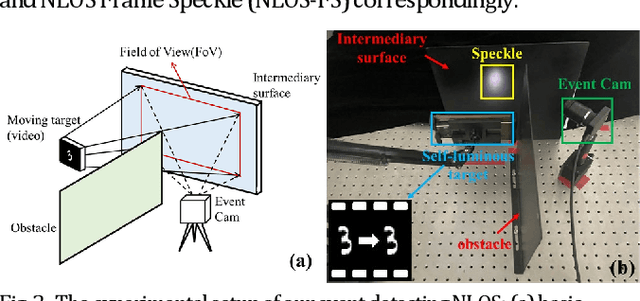



Non-line-of-sight (NLOS) imaging is an emerging technique for detecting objects behind obstacles or around corners. Recent studies on passive NLOS mainly focus on steady-state measurement and reconstruction methods, which show limitations in recognition of moving targets. To the best of our knowledge, we propose a novel event-based passive NLOS imaging method. We acquire asynchronous event-based data which contains detailed dynamic information of the NLOS target, and efficiently ease the degradation of speckle caused by movement. Besides, we create the first event-based NLOS imaging dataset, NLOS-ES, and the event-based feature is extracted by time-surface representation. We compare the reconstructions through event-based data with frame-based data. The event-based method performs well on PSNR and LPIPS, which is 20% and 10% better than frame-based method, while the data volume takes only 2% of traditional method.
Key frames assisted hybrid encoding for photorealistic compressive video sensing
Jul 26, 2022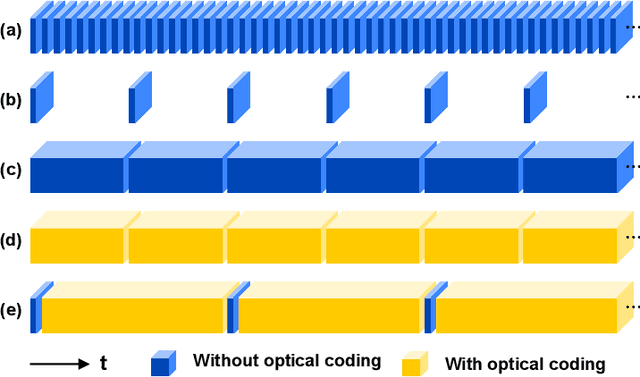
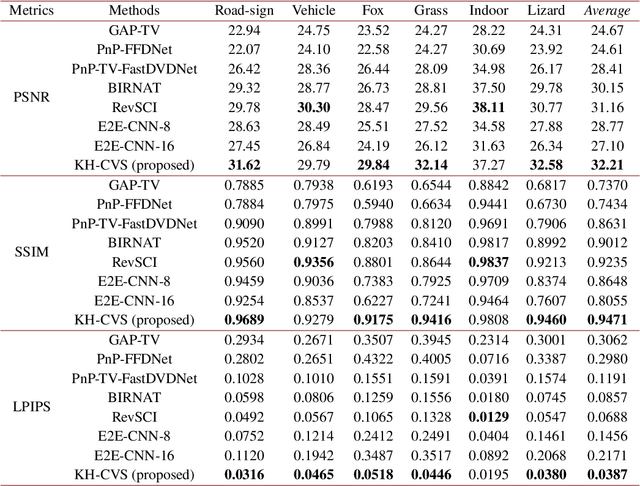
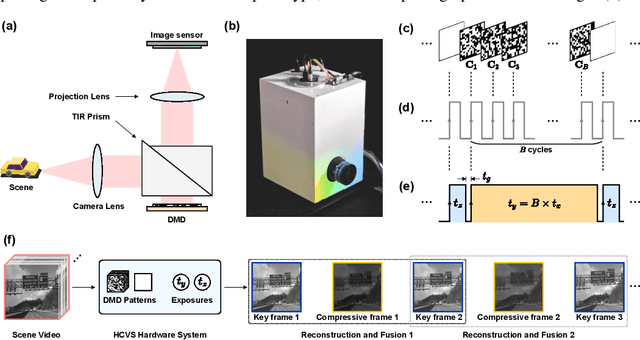
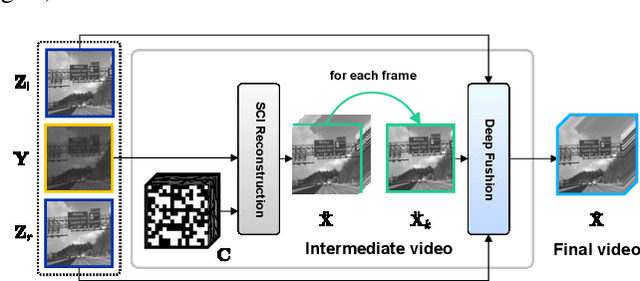
Snapshot compressive imaging (SCI) encodes high-speed scene video into a snapshot measurement and then computationally makes reconstructions, allowing for efficient high-dimensional data acquisition. Numerous algorithms, ranging from regularization-based optimization and deep learning, are being investigated to improve reconstruction quality, but they are still limited by the ill-posed and information-deficient nature of the standard SCI paradigm. To overcome these drawbacks, we propose a new key frames assisted hybrid encoding paradigm for compressive video sensing, termed KH-CVS, that alternatively captures short-exposure key frames without coding and long-exposure encoded compressive frames to jointly reconstruct photorealistic video. With the use of optical flow and spatial warping, a deep convolutional neural network framework is constructed to integrate the benefits of these two types of frames. Extensive experiments on both simulations and real data from the prototype we developed verify the superiority of the proposed method.