 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAR: A Video Dataset For Fine-grained Behaviors Recognition Oriented with Action and Environment Factors
Mar 26, 2025Behavior recognition is an important task in video representation learning. An essential aspect pertains to effective feature learning conducive to behavior recognition. Recently, researchers have started to study fine-grained behavior recognition, which provides similar behaviors and encourages the model to concern with more details of behaviors with effective features for distinction. However, previous fine-grained behaviors limited themselves to controlling partial information to be similar, leading to an unfair and not comprehensive evaluation of existing works. In this work, we develop a new video fine-grained behavior dataset, named BEAR, which provides fine-grained (i.e. similar) behaviors that uniquely focus on two primary factors defining behavior: Environment and Action. It includes two fine-grained behavior protocols including Fine-grained Behavior with Similar Environments and Fine-grained Behavior with Similar Actions as well as multiple sub-protocols as different scenarios. Furthermore, with this new dataset, we conduct multiple experiments with different behavior recognition models. Our research primarily explores the impact of input modality, a critical element in studying the environmental and action-based aspects of behavior recognition. Our experimental results yield intriguing insights that have substantial implications for further research endeavors.
Key frames assisted hybrid encoding for photorealistic compressive video sensing
Jul 26, 2022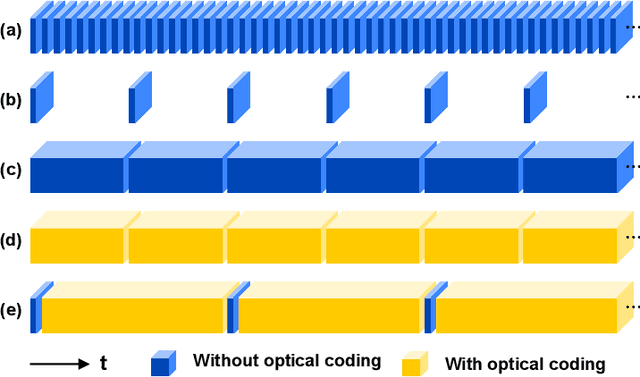
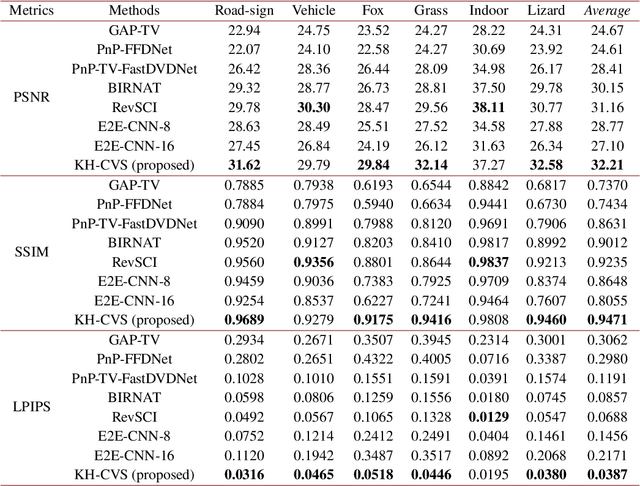
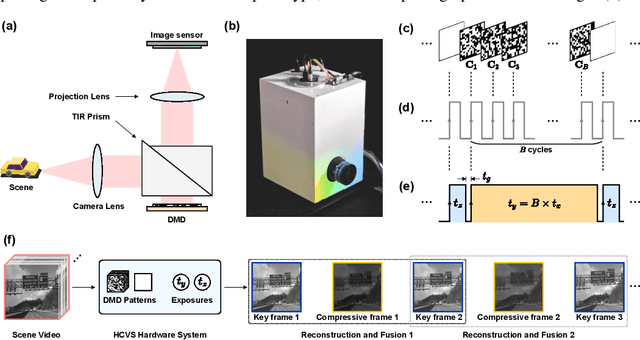
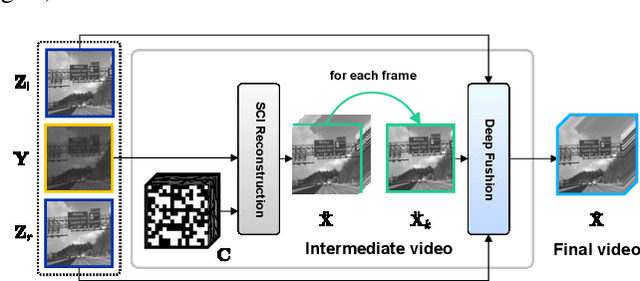
Snapshot compressive imaging (SCI) encodes high-speed scene video into a snapshot measurement and then computationally makes reconstructions, allowing for efficient high-dimensional data acquisition. Numerous algorithms, ranging from regularization-based optimization and deep learning, are being investigated to improve reconstruction quality, but they are still limited by the ill-posed and information-deficient nature of the standard SCI paradigm. To overcome these drawbacks, we propose a new key frames assisted hybrid encoding paradigm for compressive video sensing, termed KH-CVS, that alternatively captures short-exposure key frames without coding and long-exposure encoded compressive frames to jointly reconstruct photorealistic video. With the use of optical flow and spatial warping, a deep convolutional neural network framework is constructed to integrate the benefits of these two types of frames. Extensive experiments on both simulations and real data from the prototype we developed verify the superiority of the proposed method.